Algorithms, Geometry and Learning
A list of topics that were proposed during previous quarters.
Approximation Algorithms using Tree Embeddings
Many optimization problems can be solved efficiently on trees. A central algorithmic paradigm in approximation algorithms is to map the problem on a tree, solve it, and then quantify the loss that the tree approximation induces. Two general such problems are the 0-extension problem and its generalization, Metric Labeling problem.
Approximation Algorithms for Classification Problems with Pairwise Relationships: Metric Labeling and Markov Random Fields, J. Kleinber and E. Tardos, FOCS’99, JACM’02.
Approximation Algorithms for the Metric Labeling Problem via a New Linear Programming Formulation, Chekuri et al., SODA’01.
Approximation algorithms for the 0-extension problem, Calinescu et al., SICOMP 2005.
An improved approximation algorithm for the 0-extension problem, Fakcharoenphol et al., SODA’03.
Metric Clustering via Consistent Labeling, Robert Krauthgamer and Tim Roughgarden, SODA’08, ToC ’10.
Probabilistic Tree Decompositions
Starting with the seminal work of Bartal STOC ’98, it is now known that any finite metric space can be approximated by a distribution on trees such that all distances are preserved . Here we will review the technique and some recent improvements. This technique is a basic building block in metric embedings.
On approximating arbitrary metrices by tree metrics, Yair Bartal, STOC’98.
Approximating a Finite Metric by a Small Number of Tree Metrics, Charikar et al., FOCS’98.
A tight bound on approximating arbitrary metrics by tree metrics, J. Fakcharoenphol, S. Rao, K. Talwar, STOC’03, JCSS’04.
A New Efficient Construction on Probabilistic Tree Embeddings, G. E. Belloch et al., 2016.
Exponential Clocks Techniques
Geometric rounding: a dependent randomzied rounding scheme,D. Ge et al., J Comb. Opt.’11.
Simplex partitioning via exponential clocks and the multiway cut problem, N. Buchbinder et al, STOC’13.
Multiway cut, pairwise realizable distributions, and descending thresholds, Ankit Sharma and Jan Vondrak, STOC’14.
Dynamic Facility Location via Exponential ClocksH.C. An et al, SODA ’15.
Metric Embeddings and Negative Type Metrics
We will review a set of techniques that are important in obtaining metric embeddings of general metric spaces into Euclidean space: the Single Scale embedding and the (inter-scale) Gluing lemma. We then are going to consider a special class of metric spaces those of negative type, i.e. metrics 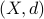 suchs that
suchs that 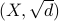 is an Euclidean metric. These spaces arise in the context of approximation algorithms through SDP relaxations, the prime example of which is Sparsest Cut problem. We present a structural theorem for these spaces (Core Theorem) first discovered by Arora, Rao, Vazirani (ARV). The presentation will be based on Distance Scales, Embeddings, and Metrics of Negative Type, by James R. Lee, 2006.
is an Euclidean metric. These spaces arise in the context of approximation algorithms through SDP relaxations, the prime example of which is Sparsest Cut problem. We present a structural theorem for these spaces (Core Theorem) first discovered by Arora, Rao, Vazirani (ARV). The presentation will be based on Distance Scales, Embeddings, and Metrics of Negative Type, by James R. Lee, 2006.
On distance scales, embeddings, and efficient relaxations of the cut cone, J.R. Lee, SODA’05.
Expander flows, geometric embeddings and graph partitioning, S. Arora, S. Rao, U. Vazirani, STOC’04.
Measured descent: A new embedding method for finite metrics, R. Krauthgamer et al, FOCS’04, GAFA’05.
Embeddings of Negative-type Metrics and An Improved Approximation to Generalized Sparsest Cut, S. Chawla, A. Gupta, H. Racke, SODA’05.
Generalized Sparsest Cut and Negative Type Metrics
The previous approach of embedding negative type spaces was based on three ingredients, the Single Scale Embedding, the (inter-scale) Gluing Lemma and the ARV Core theorem. Only the last of which used the special properties of negative type spaces. Arora, Lee and Naor devised an additional technique (intra-scale) Gluing Lemma that allowed them to improve on the previous results and provide the best known approximation ration for Generalized Sparsest cut.
Euclidean distortion and the Sparsest Cut, S. Arora, J.R. Lee, A. Naor, JAMS’08.
 -nets for finite metric spaces with applications.
-nets for finite metric spaces with applications.
In many applications, due to computational considerations we would like to have a concise representation of a metric space, such that all distances are approximately preserved. Such representations are typically called -nets. Here, we review algorithms that take a finite metric space and construct such nets. We will focus on general metric spaces of bounded doubling dimension and on doubling metrics induced by graphs. We also will discuss applications of such constructions in algorithm design.
Fast construction of nets in low-dimensional metrics and their applications, S. Har-Peled and Manor Mendel, SICOMP’06.
On Hierarchical Routing in Doubling Metrics, T.H.H. Chan et al., SODA’05.
Net and Prune: a Linear Time Algorithm for Euclidean Distance Problems, S. Har-Peled and B. Raichel, STOC’13, JACM’15.
Lipschitz Extensions, Classification and SVM's.
Distance-Based Classification with Lipschitz Functions, Ulrike von Luxburg and Olivier Bousquet, JMLR’04.
Maximal margin classification for metric spaces, M. Hein, O. Bousquet, B. Scholkopf, JCSS’05.
Classification in Metric Spaces
Random Projection Margins Kernels and Feature-Selection, Avrim Blum, Subspace, Latent Structure and Feature Selection 2005.
Efficient Classification for Metric Data, L.A. Gottlieb, A. Kontorovich, R. Krauthgamer, IEEE Transactions Information Theory 2014
Adaptive Metric Dimensionality Reduction, L.A. Gottlieb, A. Kontorovich, R. Krauthgamer, Theoretic Computer Science 2015.
Average Distortion Embeddings and Quantitative Trade-offs
Typically, in metric embeddings we concern ourselves with bounding the maximum distortion that we incure when we embed a metric space in 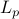 (usually for
(usually for 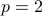 ). In this paper, a number of novel techniques are introduced: (hierarchically) uniformly padded partitions, partial and scaling embeddings, that allow one not only to get a bound on the maximum distortion but also to achieve constant average distortion. Applications in approximations algorithms and network embeddings (distance labeling schemes) are given.
). In this paper, a number of novel techniques are introduced: (hierarchically) uniformly padded partitions, partial and scaling embeddings, that allow one not only to get a bound on the maximum distortion but also to achieve constant average distortion. Applications in approximations algorithms and network embeddings (distance labeling schemes) are given.
Advances in metric embedding theory, I. Abraham, Y. Bartal, O. Neiman, FOCS’05, STOC’06, SODA’08, Adv. Math. 2011.
Random Feature Maps
Different characterizations (Bochners, Schoenbecks) for family of (Shift Invariant, Dot Product kernels) are used to define embeddings (random feature maps) of the Hilbert space such that dot products are preserved.
Random Features for Large-Scale Kernel Machines, A. Rahimi and B. Recht, NIPS’07.
Random Feature Maps for Dot Product Kernels, P. Kar and H. Karnick, ICML’12.
Spherical Random Features for Polynomial Kernels, J. Pennington et al., NIPS’15.
Optimal Rates for Random Fourier Features, B.K. Sriperumbudur and Z. Szabo, NIPS’15.
Random Maxout Features, Y. Mroueh et al., 2015.
Sketching (Polynomial) Kernels
Fast and Scalable Polynomial Kernels via Explicit Feature Maps, KDD’13.
Subspace Embeddings for the Polynomial Kernel, H. Avron et al., NIPS’14.
Provably Useful Kernel Matrix Approximation in Linear Time, Cameron Musco and Christopher Musco, 2016.
MinWise Hashing and Min-max Kernel
Improved Consistent Sampling, Weighted Minhash and L1 Sketching, Sergei Ioffe, ICDM’10.
Theory and Applications of b-Bit Minwise Hashing, Ping Li and Arnd C. Konig, WWW’10, CACM’11.
Is Min-Wise Hashing Optimal for Summarizing Set Intersection, R. Pagh et al., PODS’14.
Exact Weighted Minwise Hashing in Constant Time, Anshumali Shrivastava, 2016.
Generalized Min-Max Kernel and Generalized Consistent Weight Sampling, Ping Li, 2016.
Local Embeddings
In modern data analysis often practicioners care about the local structure of the metric space (e.g. k-nearest neighbors, manifolds) and implicitly assume that the euclidean space information about long distances is inaccurate. Here we review two works that get improved dimension/distortion bounds if we only care about preserving the local distances.
Dimensionality reduction: beyond the Johnson-Lindenstrauss bound, Y. Bartal, B. Recht, L. Schulman, SODA’11.
Local Embeddings of Metric Spaces, I. Abraham, Y. Bartal, O.Neiman, STOC’07, Algorithmica’15.
Ordinal Embeddings
Ordinal Embeddings of Minimum Relaxation: General Properties, Trees, and Ultrametrics, N. Alon et al., TALG’08.
Uniqueness of Ordinal Embedding, Matthaus Kleindessner and Ulrike von Luxburg, COLT’14.
Local Ordinal Embedding, Yoshikazu Terada and Ulrike von Luxburg, ICML’14.
Lens depth function and k-relative neighborhood graph: versatile tools for ordinal data analysis, Matthäus Kleindessner, Ulrike von Luxburg, 2016.
Locality Sensitive Filtering and Asymmetric LSH
Asymmetric Minwise Hashing, A. Shrivastava and P. Li, 2014.
New directions in nearest neighbor searching with applications to lattice sieving, A. Becker et al., SODA’16.
A Framework for Similarity Search with Space-Time Tradeoffs using Locality-Sensitive Filtering, Tobias Christiani, 2016.
Ultrametrics and Majorizing Measures
We have already seen how trees can be used to approximate metric spaces. In fact a more general statement is true, every compact metric space contains a large ultrametric skeleton. The flagship application of this theorem is that one can easily derive a deep theorem due to Talagrand and Fernique, Majorizing Measure Theorem.
Ultrametric Skeletons, Manor Mendel and Assaf Naor, PNAS’13.
Ultrametric subsets with large Hausdorff dimension, Manor Mendel and Assaf Naor, Ivent. math’13.
Chaining Arguments and their Applications.
Isometric sketching of any set via the Restricted Isometry Property, S. Oymak, B. Recht, M. Soltanolkotabi, 2015.
An improved analysis of the ER-SpUD dictionary learning algorithm, Jarosław Błasiok and Jelani Nelson, 2016.
Beating CountSketch for Heavy Hitters in Insertion Streams, V. Braverman et al., STOC’16.
Spanners and their Applications
Using Petal-Decompositions to Build a Low Stretch Spanning Tree, I. Abraham and O. Participants, STOC’12.
Cops, Robbers, and Threatening Skeletons: Padded Decomposition for Minor-Free Graphs, I. Abraham et al., STOC’14.
A light metric spanner, Lee-Ad Gottlieb, FOCS’15.
Near-Optimal Light Spanners, Shiri Chechik and Christian Wulff-Nilsen, SODA’16.
The Greedy Spanner is Existentially Optimal, Arnold Filtser and Shay Solomon, 2016.
PAC Learning
The Optimal Sample Complexity of PAC Learning, Steve Hanneke , JMLR 2016.
Learning Halfspaces
Complexity Theoretic Limitations on Learning Halfspaces, Amit Daniely, 2016.
A PTAS for Agnostically Learning Halfspaces, Amit Daniely, COLT 2015.
[https:arxiv.orgpdf1307.8371v7.pdf The power of localization for efficiently learning linear separators with noise, P. Awasthi, MF. Balcan, P.M. Long, STOC 2014.
Learning and 1-bit Compressed Sensing under Asymmetric Noise, P. Awasthi et al., COLT 2016.
Efficient Active Learning of Halfspaces: An Aggressive Approach, A Gonen, S Sabato, S Shalev-Shwartz, JMLR 2014.
Theory for Neural Networks
Distribution-Specific Hardness of Learning Neural Networks, O. Shamir, 2016.
No bad local minima: Data independent training error guarantees for multilayer neural networks, Daniel Soudry, Yair Carmon, 2016.
Deep Learning without Poor Local Minima, Kenji Kawaguchi, NIPS 2016.
Toward Deeper Understanding of Neural Networks: The Power of Initialization and a Dual View on Expressivity, Amit Daniely, Roy Frostig, Yoram Singer, 2016.
AdaNet: Adaptive Structural Learning of Artificial Neural Networks, C. Cortes et al., 2016.
Why are deep nets reversible: A simple theory, with implications for training, S. Arora, Y. Liang, T. Ma, ICLR 2016.
L1 -regularized Neural Networks are Improperly Learnable in Polynomial Time, Y. Zhang, J.D. Lee, M.I. Jordan, ICML 2016.
Learning Halfspaces and Neural Networks with Random Initialization, Y. Zhang, J. D. Lee, M. J. Wainwright, M. I. Jordan, 2015.
Beating the Perils of Non-Convexity: Guaranteed Training of Neural Networks using Tensor Methods, M. Janzamin et al. 2015.
Provable Bounds for Learning Some Deep Representations, S. Arora et al., ICML 2014.
Learning Polynomials with Neural Networks, A. Andoni, R. Panigrahy, G. Valiant, L. Zhang, IMCL 2014.
Nearest-Neighbors Estimators
Breaking the Bandwidth Barrier: Geometrical Adaptive Entropy Estimation, Weihao Gao, Sewoong Oh, Pramod Viswanath, 2016.
Active Nearest-Neighbor Learning in Metric Spaces, Aryeh Kontorovich, Sivan Sabato, Ruth Urner, 2016.
A New Look at Nearest Neighbours: Identifying Benign Input Geometries via Random Projections, A. Kaban, ACML 2015.
Near-optimal sample compression for nearest neighbors, Lee-Ad Gottlieb, Aryeh Kontorovich, Pinhas Nisnevitch, NIPS 2014.
Optimal rates for k-NN density and mode estimation, S Dasgupta, S Kpotufe, NIPS 2014.
Efficient Classification in Metric Spaces, LA. Gottlieb, A. Kontorovich, R. Krauthgamer, IEE Transaction on Information Theory 2014.
Maximum Margin Multiclass Nearest Neighbors, Aryeh Kontorovich, Roi Weiss, ICML 2014.
k-NN Regression Adapts to Local Intrinsic Dimension, Samory Kpotufe, NIPS 2011.
Tree Based Estimators
Statistical Inference for Cluster Trees, YC. Chen et al. 2016.
Hierarchical Label Queries with Data-Dependent Partitions, S. Kpotufe et al., COLT 2015,
Consistent Procedures for Cluster Tree Estimation and Pruning, K. Chaudhuri et al., IEEE Trans. Information Theory 2014.
A tree-based regressor that adapts to intrinsic dimension, S. Kpotufe, S. Dasgupta, JCSS 2012.
Agnostically Learning Decision Trees, P. Gopalan et al., STOC 2008.
Sample Compression Schemes
Labeled compression schemes for extremal classes, Shay Moran, Manfred K. Warmuth, 2015.
compression schemes for VC classes, Shay Moran, Amir Yehudayoff, 2015.
and compressing for low VC-dimension, Shay Moran, Amir Shpilka, Avi Wigderson, Amir Yehudayoff, STOC 2015.
Recursive Teaching Dimension, VC-Dimension and Sample Compression, T. Doliwa et al, JMLR 2014.
A Geometric Approach to Sample Compression, B. Rubinstein, J.Hyam Rubinsteinm, JMLR 2012.
Local Dimensionality Reduction
Dimensionality Reduction: beyond the Johnson-Lindenstrauss bound, Y. Bartal, B. Recht, L.J. Schulman, SODA 2011
Local Embeddings of Metric Spaces by I. Abraham, Y. Bartal, O. Neiman, Algorithmica 2015.
Dimension Reduction Techniques for lp, with Applications, Y. Bartal and Lee-Ad Gottlieb, SoCG 2016.
Dimensionality Reduction for Classification
Kernels as features: On kernels, margins, and low-dimensional mappings, MF. Balcan, A. Blum, S. Vempala, Machine Learning 2006.
Generalization Bounds for Supervised Dimensionality Reduction, M. Mohri et al. 2015.
Adaptive metric dimensionality reduction by LA. Gottlieb, A. Kontorovich, R. Krauthgamer.
Lipschitz Extensions
Distance-Based Classification with Lipschitz Functions, U von Luxburg, O. Bousquet, JMLR 2004.
Extending Lipschitz functions via random metric partitions, J.R. Lee, A. Naor, Inventiones mathematicae 2005.
Algorithms for Lipschitz Learning on Graphs, R. Kyng et al., COLT 2015.