Assignment 1: Amazon Reviews Search
Due date: Wednesday, January 15th, midnight
No late days can be used for this assignment
Learning Goals
This assignment focuses on exercising your C and C++ skills. You will be building your skills with:
- using C pointer operations to access data in different binary data files
- use a mix of C and C++ to model binary data in C++ objects
- become familiar with the C++ "Standard Template Library" (STL) classes, in particular
vector,setandtuple, and STL built-in functions such aslower_bound
Getting the Starter Code
To get started on the assignment, clone the starter project using the command
git clone /usr/class/cs110/repos/assign1/$USER assign1
This line creates a new folder called assign1 in your current working directory containing a copy of the starter code. git is the name of the source control framework we use to keep track of your changes and minimize the chances you lose any of your work.
The starter project contains the following:
amazon.hamazon.cc,Makefile: two files that you modify, and their Makefile for compilingdbase_test.cc: A provided program that calls upon youramazonclass, for testing purposes. It prints out a review stored at the given index indatabaseFile. You do not need to modify this file.amazon_search.cc: A provided program that calls upon youramazonclass, for testing purposes. It prints out reviews that match an entered query, in different sorting orders. You do not need to modify this file.samples: a symbolic link to the shared directory for this assignment. It contains:SANITY.iniandsanity.py: files to configure and run Sanity Check. You can ignore these.amazon_search_solnanddbase_test_soln: executable solutions for the provided test programs that are built with the solutionamazonclass. Use these programs to verify correct behavior for these programs. These programs are also used by sanity check to validate your program behavior.sample_us.binandsample_us_keyword_index.bin: binary data files for a small test dataset of reviewsamazon_reviews_us_Major_Appliances_v1_00.binandamazon_reviews_us_Major_Appliances_v1_00_keyword_index.bin: binary data files for the medium-size appliances reviews datasetamazon_reviews_us_Electronics_v1_00.binandamazon_reviews_us_Electronics_v1_00_keyword_index.bin: binary data files for the large Electronics reviews dataset
tools: contains symbolic links to thesanitycheckandsubmitprograms for testing and submitting your work.
To compile your programs, type make. This will create both amazon_search and dbase_test. You should not make any changes to any files other than amazon.h and amazon.cc, although you are free to look through both files to see how we used some STL classes.
Overview
Question: How many times does "supercalifragilisticexpialidocious" appear in an Amazon review on electronics products between the years 1999 and 2015?
Answer: Three times in two different reviews.
Question: Does the phrase "Stanford you will never live this down" appear in an Amazon review?
Answer: Indeed, it does.
We are living in a world of large datasets. Some of those datasets have been published online, and in this assignment, you will be writing an efficient search algorithm to find words and phrases in a large dataset of Amazon reviews.
Amazon.com has one of the most extensive user review databases in the world. Anyone can review a product, and good product reviews can drive sales up, while poor reviews can drive sales down. If you have ever purchased something from Amazon, you have very likely checked out the reviews before buying.
The goal for this assignment is to implement functionality in the amazon class, described in amazon.h and amazon.cc, to extract data efficiently from binary data files storing Amazon review information, and search through this information to find matches to various user-entered keyword queries. This class is used by two programs we provide fully implemented, dbase_test and amazon_search, which let you pull up individual reviews by index, and search for keywords within reviews, respectively.
dbase_test lets you print out the contents of a review by index number:
$ samples/dbase_test_soln
No index found. Going into interactive mode
Total number of reviews: 3093869
Please enter an index (<enter> to end): 1234567
Getting review at index 1234567
Product title: SOUL Electronics SH9BLK High-Def Sound Isolation In-Ear
Headphones - Black - Discountinued by Manufacter
Product category: Electronics
Star rating: 5 stars
Review headline: Very Impressed.
Review body: Very impressed. Mic and remote works perfectly with my Nexus 5. Sound is great.
Comfort is alright.
Date: 2014-7-31
Please enter an index (<enter> to end): 77777
Getting review at index 77777
Product title: 1byone Amplified HDTV Antenna, with Detachable Amplifier Signal
Booster for the Highest Performance and 10 Feet Coaxial Cable-Black
Product category: Electronics
Star rating: 3 stars
Review headline: Works ok but still get buffering in bad weather but that is to be expected
Review body: Bought it to use when satellite dish lost signal. Works ok but
still get buffering in bad weather but that is to be expected. Otherwise ok.
<br />Not permantly mounted anywhere.
Date: 2015-8-8
Please enter an index (<enter> to end):
amazon_search lets you search for different keyword combinations within the reviews:
$ samples/amazon_search_soln
No search string found. Going into interactive mode
Total number of keywords: 483621
Please enter a search query (<enter> to end): supercalifragilisticexpialidocious
Found 2 matching reviews out of 3093869 reviews in the database.
Press <enter> to see the first five reviews.
**********
Review index: 2914008
Product title: High Speed HDMI Cable (1.5 Feet) With Ethernet - CL3 Certified - Supports 3D and Audio Return Channel, 1-Pack
Product category: Electronics
Star rating: 5 stars
Review headline: Cheap price, great cable!
Review body: This cable works great! Don't be fooled by the price. I'm currently using it with my Playstation 3 and switch to use with my XBOX 360 too. No need to spend the $20 to $100 that some retailers charge for a six foot cable. I have an LG 720p HDTV and there are no picture or sound problems. I was skeptical at first in purchasing a low price cable but I figured I'd take the chance and because I read the other reviews and most were positive. As one reviewer said, no need to buy, gold plated, loud named, cutting edge space age technology, supercalifragilisticexpialidocious, blah, blah, blah, cable. You won't be disappointed!
Date: 2008-5-18
**********
**********
Review index: 1329056
Product title: GPX C502B AM/FM Clock Radio with Dual Alarms - Black (Discontinued by Manufacturer)
Product category: Electronics
Star rating: 5 stars
Review headline: AWESOME CLOCK
Review body: IT WORK Supercalifragilisticexpialidocious I USE IT TO WAKE UP EVERY DAY THAT I HAVE TO WORK HAS 2 ALARMS AND YOU CAN DIM THE DISPLAY IT IS VERY Supercalifragilisticexpialidocious
Date: 2014-6-21
**********
Please enter a search query (<enter> to end): "Stanford you will never live this down"
Found 1 matching reviews out of 3093869 reviews in the database.
Press <enter> to see the first five reviews.
**********
Review index: 1881119
Product title: RCA ANT111Z Durable FM Antenna, Rabbit Ears
Product category: Electronics
Star rating: 4 stars
Review headline: Bought for a friend
Review body: OK so the smartest man I know couldn't figure out how to put it into his TV and it's as simple as screwing the cord into the place it belongs. It took me about 2 seconds to install it after he spent about 30 minutes trying to figure it out. STANFORD YOU WILL NEVER LIVE THIS DOWN :)
Date: 2013-7-28
**********
Please enter a search query (<enter> to end):
If you run these programs without any command-line arguments, they will each enter "interactive" mode where they will prompt you to enter relevant input. However, both of the provided programs also expose functionality via command-line arguments, which can be seen by running them with the -h flag:
$ samples/dbase_test_soln -h
Usage: samples/dbase_test_soln <option(s)> index Options:
-h,--help Show this help message
-d,--directory DIRECTORY Specify the directory for the database files
-f,--files-prefix FILE_PREFIX Specify the files prefix (default is 'amazon_reviews_us_Electronics_v1_00')
$ samples/amazon_search_soln -h
Usage: samples/amazon_search_soln <option(s)> 'search string' Options:
-h,--help Show this help message
-k,--primary-key Primary key, one of: date, stars, bodysize, title (default is date)
-r,--reversed Reverse ordering for primary key
-n,--number-of-reviews Number of reviews to show (default is to show all reviews)
-d,--directory DIRECTORY Specify the directory for the database files
-f,--files-prefix FILE_PREFIX Specify the files prefix (default is 'amazon_reviews_us_Electronics_v1_00')
Here is an example of running each of the provided test programs using command-line arguments instead of in interactive mode.
Display the review at index 14 in the sample_us dataset:
$ samples/dbase_test_soln -f sample_us 14
Total number of reviews: 49
Getting review at index 14
Product title: Team Losi 8IGHT-E RTR AVC Electric 4WD Buggy Vehicle (1/8 Scale)
Product category: Toys
Star rating: 3 stars
Review headline: ... servo so expect to spend 150 more on a good servo
immediately be the stock one breaks right
Review body: Comes w a 15$ servo so expect to spend 150 more on a good servo
immediately be the stock one breaks right away
Date: 2015-8-31
Display at most the top 3 reviews in the sample_us dataset that match the query like it (both words, anywhere in a review), sorted in ascending order with star rating as the primary sorting key:
$ samples/amazon_search_soln -f sample_us -k stars -r -n 3 'like it'
Total number of keywords: 896
Found 4 matching reviews out of 49 reviews in the database.
**********
Review index: 23
Product title: Lalaloopsy Girls Basic Doll- Prairie Dusty Trails
Product category: Toys
Star rating: 4 stars
Review headline: i like it but i absoloutely hate that some dolls don't ...
Review body: i like it but i absoloutely hate that some dolls don't have pets like this one so I'm not stoked and i really would have liked to see her pet
Date: 2015-8-31
**********
**********
Review index: 8
Product title: Fisher-Price Octonauts Shellington's On-The-Go Pod Toy
Product category: Toys
Star rating: 5 stars
Review headline: Five Stars
Review body: Children like it
Date: 2015-8-31
**********
**********
Review index: 33
Product title: Paraboard - Parallel Charging Board for Lipos with EC5 Connectors
Product category: Toys
Star rating: 5 stars
Review headline: CAN SAVE TME IF YOU UNDESTAND HOW IT WORKS .
Review body: Works well ,quality product but this style of board will charge multiple batteries at the same time SAFELY ( IF ) ALL BATTERIES ARE OF THE SAME CELL COUNT , THE SAME BATTERY COMPOSITION ( LIPO, NIMH-etc ) AND THEY MUST HAVE INDIVIDUAL CELL VOLTAGES THAT ARE VERY CLOSE AND EQUAL TO EACH BATTERY CONNECTED AT THE SAME TIME . When board is connected to most if not all chargers it can only read total and individual cell voltage of ONE OF THE BATTERIES AND MAY OVER OR UNDER CHARGE THE OTHERS TO SOME DEGREE , TOTAL RATE OF CHARGE IS DIVIDED EQUALLY BETWEEN BATTERIES CONNECTED AT THE SAME TIME . Close monitoring is a must when using like all high discharge batteies . I have only personally expeienced one lipo battery meltdown and it is a very SHORT IF NOT NON EXISTANT WINDOW OF OPPERUNITY TO PREVENT OR MINIMISE THE COLATTERAL DAMAGE ONCE THE PROCESS STARTS . Read and understand all charging and battery instructions .
Date: 2015-8-31
**********
The logic in the amazon class is a core part of how these programs work - that is your task for this assignment.
Note on command-line arguments
String arguments on the command line can be tricky. Make sure that you enclose any search terms in single quotes, and search phrases in double quotes within the single quotes. So, for example, if you want to search for
incredible "ear buds"
You would enclose the entire query in single quotes:
samples/amazon_search_soln 'incredible "ear buds"'
In interactive mode, you can leave off the single quotes. You would search for drones "bit tricky" on the command line as follows:
samples/amazon_search_soln -d samples -f sample_us -k stars -r -n 3 'drones "bit tricky"'
but in interactive mode like this:
$ samples/amazon_search_soln -d samples -f sample_us -k stars -r -n 3
No search string found. Going into interactive mode
Total number of keywords: 896
Please enter a search query (<enter> to end): drones "bit tricky"
Found 1 matching reviews out of 49 reviews in the database.
...
Before moving on, try running the provided solutions (in the samples folder) to better understand the aforementioned functionality and how these programs work. Consider the following questions to verify your understanding before moving on (do not submit answers):
- How would you display the top 5 reviews that match the query
"beautiful world", sorted in descending order with star rating as the primary sorting key? - How would you view data for the review at index 34 in the
sample_usdataset in interactive mode? Via command-line arguments?
Dataset
Amazon has a good review search engine for particular products, but they don't allow searching through the entire database for whatever you want to find. However, they have published a database of all reviews from 1999 to 2015, which you can find here: https://s3.amazonaws.com/amazon-reviews-pds/tsv/index.txt.
The files are enormous, and there are over forty different files making up the various review categories. We will be relying on modified versions of three different files: a very small sample file, a medium sized Major Appliances file, and the very large Electronics file.
The files linked above are in tab separated format and are in plain text. Each line in the file (ending with a newline) is a different review, with each of the fifteen fields separated by a tab character. This makes them easy to read, but does not make fast searching easy, unless they are completely read into memory. Unfortunately, the electronics file is a robust 1.7GB file, and reading it completely into memory on a shared system (like a myth machine) would be problematic. With CS 110's enrollment, the myth machines would be significantly taxed if each student was trying to read in the entire file. Even if we did read in the files, we would still want to process them into a format that can be easily searched, and this would take even more memory.
So, we have two problems to solve:
- We don't want to read an entire database file into memory.
- We want to be able to search the database efficiently.
To solve the first problem, we have converted the database files into a binary format that contains data for each review. This file contains the data for each review one after the other, preceded with an array of offsets at the very start of the file to let you quickly jump to a certain review (see below for details of the format). So instead of reading every line to find the newline and to go to the next review, this format allows O(1) access for each review, assuming you know the index of the review you want to go to. We then access the file using memory mapped file access, which has three critical features:
- Only the part of the file that you want to access is read from the disk.
- Multiple users accessing the same file at the same position are able to access the same location in memory (using virtual memory, which we will cover in class). This means that this part of the file only needs to be read from disk once and is shared.
- Accessing the data is a matter of pointer arithmetic, assuming you know the format of the file (which we give you below).
The second problem is somewhat more challenging. Have you ever wondered how search engines find phrases in a database? It is untenable to keep indexes to each substring, of course, but it is possible to create an index to each word, and at each store the locations in the text where that word is found. Then, when searching for a phrase, each individual word can be looked up, and as long as the words come one-after-the-other in the file, then we know we have found the phrase. For this reason, for each dataset (sample, major appliances and electronics) we have created not one, but two binary data files. The first stores information for each review. The second contains data for each unique word, which is a list of all its occurrences throughout all the reviews; this makes it easy to do keyword search. The keywords are in sorted order, meaning that we can perform a binary search to find a particular word, and this word is followed by an array with the locations of this word across all reviews, and which particular field that word was in for each occurrence (product_title, product_category, review_headline, review_body). We have again, of course, created this file in a binary format that can be easily memory-mapped.
Binary File Format
As mentioned above, each original Amazon database file was converted to two files. The first, the "database file", stores a list of reviews, each containing information about that review. The second, the "keyword index file", stores a list of keywords, each with a list of all of the places where that keyword appears across all reviews. These files are laid out using a similar structure but are used for different things. The database file is useful to get information about a specific review. The keyword index file is useful to search for specific words within reviews.
The Database File
We want a way to be able to jump to a specific review in O(1) time. For this reason, the file data starts with a 4-byte unsigned int that gives the number of reviews, immediately followed by that many 4-byte unsigned ints, each of which represents the offset into a portion further in this file where a review is located. You might wonder why we need offsets, and why we don't reserve the same number of bytes for each review so that we can directly access them. The problem with that is that some reviews are only a few words, while other reviews go on for hundreds of words. Thus, if we tried to shoehorn each review into a fixed number of bytes, we would end up wasting a great deal of space in our file, or we would have to truncate reviews, neither of which we want to do.
The diagram below shows the basic layout of a databaseFile that contains three reviews.

The file is laid out as follows:
- The first four bytes of the file contain an unsigned integer that gives the number of reviews. Let's call this number
n. - The next
n * 4bytes contain a series ofn4-byte unsigned integers that each contain an offset to a review, in bytes, from the beginning of this file. - After the offsets, the reviews themselves start. The reviews continue to the end of the file.
A review is laid out as follows:
- A null-terminated c-string with the product title
- A null-terminated c-string with the product category
- A 1-byte char for the star rating
- A null-terminated c-string with the review headline
- A null-terminated c-string with the review body
- A potential extra null terminator if the number of bytes until this point is odd. This is to align the next value
- A 2-byte unsigned short for the year of the review
- A 1-byte char for the month of the review
- A 1-byte char for the day of the review
Keyword Index File
We also want a way to be able to quickly access where a word appears in review text. For this reason, this file's data starts with a 4-byte unsigned int that gives the number of keywords, immediately followed by that many 4-byte unsigned ints, each of which represents the offset into a portion further in this file where a keyword's information is located. Like with reviews, data for a single keyword may be any size, so it's not practical to set keyword data to a fixed size to iterate over - byte offsets are a good alternative.
The diagram below shows the basic layout of a keywordIndexFile that contains three keywords.
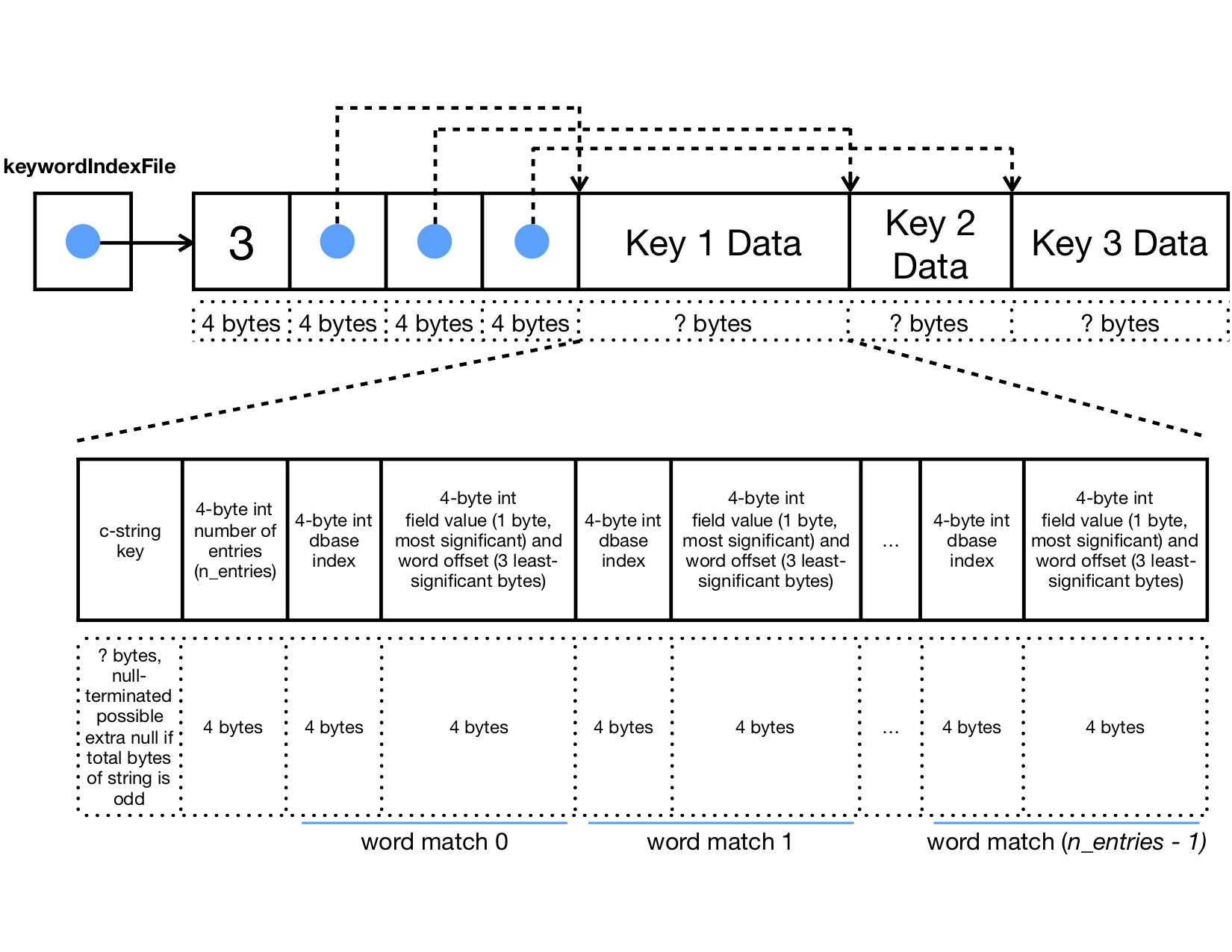
The file is laid out as follows:
- The first four bytes of the file contain an unsigned integer that gives the number of keywords. Let's call this number
n. - The next
n * 4bytes contain a series ofn4-byte unsigned integers that each contain an offset to a keyword data element, in bytes, from the beginning of this file. - After the offsets, the keyword data starts. The keyword data continues to the end of the file.
A keyword data entry is laid out as follows:
- A null-terminated c-string with the keyword
- A potential extra null terminator if the number of bytes until this point is odd. This is to align the next value
- A 4-byte unsigned integer for the number of times the word is found in the database. Let's call this number
n_entries - The next
n_entries * 8bytes contain a series ofn_entries8-byte blocks that each contain information about one occurrence of this keyword in the review data. Each of these 8-byte blocks is structured as follows:- A 4-byte unsigned int that identifies the review in
databaseFilewhere this word appears. Specifically, it is the index in thedatabaseFile's offset array where you can find the offset for the review. In other words, if this number is 4, this means that you would go to the index-4 element in the offset array at the start ofdatabaseFileto find the review's offset from the start ofdatabaseFile. - A 4-byte value representing where in the review specifically the keyword was found. This value is a combination of two pieces:
- The most significant byte stores an unsigned number indicating in what portion of this review the keyword appeared (0 = title, 1 = category, 2 = review headline, 3 = review body)
- The remaining 3 least-significant bytes store an unsigned number indicating the index at which this word appears in the specified field. In other words, if this value is 12 and the most significant byte value is 2, this means that the index-12 word of the review's headline was this keyword.
- A 4-byte unsigned int that identifies the review in
The keyword data entries in keywordIndexFile are in alphabetic order by keyword, meaning that you can perform a binary search to locate a particular word. For efficiency when searching for keywords, you must use the STL lower_bound function to perform a binary search, along with C++ lambdas (also known as anonymous functions with capture clauses) to provide nameless comparison functions that lower_bound can use to guide its search.
Assignment Code Structure
The code you write will be contained in the amazon.h and amazon.cc files. There, you will implement logic to search through the aforementioned data files in different ways. here is a reduced interface for the amazon class (taken from amazon.h):
class amazon {
public:
amazon(const std::string& directory, const std::string &filesPrefix);
bool good() const;
bool searchKeywordIndex(const std::string& query,
std::vector<int> &reviewIndexes) const;
bool getReview(unsigned int index, Review &review) const;
void getSortedReviewsFromIndexes(const std::vector<int> &reviewIndexes,
std::vector<Review> &reviews,
std::function<bool(const Review &, const Review &)> cmp) const;
unsigned int totalKeywords() const { return *(unsigned int *)keywordIndexFile; }
unsigned int totalReviews() const { return *(unsigned int *)databaseFile; }
~amazon();
private:
const void *databaseFile;
const void *keywordIndexFile;
};
The constructor and destructor have been written for you, as have the good(), totalKeywords(), and totalReviews() methods. The constructor initializes the databaseFile and keywordIndexFile as memory mapped files using the mmap function. What this means practically is that you can treat the two files as pointers to memory, with the files' contents accessible by pointer arithmetic. You will have to use your CS 107 skills to access the various fields in the files as outlined above using proper casting. By crawling over the files, you will have fast access to the data, which would not be possible if you had to read in the entire files and search for newlines, etc.
You will implement the getReview, getSortedReviewsFromIndexes and searchKeywordIndex methods, described in more detail below.
One helpful struct defined for you is Review, which is a C++ structure to encapsulate all the information in a single review. This is used in several of the methods listed above. Here is its definition (also taken from amazon.h):
struct Review {
unsigned int index;
std::string product_title;
std::string product_category;
int star_rating;
std::string review_headline;
std::string review_body;
int review_year;
int review_month;
int review_day;
friend std::ostream& operator<<(std::ostream& os, const Review& review);
};
Implementing The Required Functions
We recommend you implement the three required functions in the following order:
getReview
This is the only method required to complete the implementation of dbase_test. It is a good warm-up for accessing the database files, and once you have completed this method the provided dbase_test program will be fully functional, which you can use to test it. It should be a short function (our implementation is roughly 25 lines of code). The method takes in an index of a review in the databaseFile's offset table and populates the review passed by reference with its information.
getSortedReviewsFromIndexes
This method and the next (searchKeywordIndex) must both be implemented to complete the implementation of amazon_search. amazon_search uses searchKeywordIndex (below) to find matching reviews for the keyword search, and then this method to sort them in the correct order. You should implement this method first so that your output from searchKeywordIndex below is outputted. This is another short method (our solution is less than ten lines of code). Given a vector of integer indexes, where each index is an index in the databaseFile's offset table, this method extracts the reviews (using the getReview method) and populates a vector from them. Then, it sorts this vector based on the comparison function parameter. To test this function, we suggest hardcoding an implementation of searchKeywordIndex (below) to always populate the vector with a few reviews. Then, check the output to confirm these reviews are printed in the correct order based on how amazon_search is told to sort them. (hint: check out the primary-key and reversed command-line flags for amazon_search).
searchKeywordIndex
This method is the final method that must be implemented to complete the implementation of amazon_search. This is the most challenging part of the assignment. The purpose of the method is to search through keywordIndexFile based on a search query and populate a vector with the indexes in the databasesFile's offset table for reviews that match the query. A query is a string that contains one or more terms. A term could be something like incredible ear buds, which is intended to search for reviews that contain the words incredible, ear and buds somewhere (not necessarily in order) in some field (not necessarily the same one). If a term is contained within double quotes, this means the words must appear consecutively. In other words, the term "incredible ear buds" is intended to search for reviews that contain the exact in-order phrase incredible ear buds in a single field. Note that punctuation is ignored, so the term "incredible ear-buds" is treated the same as "incredible ear buds".
A query may contain more than one term. For example, the query incredible "ear buds" has two terms: incredible and "ear buds". The intent of a multiple term query is to find all reviews that match all its terms. In other words, this query is intended to search for reviews that contain the word incredible in one of its fields, AND also contain the exact in-order phrase ear buds in a single field (not necessarily the same one as for incredible).
To get you started, in amazon.cc we have provided a helper function called convertQuery, with the following signature:
vector<vector<string>> convertQuery(string query)
This function accepts a query string (such as incredible ear buds or incredible "ear buds"), removes any punctuation, and breaks it into individual terms, where each term is represented as an STL C++ vector of words. Because there may be multiple terms, this function returns a vector of terms, thus a vector of vector<string>. As an example, if you passed as a parameter the string incredible "ear buds" to this function, it would return a vector containing two elements. The first element would be a vector of length 1 containing the word incredible. The second element would be a vector of length 2 with its first element being ear and its second element being buds. From here, you can find matches for each individual term, and then find reviews that match all of these terms. In other words, searchKeywordIndex should first search keywordIndexFile for incredible, then search for the phrase ear buds, and finally AND the resulting matches together. Keep in mind that for a term in double quotes, you must search for each individual word (e.g. ear then buds) and then ensure that they come in order in a single field in a single review. To do this, you should use the word offset included as part of the match data for each keyword.
Remember, you must use the lower_bound function and a C++ lambda function to perform a binary search to find keywords.
To help visualize the query structure, the starter code for searchKeywordIndex already calls convertQuery and prints out a text description of how it has broken down the query string. Specifically, it prints out each term on its own line, with the text "AND" in between them to indicate that this query is searching for reviews that match all the terms. For example, here is the output of this provided code for the query incredible "ear buds" (what you get when running the starter code with no modifications):
$ ./amazon_search
No search string found. Going into interactive mode
Total number of keywords: 483621
Please enter a search query (<enter> to end): incredible "ear buds"
Search terms:
'incredible'
AND
'ear buds'
Could not find any matches for query 'incredible "ear buds"'
Please enter a search query (<enter> to end):
The recommended approach for this implementation is to break down the problem into two parts: first, finding matches for a single term; then, AND the resulting matches together to find reviews that match all of the terms. You will find both the STL set and the STD tuple (a grouping of multiple elements) useful as well as the std::set_intersection function. There is a good example of how to use this function here. Take some time to also think about how you can use these data structures to model the information for a single keyword's data. When approaching how to find matches for a single term, think about how you can create a group of candidate reviews that satisfy the term so far, and shrink this group down as you process the term until you are left with just reviews that satisfy the entire term.
You should make sure to decompose the problem, breaking down your logic into smaller functions that minimize redundancy, each of which accomplishes a single discrete task.
Testing and Debugging
Compile often, test incrementally and almost as often as you blink, and run tools/submit when you’re done (we will accept the last submission before the deadline, so submit as often as you’d like). As you make progress, you can invoke tools/sanitycheck to commit local changes and run a collection of tests that compare your solution to the provided sample solutions in the samples folder. You can also run these sample solutions on their own at any time. And be sure your solutions are free of memory leaks and errors, since we'll be running your code through valgrind.
Note: there's a bug in valgrind itself that surfaces when virtually any C++ program is run through it. You can suppress this error by copying the /usr/class/cs110/tools/config/.valgrindrc file into your home directory (or copying its contents into an existing ~/.valgrindrc file):
$ more /usr/class/cs110/tools/config/.valgrindrc
--memcheck:leak-check=full
--show-reachable=yes
--suppressions=/usr/class/cs110/tools/config/cs110.supp
$ cp /usr/class/cs110/tools/config/.valgrindrc ~
Helpful Hints
-
Keep in mind that all of the numerical values stored in the data files are unsigned (e.g. the offsets, counts, date fields, etc.). This will be important for some of the large files you have to analyze where the values may not fit in the signed equivalent.
-
Debugging this assignment can be difficult -- we suggest that you test on the small sample database in your tests. To do this, use the
-f sample_uscommand line argument, e.g.,
cgregg@myth60$ ./dbase_test -f sample_us
cgregg@myth60$ ./amazon_search -f sample_us
-
Our CS106B and CS106X classes rely on a collection of C++ libraries that aren't generally available outside of Stanford. We want you to code in standard C++ instead of the Stanford dialect of it, so you'll need to teach yourself some of the C++ that CS106B/X circumvented. In particular, the CS106
VectorandSettemplates are not available, and you'll instead need to teach yourself the standardvectorandsetclasses that ship with all C++ compilers. You may want to visit (or bookmark) the landing page of an excellent online C++ documentation site. In particular, pay attention to the documentation forvector,set, andlower_bound. -
To add to the previous note: although the strings in the review database are necessarily C-strings, you should strive to convert them to C++ strings whenever possible. You can create a C++ string from a C string as follows:
// assume name_cstr points to a C-string
string name = name_cstr;
-
You should rely on our sanitycheck tool-again, invoked via
tools/sanitycheck- to confirm that your solution matches the sample solution for a small suite of test cases. As it turns out, the tests exposed via sanitycheck are precisely the same tests we use when grading, so if you pass sanitycheck, then this means you will receive 100% on functionality. We won't always expose all of the tests like we are on Assignment 1, but this time we are. Note that assignments that are hardcoded explicitly to pass the provided tests will not receive credit. -
If you need a tutorial on how valgrind works, you can leverage the documentation written for CS107. A full treatise on what valgrind is and what it can do for you can be found right here. More generic documentation on how to test with valgrind can be found right here.
Icons by Piotr Kwiatkowski