This document serves as an appendix to the class discussion list from CS379C taught in the Spring of 2020. Due to the disruption caused by the SARS-CoV-2 outbreak and ensuing pandemic, it was decided that students would not be required to produce a final project including working code. In the last few classes, we discussed possible coding projects that would demonstrate some of the more ambitious ideas we explored during the quarter, and, as an exercise, fleshed out a project related to what we had been calling the SIR task borrowing from O'Reilly and Frank [98] described in this appendix.
The entries in this appendix are listed in reverse chronological order, in keeping with the format of the class discussion lists. The oldest entry summarizes our progress immediately following the end of classes. If you arrived at this page by clicking on a link in some other document, you might want to refer to the last status update on the project recorded in this document which is available here. The most recent – and also final – post in this document is here and speaks less to the project and more to our preliminary thinking about topics for the 2021 class.
December 31, 2020
%%% Thu Dec 31 09:34:32 PST 2020
The following is a redacted and annotated transcription – text set off in [square brackets] is likely a transcription error – of Chapter 14 from the audiobook version of [123] which is itself largely adapted from the earlier treatment in [122]. If you are interested in following up, the earlier book, Figments of Reality, though uneven and intellectually overreaching in some parts, has much to recommend it as a source of interesting viewpoints and thought provoking theories. I mostly agree with Melanie Mitchell's review in the New Scientist [86]. It may seem an odd reference for a scientist / engineer to draw insight from, but the general topic and main premise are highly relevant to our discussion of [1], and so please bear with me:
Now look at a baby in a pram throwing its rattle out onto the pavement for mummy or child-minder or indeed passers-by to retrieve we probably think that the child is not coordinated enough yet to keep its rattle within reach we think lost property, then we see mummy give the rattle back to the child to be rewarded with a smile and we think, no it's more subtle there is a baby teaching its mother to fetch just as we adults do with dogs now we think object.The baby smile is itself part of a complex reciprocal system of rewards that were set up long ago in evolution. We watch babies copy the smiles of parents, but no, it can't be copying because even blind babies smile, anyway copying would be immensely difficult from anywhere on the retina, the undeveloped brain must [sort out a face] with a smile then work out which of its own muscles to work to produce that effect without a mirror.
No! It's a pre-wired reflex; babies reflexively react to cooing sounds and to pre-wired recognition of smiles and upwardly curved lines on a piece of paper works just as well. Smile [icon] rewards the adult who then tries hard to keep the baby doing it. The complex interactions proceed changing both participants progressively.
They can be analyzed more easily in unusual situations such as cited children with signing parents, perhaps deaf or dumb but occasionally as part of a psychological experiment. For example, in 2001 a team of Canadian researchers headed by Laura-Ann Petito studied three children about six months old, all with perfect hearing, but born to deaf parents [102, 103].
The parents cooed over the babies in sign language and the babies began to babble sign language? That is make a variety of random gestures with their hands in return. The parents used an unusual and very rhythmic form of sign language quite unlike anything they would use to adults.
Similarly adults speak to babies in a rhythmic sing-song voice and between the ages of about six months and a year the babies' babel takes on properties of the parents' specific language. They are rewiring and tuning their sense organs - in this case the cochlea, to hear that language [best]. Some scientists think that babbling sounds is just random opening and closing of the jaw, but others are convinced it is an essential stage in the learning of language.
The use of special rhythms by parents and the spontaneous babbling with hand movements when the parents are deaf indicate that the second theory is closer to the mark. Petito suggests that the use of rhythm is an ancient evolutionary trick exploiting the natural sensitivities of the young child.
As the child grows its complex interaction with surrounding humans comes to produce wholy unexpected results, what we call emergent behavior meaning that [it is not apparent in the behavior of the individual component systems as they perform independently, but only in the situation in which two or more systems interact]. We call the process a complicity. The interaction of an actor with an audience can build up a wholly new and unexpected relationship.
The evolutionary interaction of blood sucking insects with vertebrates paved the way for protozoan blood parasites that cause diseases like malaria and sleeping sickness. A car and driver behaves differently from either [one] alone, and car and driver and alcohol is even less predictable. Similarly human development is a progressive interaction between the child's intelligence and the cultures extelligence a complicity1.
This complicity progresses from simple vocabulary learning to the syntax of little sentences and the semantics of fulfilling the child's needs and wants and the parents' expectations. The beginning of storytelling then becomes an early threshold into worlds that [] chimpanzees know not of. The stories that all human cultures use to mold the expectations and behavior of the growing child use iconic figures, there are always some animals and then status figures of the culture, e.g., princesses, wizards, giants and mermaids. These stories sit in all our minds contributing to [our acting out our thinking about and predicting] what will happen next as caveman or cameraman.
We learn to expect outcomes of particular kinds frequently expressed in ritual words and "they all lived happily ever after" or "so it all ended in tears". as G. K. Chesterton pointed out, fairy tales are certainly not as modern detractors of the fantasy genre believe set in a world where anything can happen be existed in a world with rules, "don't stray from the path", "don't open the blue door", "you must be home before midnight" and so on in a world where anything could happen you couldn't [have stored words at all].
The stories that have been used in England over the centuries have changed in complicity with the changing culture making the culture change and responding to those changes like a river changing its path across a wide floodplain that it has itself built the Grimm brothers and Hans Christian Anderson were but the last of a long series with Charles Perrault's accumulating the mother goose tails around 1690, there were many collections before that especially some interesting Italian groupings and retellings for adults [40].
The great advantage we all get from this programming is very clear; it trains us to do 'what if' experiments in our minds using the rules that we picked up from the stories just as we picked up syntax by hearing our parents talking these stories of the future enable us to set ourselves in an extended imagined present just as our vision is an extended picture reaching much further out in all directions than the tiny central part to which we're paying attention.
These abilities enable each of us to see ourselves as being set in a nexus of space and time our here and now form only the starting place for our seeing ourselves in other places at other times this ability has been called time-binding and has been seen as miraculous but it seems to us but it is the culmination for now of an entirely natural progression that starts from interpreting and enlarging vision or hearing and from making sense in general the extelligence uses this faculty and how.
[Each telling] improves it for each of us so that we can use metaphor to navigate our thoughts. Pooh bear getting stuck and unable to exit with dignity because he ate too much honey is precisely the kind of parable that we carry with us to guide our actions as metaphor from day to day. [TLD: Ask yourself, do humans learn language in order to read, learn and understand stories, or do we learn, listen, and seek to understand stories in order to learn language. Expressed in another way, is human language essentially a technology for creating, adapting, revising and utilizing stories. Think about the implications of this insight for building intelligent artifacts including not just individual, independent humanoid AI agents, but also collections of AI agents that learn by sharing stories among themselves and with us, not only accelerating their learning skills but also our incorporating our ethos into their values and aspirations.]
Thought Experiments: As an exercise, think about how a teacher might use stories and puzzles to teach students algorithmic thinking. Since logic is essential for understanding, designing and verifying programs, include exercises employing logic to analyze program properties. The following is sketchy and could be improved to reach a broader audience, but it illustrates the main features I have in mind for this exercise:
Imagine a row of soldiers standing in a column or a row of children sitting in desks in a classroom, and imagine the participants – soldiers or students – are told to compare their height with the height of the person directly behind them, and change positions – desks in the row or places in the column – if they are taller than this person.
The goal is to arrange the participants so that every student has an unobstructed view of the blackboard in the front of the room, or the soldiers an unobstructed view of their drill sergeant. Is it inevitable that this could always happen? For sake of this discussion, you can assume that if the participants are ordered by their height then every participant has an unobstructed view of what is ahead.
As you will see, it gets a bit complicated if everyone did this at the same time, and so imagine that this done one person at a time starting from the front of the row / column and working backward to the last person. Imagine two adjacent persons standing in line, they turn to face one another and one of them uses her hands to indicate the distance between the top of her head and the top of her partner's head. Note that because the participants change position, the "next" person in the line is poorly defined. Why is this a problem? Give an example of how such ambiguities might arise and suggest a way of resolving it.
What would happen if you carried out this process repeatedly? Would there come a time when repeating the process yet again would result in no changes in the order of the participants? If you think not, provide an example of an ordering and demonstrate how this might happen. Consider the case in which two adjacent participants disagree about which one of them is tallest, and they alternate between being the one to make the final determination. How might you resolve this so that any two participants will always agree on which one is tallest?
If you think repeating the process indefinitely will always result in a state in which repeating it one more time will result in no changes, construct an argument proving that this is so. One way to prove this statement is to assume that the statement is false and demonstrate that this leads to a logical contradiction, i.e., an absurd conclusion. This is called proof by reductio absurdum. Look up Peano's Axioms and prove that the set of natural numbers is infinite by reductio absurdum.
Another strategy is to demonstrate it works for a row consisting of two participants – the so-called base case, and then demonstrate that, if it works for a row consisting of N participants, then it works for a row consisting of N + 1 participants – this is referred to as the inductive step in a proof by induction. See if you can prove by induction that repeating the process described above will always terminate in a state such that every participant has an unobstructed view of what is ahead.
Miscellaneous Loose Ends: Students not familiar with some of the recent innovations in designing objective functions for reinforcement learning might find this note of some interest2.
December 23, 2020
%%% Wed Dec 23 05:04:14 PST 2020
In Sunday's group meeting I volunteered to provide a sample of papers and references relating to the alignment of neural circuits implicated in processing semantic information and those responsible for facilitating the production and understanding of language by means of speaking, writing and signing in the case of production, and listening, reading and observing in the case of understanding – language is more than simply a spoken medium for communication.
I recommend the following survey / review papers by Gregory Hickock and David Poeppel as a starter [105, 54, 55]. If you are ambitious, you might sample the reference book by Hickok and Small [53], which I recommend reservedly on the basis of the relatively few papers I've read in the almost 2,000 page compendium – ask me if you would like access to any of these resources:
@book{HickokandSmall2015neurolanguage,
title = {Neurobiology of Language},
author = {Hickok, G. and Small, S.L.},
publisher = {Elsevier},
year = {2015},
abstract = {Neurobiology of Language explores the study of language, a field that has seen tremendous progress in the last two decades. Key to this progress is the accelerating trend toward integration of neurobiological approaches with the more established understanding of language within cognitive psychology, computer science, and linguistics. This volume serves as the definitive reference on the neurobiology of language, bringing these various advances together into a single volume of 100 concise entries. The organization includes sections on the field's major subfields, with each section covering both empirical data and theoretical perspectives. "Foundational" neurobiological coverage is also provided, including neuroanatomy, neurophysiology, genetics, linguistic, and psycholinguistic data, and models.}
}
My lecture notes for CS379C on May 5 and the follow-up discussion and refined model on May 17 focus primarily on an exercise to come up with a simple model of inner speech inspired by the 2013 book by Fernyhough [41] and related journal articles [64, 5, 4]. In particular, Fernyhough and McCarthy-Jones [42] provide an interesting analysis of the various pathologies relating to inner speech that draws upon the literature on developmental psychology and neuroscience to postulate possible accounts of the origin of these maladies:
@incollection{FernyhoughandMcCarthy-Jones2013hallucination,
author = {Fernyhough, Charles and McCarthy-Jones, Simon},
title = {Thinking Aloud about Mental Voices},
booktitle = {Hallucination: Philosophy and Psychology},
editor = {Fiona Macpherson and Dimitris Platchias},
publisher = {The MIT Press},
year = {2013},
abstract = {It is commonly believed that auditory verbal hallucinations (AVHs) come from a misattribution of inner speech to an external agency. This chapter analyzes whether a developmental view of inner speech can deal with some of the problems associated with inner-speech theories. The chapter examines neurophysiological and phenomenological evidence relevant to the issue and looks up some key issues for future research.}
}
The conventional view of speech as primarily localized in Broca's and Wernicke's areas in the frontal and temporal lobes has yielded to a more nuanced distributed model that engages a diverse collection of cortical areas – see here, but if you want to understand how language and meaning are structurally and computationally related in the brain, you'll need to study the multi-modal sensory-motor association areas in the temporal and parietal lobes, the dual "what-versus-where" streams of the auditory and visual cortex, and the reciprocal connections related to Fuster's hierarchy and the action-perception cycle.
As a start you might take a look at the relatively recent work revealing insights about functional anatomy of language, where by function we include the relationship between the production of language by speech and signing and the interpretation of linguistic artifacts. See Huth et al [61] for an fMRI study out of Jack Gallant's group at UC Berkeley resulting in a semantic map of the cerebral cortex identifying putative semantic domains3.
@article{HuthetalNATURE-16,
author = {Huth, Alexander G. and de Heer, Wendy A. and Griffiths, Thomas L. and Theunissen, Fr\`{e}d\`{e}ric E. and Gallant, Jack L.},
title = {Natural speech reveals the semantic maps that tile human cerebral cortex},
journal = {Nature},
publisher = {Nature Publishing Group},
volume = {532},
issue = {7600},
year = {2016},
pages = {453-458},
abstract = {The meaning of language is represented in regions of the cerebral cortex collectively known as the 'semantic system'. However, little of the semantic system has been mapped comprehensively, and the semantic selectivity of most regions is unknown. Here we systematically map semantic selectivity across the cortex using voxel-wise modelling of functional MRI (fMRI) data collected while subjects listened to hours of narrative stories. We show that the semantic system is organized into intricate patterns that seem to be consistent across individuals. We then use a novel generative model to create a detailed semantic atlas. Our results suggest that most areas within the semantic system represent information about specific semantic domains, or groups of related concepts, and our atlas shows which domains are represented in each area. This study demonstrates that data-driven methods--commonplace in studies of human neuroanatomy and functional connectivity--provide a powerful and efficient means for mapping functional representations in the brain.},
}
December 19, 2020
%%% Sat Dec 19 04:53:41 PST 2020
Thanks to Chaofei for pointing out the Abramson et al [1] paper from DeepMind4. It is definitely relevant to our discussion last Sunday, and, in particular, to the debate between Gene, Yash and I on the best strategy to bootstrap learning in the model we're working on. The motivation spelled out in the first few pages of the paper reminds me of my early thinking about the programmer's apprentice and in particular the collateral benefits of having the apprentice interact with the programmer on the target task – using simple language, but also pointing, and other non-linguistic signals, and the importance of grounding language in target task, in our case, of interpreting and writing programs.
The DeepMind paper reinforces this intuition and makes the crucial connection between goals and rewards in the spectrum of imitative learning from the simplest, most primitive goals to complex plans that compose those primitives to achieve complex tasks. Relevant to our discussion last Sunday, infants learn how to point, compare, swap, order, combine, select, discard, attend and achieve other simple goals without supervision in their first few months postnally. Later, in the process of acquiring language, they learn to associate words and gestures with these simple goals, generalize them to apply to different contexts, and combine them to form plans for solving more complicated problems.
The DeepMind authors underscore the importance of language in learning how to solve problems and acquire knowledge. By attaching a word to performing a comparison or swapping two items, children acquire a linguistic affordance that serves as the locus for acquiring and applying knowledge concerning its use [82]. Yash and I were advocating we bootstrap learning by having the system learn to imitate, replicate and experiment with these primitive goals in different contexts as prologue to learning how to apply them to solving more complicated problems in the same way that baby chicks mirror the sounds that their parents make in preparation for learning species-specific alarm calls and intricate mating songs – see the discussion here.
The process whereby children acquire these primitives goes by different names in different disciplines, e.g., imitation learning, behavioral cloning, mirroring, motor babbling, etc. Whereas language is the key to generalizing and extending these primitives in humans, there are likely non-linguistic solutions to this problem, including, for example, simple pidgin proto languages, signing and pantomiming that can serve in this capacity. As for a mechanism, there is evidence that mirror neurons facilitate such learning in macaques and humans, as well as song birds and very likely in other species in which we have observed sophisticated behavioral imitation and the rapid sharing of novel tool use [144].
It is a misconception to think that what infants learn in their first few weeks is fundamentally simple when compared to learning how to transfer the contents of working memory between registers so as to provide the foundation for comparing, ordering, combining, sequencing, etc. The motor skills a baby acquires in its first few months require the integration of neural activity across multiple scales and include learning how to control circuits in the motor cortex, brain stem and spinal cord, as well as mechanosensory neurons located within muscles, tendons and joints. Learning such skills in chordates is facilitated by an inductive bias implicit in the manner in which bones, muscles and ligaments constrain movement to carry out useful motion.
This early learning depends on the accuracy and specificity of an action-perception cycle that, among other features, serves to align and subsequently maintain the alignment of our movements with the proprioceptive sense of the body. In the case of our model, proprioceptive awareness corresponds to accurately aligning the selection of registers and transfer of register contents with the spatiotemporal layout of working memory. In our proposed bootstrapping strategy, motor babbling amounts to training the system to reliably perform register transfers by imitating the output of the register-machine compiler in generating microcode instructions for representative code fragments.
Josh is not listed among the authors of Abramson et al [1], but Greg is one of the two corresponding authors, and his influence is apparent throughout. In a previous message, I called attention to the section in Merel et al [83] on inter-regional control communications, targeting the role of the coding space and related coding schemes in terms of facilitating communication between layers in hierarchical and modular learning systems. If you haven't read the section in [83] on ethological motor learning and imitation, see the excerpt in the footnote at the tend of this sentence as it anticipates the discussion in Abramson et al [1]6.
The authors take some time in describing the challenges involved in enlisting human agents to train artificial agents to produce human-like responses, concluding that "before we collect and learn from human evaluations, we argue for building an intelligent behavioral prior: namely, a model that produces human-like responses in a variety of interactive contexts", and so then turn to "imitation learning to achieve this, which directly leverages the information content of intelligent human behavior to train a policy."
The input space of the agent is multi-modal but steps are taken to reduce the complexity of the joint state space by substantially constraining each modality. The visual input to the agent is low resolution "[a]gents perceive the environment visually using RGB pixel input at resolution of 96 × 72," and artificial affordances facilitate performing visuomotor actions, e.g., "[w]hen an object can be grasped by the manipulator, a bounding box outlines the object." Language input and output is simplified by using a restricted vocabulary, "[w]e process and produce language at the level of whole words, using a vocabulary consisting of the approximately 550 most common words in the human data distribution."
The underlying Markov process is assumed to be partially observable, "[a]t any time t in an episode, the policy distribution is conditioned on the preceding perceptual observations, which we denote (o0, o1, …, ot) for 0 ≤ t, and the policy is autoregressive, "[t]hat is, the agent samples one action component first, then conditions the distribution over the second action component on the choice of the first, and so on." Their choice of GAIL (Generative Adversarial Imitation Learning) as the basic building block for their multi-modal transformer (MMT) architecture makes sense given the characteristics of their objective and the underlying dynamics [56, 143, 51].
The authors quite reasonably restrict the content of the dialogue between student and teacher in order "to produce a data distribution representing certain words, skills, concepts, and interaction types in desirable proportions" by using a controlled data collection methodology based on events called language games in homage to Ludwig Wittgenstein [148]. It is worth a moment to reflect on this approach, given that the point of the our exercise here is to separate the laudable high aspirations of Abramson et al [1] from the modest, yet noteworthy preliminary steps they chronicle in the paper, and see if we can learn from their experience.
While the problem addressed by Abramson et al is different in both scope and target skill from our work, there are some lessons we can apply to the problem we are working on. In our model, the environment corresponds to that part of the model separate from the basic agent architecture. This environment is accessible directly through the input stream and actionable through the output stream. We have access to unlimited ground truth through the DRM compiler, so that the size and distributional characteristics of samples are completely under the control of the curriculum learning system.
Apart from the superficial differences, what sets their approach from ours comes down to the power of language to efficiently convey skills between agents sharing the same language and general development trajectory. It would be worth talking about this during Sunday's meeting as I think it might resolve – or at least refocus – some of the issues that came up last Sunday regarding how to train the lowest level in our hierarchical model and what we expect to learn in higher levels. As preparation for such a discussion, see here for a brief discussion of the naïve physics of swapping registers.
Miscellaneous Loose Ends: Figure 1 lists the implementations of two simple sorting algorithms that run on the current instantiation of the virtual register-machine – there is a subtle caveat regarding this claim that we will address shortly. Both algorithms are variants of bubblesort and, while they are neither space- nor time-efficient, efficiency is not the point of this exercise. This is primarily an exercise in understanding the difficulty of learning different algorithmic strategies:
The algorithm on the left consists of two recursive procedures: an inner loop that scans through the input sequence reversing consecutive pairs not in ascending order, and an outer loop that manages the use of the two register blocks in working memory. The algorithm uses the two register blocks that we employ for two-pattern SIR and AWK substitution tasks, by swapping back and forth between the two blocks until no additional changes are required. In each iteration, the inner loop reads from one register block and writes to the other.
| |
| Figure 1: Two variants of bubblesort. The one on the left works by reading from one register block and writing to the other, and alternating between — or swapping — the two register blocks. The one on the right reads from and writes to the same register block and only uses two blocks of the other register block for temporary storage in swapping the contents of two register blocks. The algorithm on the right is slightly more space efficient, requiring only O(n + 1) rather than O(2n) space. | |
|
|

An alternative would be to learn now to swap the contents of two registers, an operation that requires the use of another register for temporarily storing the contents of one register so as not to overwrite the only copy of the contents of the other. By swapping the contents of two registers, we can modify the algorithm to require O(n + 1) rather than O(2n) space. The algorithm on the right implements this strategy. It is interesting to think about which of the two algorithms would be easier to learn.
What does it mean to swap the contents of two registers? It's not enough to describe the state just prior to and immediately following the swap. If you want to understand the concept of a swap well enough to apply it in a novel situation, correct a flawed application of the concept or explain it to someone else, then you have to understand the concept of temporary storage, the potential destructive consequences of assigning a value to a variable that already has a value, and the general notion of protecting information necessary to complete a given task.
The programmer's apprentice would need to know this sort of thing, and while the programmer could, in principle, teach the apprentice, the problem is that there is good deal of other practical knowledge the apprentice would have to master before the programmer could even explain the relevant concepts. It is not clear to me whether or how the agent described in Abramson et al [1] would acquire this knowledge; my conjecture is that the answer is probably "yes, in principle", but that it may require more extensive preparatory training than the current corpus of language games supports.
December 5, 2020
%%% Sat Dec 5 04:49:23 PST 2020
The most interesting takeaway from last Sunday's meeting is that Yash made a compelling case that most if not all of the functionality packed into this figure could be integrated into existing circuits in the model shown in the earlier figure. Yash's reasoning and the discussion that followed delved into how CNN layers in a transformer stack could learn complex compositional representations and how different flavors of experience-replay, e.g., prioritized, hindsight, etc. could be used to address the problems anticipated in learning the models we are proposing.
In the process of this discussion, I realized that the separate DNC-based, hippocampal-inspired complementary-learning-system that I envisioned was motivated by my desire to highlight functions as separate components in a single architecture and mitigate problems associated with attempting to learn sharply-defined ("symbol-like") features rather than embrace the distributed nature of neural computation in humans and the radical end-to-end-trained connectionism espoused in the PDP books and current machine learning practice. I haven't completely shed my biases, but I can appreciate the simplicity and elegance of the model Yash sketched in our discussion.
November 27, 2020
%%% Fri Nov 27 04:23:17 PST 2020
This entry is the latest installment in a series of exercises intended to step back and summarize the architecture as a whole and highlight specific innovations we have introduced to address the challenges of learning how to interpret and ultimately write programs designed to solve specific tasks. The BibTeX records including all of the abstracts are provided for your convenience in this footnote7.
A Differentiable Register Machine (DRM) is a type memory network [126] related to the Differentiable Neural Computer [50] (DNC) and its predecessor, the Neural Turing Machine [49], but emulating a class of automata called Register Machines featuring a Turing Complete instruction set consisting entirely of operations that transfer the contents of one register to another.
Working memory consisting of a collection of registers all the same size and each one capable of containing a single one-hot vector representing an alphanumeric character or special codon, e.g., an end-of-sequence marker. This memory is highly structured spatially in terms of its layout and patterns of access, and temporally in terms of how it changes over time as transfers between registers corresponding to DRM microcode instructions are executed altering the contents of working memory in the process of emulating programs.
The rest of the neural network architecture employs the DRM similarly to how a novice programmer might use an integrated development environment (IDE) in the process of learning how to interpret programs written in a high-level functional programming language such as Scheme, a modern dialect of Lisp that we employed to writer a compiler for the DRM we use to train the model. We’ll refer to this neural network as a Teachable Executive [Control|Coder] [Homunculus|Hierarchy] (TECH) – see Figure 2 for a relatively current sketch of the evolving network architecture.
| |
| Figure 2: The above graphic was part of a slide presentation for a talk I gave in Jay McClelland's regularly scheduled lab meeting on November 10, 2020. The centrally-situated, primarily black line-drawing of the neural network architecture is a slightly modified rendering of the architecture at the time of the talk generated by Yash Savani. The smaller, inset graphics surrounding the architecture drawing are borrowed from the three papers referenced in the inset bibliography. These three papers along with Merel et al [83] substantially influenced our design choices. | |
|
|

For explanatory purposes, you can think of the TECH neural network architecture as having the basic layout of a Transformer architecture of the sort you might use for machine translation or some other NLP task, but with four important differences:
A decoder that exploits the spatial and temporal structure inherent in the time series of DRM registers as they change over time in the process of executing DRM microcode instructions.
Specifically, this decoder is implemented by the attentional layers in the decoder of a conventional Transformer stack [111], aided by positional encodings and relative positioning constraints specific to the architecture of working memory that capture syntactic structural relationships between registers and their contents, providing guidance in the form of the softmax output highlighting content relevant to action selection in the downstream Monte Carlo Tree Search [141] (MCTS) component – not shown in Figure 2.
An encoder that compensates for the partially observable characteristics of the DRM time series by learning to incorporate task-relevant information about the past into its current summary of the evolving state of the DRM and its predictions of future states and their associated rewards for the purpose of reinforcement learning.
Specifically, this encoder is implemented as a variational autoencoder (VAE) and roughly corresponds to the encoder in a conventional Transformer stack. This particular class of VAE [132] employs a discrete latent representation to exploit the semantic spatiotemporal relationships implicit in the time series of register contents necessary to unambiguously identify register transfers in the lowest level in the hierarchy and subroutine selection in the higher levels.
A hierarchy of procedural abstractions that reduce the combinatorics of generating sequences of actions and that roughly correspond to the abstractions employed in software engineering to create modular artifacts that facilitate code reuse and simplify the development of complex software systems – see the May 19th entry in this log for Tishby and Polani's analysis of hierarchies of sensing-acting systems [127].
A more sophisticated method than the traditional beam search [68] for searching for the next action to perform analogous to choosing the next word in the case of machine translation or document summarization [119, 141], combined with learning a discrete latent representation that generates discrete codes – see the November 4th entry in this log for more technical detail regarding the class of vector-quantization variational autoencoders (VQ-VAE) [132].
Aside from the design of the differentiable register multiplexer – DRM switchboard – used to select and transfer information between registers, the only remaining major architectural component concerns the network responsible for compiling L1 primitives in order to generate the library of subroutines that will serve as L2 primitives. We imagine a two tiered system that includes a long-term consolidation memory containing program traces that have been adapted and indexed to apply to a wider range of situations than those observed during L1 training.
 |
The above graphic depicts the contents of consolidation memory as a collection of computation trees constructed from multiple trace fragments using branch points identified in program execution traces to define the beginning and end of candidate subroutines. In addition to the consolidation memory, there is a smaller, shorter-term memory system that serves as a staging area and buffer for subsequent consolidation, rehearsal and the application of reinforcement learning strategies such as prioritized experience replay [91, 79, 113] and its extensions and refinements including hindsight experience replay [95, 9].
The resulting architecture will be challenging to train and likely require several different training strategies including both unsupervised methods, for example, imitation learning and a cognitive version of what is referred to as motor babbling in robotics, and supervised methods, and several methods for using Monte Carlo tree search to accelerate reinforcement learning [104, 134, 119, 141]. The remainder of this entry concerns our current plans for how to compile subroutines.
The following discussion represents a proposal for solving the three problems described in the November 19th entry of the appendix log. It addresses all three of the problems but the proposed solutions to these problems are interwoven and so I will lay out the proposal and hopefully it will be convincing that the proposed approach deals with the three problems.
In thinking about how Level I subroutines might have to be padded with sequences of individual register transfers in order to bridge the gap – or interpolate – between subroutines, I thought more about the problem of segmenting sequences of register transfers into reusable subsequences that can be combined and used as subroutines, and it occurred to me that this is already done implicitly by the compiler in the process of interpreting programs as sequences of procedure calls. The compiler-generated segmentations do not leave gaps and consistently produce the same sequence of subsequences as output given the same input / initial conditions, thereby providing a reliable source for training samples.
This approach to generating training data is especially powerful in the case of programs written in a traditional functional programming language in which iteration is carried out by recursive calls to the same procedure. We could, of course, disentangle traditional iterative constructs such as FOR and WHILE loops and treat the blocks of code within these constructs as reusable components but I predict that would be complicated and in any case unnecessary if we rely solely upon recursion.
Importantly, by constructing subroutines at the level of procedure calls, we finesse the problem of interpolating between subroutines by eliminating the gap altogether. In principle, we could build a more fine-grained set of reusable components by compiling a collection of subroutines that includes every expression occurring within procedure. If this strategy is successful it would eliminate altogether the need for run-time interpolation. It probably would not, however, eliminate the need for error correction in cases where the errors requiring correction are due to faults introduced in the process of compiling subroutines.
I have come up with several strategies for packaging, storing and retrieving subroutines, and so far they all have too many moving parts and involve sharing responsibility – and therefore coordination – across several architectural components. The strategy proposed here is a significant departure from all of the earlier ones, in that it packs all of the required functionality within a single architectural component and no doubt has its inspiration – and possibly its very origin – from one or more of the many papers about neural coding that I've read in the last three or four weeks.
We'll start with some assumptions and treat them for the remainder of this document as being valid – we can discuss this on Sunday if any of them seem particularly murky or improbable to you. The basic concepts build upon the Kumaran et al [73] paper on complementary learning systems and two papers about episodic memory and the hippocampus, one by Samuel Gershman and Nathaniel Daw [48] and the other by Dharshan Kumaran and Jay McClelland [74] both of the latter revisiting the role of the hippocampus focusing on integrative features of the hippocampal complex that have come to light in the past few years. In keeping with our approach all along in gleaning insight from cognitive neuroscience, we borrow the insights we deem useful and ignore most of the biological details in translating those insights into code.
Instead of thinking of the hippocampus as a stable repository for storing episodic memories, think of it as a dynamic sketchpad for storing and refining potentially useful procedural knowledge that is constantly in flux as useless or superseded knowledge is culled out, new information integrated with older, out-of-date information, and procedures in the form of plans or specialized courses of action are altered in their scope, optimized and corrected in light of new experience. All of this machinery is built upon a high capacity memory system that can retain memories indefinitely while at the same time offering the read and write flexibility of working memory.
| |
| Figure 3: The above graphic was adapted from a model that we – Chaofei Fan, Gene Lewis, Meg Sano and I – explored last year and was featured in the October 25 posting to the 2020 class discussion list. The model has two features that are relevant to our discussion here. Network A takes as input a representation of the current state, and generates a representation of the context for action selection. Network K is an embedding network that takes as input a sequence of states corresponding to recent activity and generates as output a unique key associated with a subspace of the full state space that includes the current state. Network K plays the role of the coding space in Merel et al [83]. The networks C, D, E and F are controllers for two differentiable neural computer (DNC) peripherals that provide storage and access for short-term and long-term memory respectively. The model operates in two modes. In each cycle during the online mode, the C controller loads the selected expert network into location M where it is fed the output of A and produces the input to B. In this mode, the short-term memory is used to record activity traces that are subsequently used in the offline mode to update the networks stored in long-term memory using experience replay. The inset box labeled (a) illustrates the concept of trace consolidation in terms of compiling subroutines as computation trees. See here for an argument suggesting that the functionality provided by the components shown here could be integrated into existing circuits in the model shown in Figure 2. | |
|
|

We imagine a two tiered system that includes a less capacious, shorter-term memory system that serves as staging area and buffer for consolidation, rehearsal and various reinforcement learning strategies such as prioritized experience rapid replay[91, 79, 113]. In addition to the shorter-term staging area we have the larger, longer-term consolidation area which undergoes continuous changes in accounting for new information – see Figure 3 for an earlier related model, and the earlier explanation of trace consolidation in terms of compiling subroutines as computation trees.
November 19, 2020
%%% Thu Nov 19 03:54:13 PST 2020
The previous entry focused on using the transformer attentional layers to generate a representation of the evolving state of a running program so as to uniquely specify the next instruction in the program. We argued that it was not enough to create a representation that is unique only within the context of a particular program since primitives at one level in the hierarchy are compiled into subroutines at the next level and therefore likely to be employed in programs to solve tasks not encountered in training the subordinate level. We also demonstrated how the register machine compiler can used to visualize the evolving state of a running program.
In this entry, we provide an example of two programs that exhibit identical working memory content, but require different sequences of instructions in order to correctly carry out their specified functions. It seems plausible, but we have no proof as yet, that this problem can be resolved by assigning a unique signature to each program, adding a register that at all times holds the signature of the currently running program. As for recognizing and subsequently deploying a subroutine compiled at one level to learn a new program to solve a novel task in the superordinate, we discuss the role of the coding-space interface between superordinate and subordinate levels in the hierarchy.
| |
| Figure 4: An example of how state vectors constructed from identical register contents can crop up in performing either an AWK substitution task or a two-pattern SIR task, and produce different results. The panel on the left represents the contents of working memory giving rise to the ambiguous state vector. The next step for both programs is to compare the input stream against the pattern in the third column labeled PATONE in the SIR task and PATTERN in the AWK task. As shown in the middle panel, if the match succeeds, the SIR program writes to the output buffer the sequence of characters in the third column corresponding to the first pattern specified in the SIR task. As shown in the right panel, if the match succeeds, the AWK program writes to the output buffer the sequence of characters in the fourth column corresponding to the replacement pattern specified in the AWK task. If the match fails, the SIR program attempts to match second pattern, and if the AWK program fails, then it proceeds to the next character in the input buffer. | |
|
|
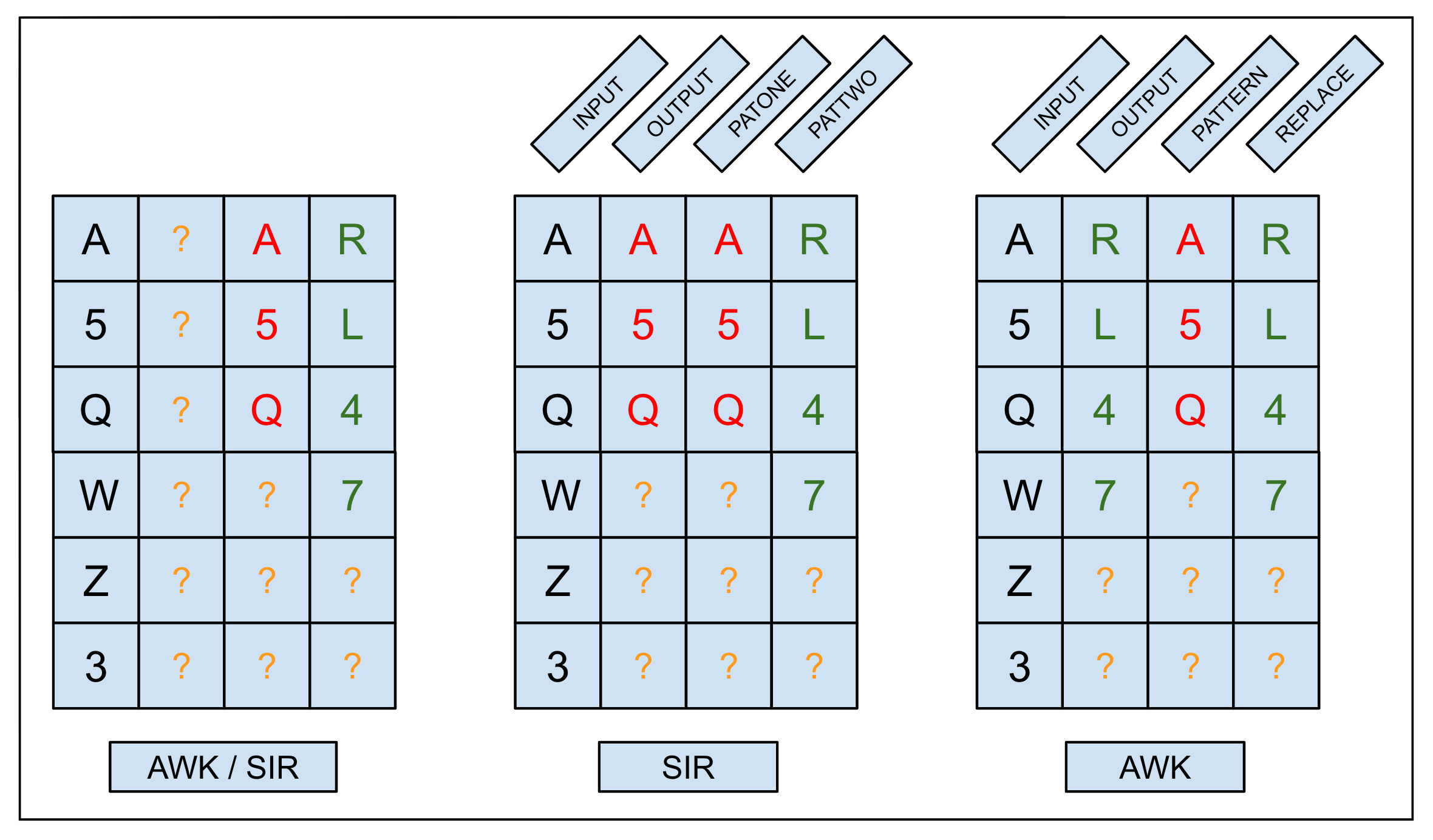
Recall that we originally assumed for simplicity that branch points would determine the boundaries of subroutines, but obviously expressions that determine branching conditions appear frequently within programs and those conditions don't always result in calling some other program. As a consequence, it seems likely that we will have to compile subroutines that include internal branches and then deal with consequences, if any, in situations when the calling program finishes and control returns to the caller. The remainder of this entry is devoted to exploring this issue in more detail.
The simple sequence of loading the contents of two (source) registers into the input registers (operands) of the comparator subroutine and transferring the resulting output, interpreted as a Boolean value, to a specified (sink) register includes no branches and is likely to be one of most frequently executed Level II subroutines often serving as the basis for conditional branches. Copying a sequence of characters from one register block to another. Comparing sequences in two register blocks, and swapping the contents of two registers are other prime candidates for packaging as subroutines.
Packaging might entail, in the case of comparing two sequences, providing the first register in each of the two blocks containing the sequences to be compared and a register in which to store the Boolean output reporting whether or not the two sequences are equal. Universally requiring standard representations and standard locations for temporarily storing Boolean values, e.g., 0 and 1, empty registers, e.g., ?, the start and end of sequences and subexpressions, e.g., [ and ], etc., will considerably simplify the job of compiling and packaging subroutines.
There are several problems at the interface between Level I and Level II that we have lumped into what Merel et al called the coding space. Apparently, Merel et al [83] train their Level I and coding-space related networks independently of Level II which in their case is characterized as one instance of a class of interchangeable modules that employ the same Level I motor primitives. Merel et al admit the shortcomings of the arrangement described in their paper, and briefly discuss the broader issues citing the work of Karl Friston [44] and Todorov, Ghahramani and Jordon [129, 130]. See this footnote8 for the relevant excerpt from [83].
What follows is a list of the major problems relating to our model in an attempt to address the issues raised in the papers referenced in the previous paragraph. Note that in the following we refer to Level I and Level II but same issues and problems arise in the other levels of the hierarchy:
Problem 1 – Level II needs a subroutine compiled from Level I primitives in order to construct (learn) a program to solve a new task in a class that was not included in training Level I. The central issues related to this problem concern (a) how Level II knows about this subroutine, (b) how it infers that the subroutine applies in the current circumstances, and (c) how the subroutine is initially packaged and subsequently adapted to apply to problems it has never before encountered.
Problem 2 – Level II has arrived at state s and ultimately wants to achieve state s′; it may not be possible to reach s′ by executing a single Level I subroutine and so making progress toward achieving s' will require search9. The central issues center around which of the two levels are responsible for initiating, subsequently guiding and ultimately selecting and returning a promising Level I subroutine or admitting failure. More generally, it raises the issue of whether Level I and its related coding-space network play any active role following the initial Level I training and compilation of subroutines.
Problem 3 – Suppose that Level II can't find a subroutine (generated by Level I) to bridge the gap between current state s and the goal state s′. Either there isn't a subroutine that extends the search from s or there exist such subroutines but none of them appear to make progress toward s′. How do you find a subroutine that applies in the current state and given such a subroutine how do you determine if it makes progress to the goal state? [The use of the term "goal" in this context may or may not be useful. Keep in mind that the objective is to learn how to emulate programs that solve tasks, so perhaps it makes more sense to say "instances of problems that can be solved by particular programs."]
There will likely be circumstances when some component of the overall system will have to search for and possibly adapt subroutines. If Level II can't find a suitable subroutine starting from the current state using some form of table lookup, Level II or Level I will have to search for a subroutine that is reachable from the current state and, whether Level II or Level I performs the search and selects the subroutine, Level I will have to interpolate between the current state and the initial state of the selected subroutine. Interpolation in our case is more complicated than in Merel et al [83] and will almost certainly entail some amount of search – see Pierrot et al [104] for an extension of the neural programmer-interpreter model [110] emphasizing the role of search in neural code synthesis.
November 17, 2020
%%% Tue Nov 17 03:19:03:14 PST 2020
I've been playing with data generated by the compiler and thinking about some of the assumptions we've made and their consequences with respect to our early thoughts about what needs to happen at the next level in the hierarchy. I'm being purposely long winded to be clear and hopefully reveal to myself the hidden biases and assumptions in my thinking.
In the following, "instructions" refer to what we've been calling "register-machine microcode instructions". Each instruction transfers the contents of one particular source – or read – register to one particular sink – or write – register, overwriting the contents of the latter in the process. The Level I primitives are register transfers, i.e., microcode instructions.
To avoid constantly having to repeat the phrase "executive homunculus", I'll call it the Teachable Executive [Coder | Control] Homunculus and refer to it affectionately as TECH. We could slip in a word beginning with "A" and call it TEACH. but I prefer the simpler TECH. We start with the question, "What tasks is a trained Level I TECH capable of performing?
It seems we should be able to configure the TECH working memory with a "novel" instance of a program / task that TECH has been trained on and have it solve the task. By novel I mean we train TECH on a set of programs drawn from several classes, for example, SIRtasks with one or two same-length patterns, and test it on SIRtasks with two patterns of differing length.
One problem with this is there are AWK tasks whose initial working memory representation is identical to a SIR task. We could show TECH what we intend it to do by providing input / output examples, but even this could be ambiguous if we are interested in distinguishing between different algorithms solving the same problem, e.g., insertion sort versus bubble sort.
I suggest we finesse this problem for now by adding a register containing a unique program code, e.g., AWK3745, and perhaps later consider some means for directly communicating with TECH using the input and output registers. This is too ambitious to consider at this stage, but it suggests a project for students interested in human-computer interaction.
Level I learns to emulate programs and, in order to do so, it has to learn how to map state vectors representing the contents of working memory to specific register transfers that change the contents of working memory thereby executing the next microcode instruction and producing the next state vector as a side effect.
The subroutines that will serve as Level II primitives are compiled from sequences of Level I primitives / microcode instructions. Assuming that we could map the state of a running program to a unique state vector, we could substitute those unique state vectors for their corresponding register transfers.
Given such a map, we could use state vectors as keys to retrieve the source and sink registers necessary to execute the next instruction. This assumes that the contents of working memory are sufficiently distinct to unambiguously identify any program state. That assumption may be warranted with respect to programs used to train Level I, but it is almost certainly not warranted in the case of the larger class of programs used to train Level II.
In fact, the assumption probably doesn't hold with respect to Level I. To make a simple analogy, if you want to predict the path of a flying projectile, it's not enough to know its current position, you also need to know its mass and the forces acting upon it. Similarly, to predict the next state vector you need a model of the underlying dynamics, i.e., the dynamics of the program making changes to the contents of working memory over time10.
This may seem every bit as hard as learning the program, since understanding the dynamics would seem to entail being able to emulate the program. However the previous observation confuses the difference between predicting and changing the future; accurately predicting the future may help in planning to achieve your goals, but it is neither necessary nor sufficient. Transformers suggest a possible solution to our problem.
In language processing applications such as machine translation, transformers employ encoder layers to create embeddings that represent the current context for selecting the next word, and attentional layers that measure the relevance of the words – as well as short phrases (n-grams) – appearing within that context. Positional encoding and relative positioning are important capabilities contributing to the success of transformers that will likely to prove important in our application.
In particular, positional encoding provides a framework for enabling TECH to exploit the topological structure of working memory and the functional relationships between registers and register blocks. While we typically display the layout of working memory as a 2-D grid of registers, many procedures that operate on working memory involve iterating over the linear structure of the register blocks corresponding to patterns and I/O buffers, suggesting a simple tree structure corresponding to a star topology. String comparison and copying operations involve iterating over two registers simultaneously exhibiting functional relationships between buffers that differ from one program to the next. Here [118, 75, 67, 31] are some recent papers exploiting different topologies using different positional encoding strategies.
Miscellaneous Loose Ends: To summarize, this entry challenges our earlier assumption that the compressed current contents of working memory are sufficient to serve as an instruction counter for identifying the next instruction in a previously ingested program. As an alternative, we propose a representation of program state as selective embedding of the last n working memory snapshots — selective with respect to emphasizing features that serve to predict / identify the next instruction in the emulation of both familiar and novel programs11.
Notice the division of labor between the method suggested above to represent the state of a running program for indexing the next step in that program by accounting for the underlying (register-transfer) dynamics, and the method for accessing registers in performing register transfers using VQ-VAE – see the previous entry in this log. Recall that we originally assumed for simplicity that branch points would determine the boundaries of subroutines, but obviously expressions that determine branching conditions appear frequently within programs and those conditions don't always result in calling some other program. As a consequence, it seems likely that we will have to compile subroutines that include internal branches and then deal with consequences, if any, in situations when the calling program returns and control returns to the caller.
November 7, 2020
%%% Sat Nov 7 04:08:02 PST 2020
The material discussed in this entry has been around for some time; however, the brief summary provided here is to make sure that students taking CS379C are aware of the basic technologies and their application. In addition to excerpts from the van den Oord et al VQ-VAE paper [132], I've included mention of research from Bengio et al [15] on the problem of propagating gradients through non-linearities, which is important in learning discrete latent representations as in the case of register addressing.
In terms of training the model, the register-machine compiler now produces a program trace consisting of a sequence of state-action pairs each one consisting of a state vector listing the contents of all working-memory registers followed by the register-machine microcode instruction (register transfer) that immediately preceded the instruction – see this footnote12 for sample output. The full trace is available here.
Van den Oord et al [132] introduce VQ-VAE as a method for employing discrete latent variables in a neural-network setting made possible with a new way of training inspired by vector quantization13 (VQ). The posterior and prior distributions are categorical, and the samples drawn from these distributions index an embedding table. These embeddings are then used as input into the decoder network." VQ is the basis for k-means clustering and related to autoregressive models in time-series analysis14.
The Bengio et al paper [15] explores four possible methods for estimating gradients of latent variables, proving some interesting properties about these methods and comparing them using a simple model of conditional computation in which "sparse stochastic units form a distributed representation of gating units that can turn off in combinatorially many ways large chunks of the computation performed in the rest of the neural network. In this case, it is important that the gating units produce an actual 0 most of the time. The resulting sparsity can potentially be exploited to greatly reduce the computational cost of large deep networks for which conditional computation would be useful."
Register transfers constitute a form of conditional computation. Van den Oord et al use an estimator proposed by Geoff Hinton that Bengio et al describe as "simply back-propagating through the hard threshold function (1 if the argument is positive, 0 otherwise) as if it had been the identity function. We call it the straight-through estimator. A possible variant investigated here multiplies the gradient on hi by the derivative of the sigmoid. Better results were actually obtained without multiplying by the derivative of the sigmoid."
Van den Oord et al apply this "straight-through gradient estimation for mapping from ze(x) to zq(x). The embeddings ei receive no gradients from the reconstruction loss, log p(z|zq(x)), therefore, in order to learn the embedding space, we use one of the simplest dictionary learning algorithms, vector quantization (VQ). The VQ objective uses the L2 error to move the embedding vectors ei towards the encoder outputs ze(x) as shown in the second term of Equation 3 in [132]." If you want to know more, this online tutorial does a credible job of explaining the original VQ-VAE paper, and, if you are not already familiar with k-means clustering, you can review the basic algorithms here.
November 3, 2020
%%% Tue Nov 3 05:02:58 PST 2020
The encoder / Bayesian predictor / VAE model plus ELBO training models featured in Merel et al [84, 83] and van den Oord et al [132] that we've been talking about address one of the central goals articulated in the MERLIN paper [145]: "building integrated AI agents that act in partially observed environments by learning to process high-dimensional sensory streams, compress and store them, and recall events with less dependence on task reward." Wayne et al [145] draw inspiration – see Page 3 in [145] – from three sources that have their roots in psychology and neuroscience: predictive sensory coding from Rao and Ballard [109], the hippocampal representation theory of Gluck and Myers [121], and the related, temporal context model from Howard et al [58, 57] and successor representation introduced by Peter Dayan [21]15.
I draw your attention to the last two items (italicized) in the previous paragraph as they address several of issues we discussed on Sunday, but before I get to that I want to clear up – or at least shed some light on – the different roles of the variational encoder and the transformer attentional model in the architecture that Yash described on Sunday. First, here is an excerpt (annotated with my italics) from the MERLIN paper that underscores the primary insights that we are channeling in the design of our model:
MERLIN optimizes its representations and learns to store information in memory based on a different principle, that of unsupervised prediction. MERLIN has two basic components: a memory-based predictor (MBP) and a policy [characterized as memory-dependent policies later in the paper]. The MBP is responsible for compressing observations into low-dimensional state representations z, which we call state variables, and storing them in memory. The state variables in memory in turn are used by the MBP to make predictions guided by past observations. This is the key thesis driving our development: an agent’s perceptual system should produce compressed representations of the environment; predictive modeling is a good way to build those representations; and the agent’s memory should then store them directly. The policy can primarily be the downstream recipient of those state variables and memory contents. [...] Recent discussions have proposed such predictive modeling is intertwined with hippocampal memory, allowing prediction of events using previously stored observations, for example, of previously visited landmarks during navigation or the reward value of previously consumed food.
Wayne et al [145] also highlight another feature that MERLIN put to good use and that Yash incorporated in the model architecture he showed us Sunday, namely that the MERLIN model "restrict(s) attention to memory-dependent policies, where the distribution depends on the entire sequence of past observations". And so the short answer to the questions we were wrestling with on Sunday, is that the VQ-VAE model remembers relevant information not explicitly encoded in the current state – this is the role of the memory-based predictor in MERLIN, and the transformer attentional model and softmax layers point to – or as I like to say, they highlight – specific information relevant to action selection in support of memory-dependent policies. You might say that the VQ-VAE sets the general context (compressed state vector) for acting while the transformer attentional machinery focuses on specific actionable cues, e.g., the output of the comparator or the likely source and sink for the next register transfer.
For what it's worth, I skimmed the papers [58, 57, 21] referenced concerning the temporal context model of Howard and the successor representation of Dayan and didn't find them particularly relevant to the problem of error correction as we are thinking about it in the context of the register machine. In searching the literature, I stumbled across a number of papers on predictive coding characterized as being employed to "generate predictions of sensory input that are compared to actual sensory input to identify prediction errors that are then used to update and revise the mental model." However, there are a lot of papers on the topic and almost as many alternative interpretations of what error prediction entails.
It might help to come up with a more precise characterization of what we mean by error correction and what we want to accomplish by using it. Most continuous-state controllers incorporate error correction as a means of correcting small errors that crop up naturally as a consequence of imprecision in visual tracking, servo motors, etc, errors that generally can't be anticipated but can be relatively easily corrected. It's this sort of error that Merel et al [83] address in their paper – that these errors can be so easily accommodated attests to forgiving nature of their target application. When our agent chooses the wrong source or sink register in selecting the next register transfer, it needn't be a complete disaster. Obviously, the cost of such an error will depend on the objective function, but it seems reasonable in evaluating performance on a SIRtask to assign partial credit for failing to match one instance of the target pattern in the input sequence, especially if the agent correctly matches most of the other instances.
Note that it is one thing to be able to predict the next state and quite another to figure what went wrong in attempting to achieve that state and how to correct it. The VAE is responsible for the former and the policy and attentional model are responsible for the latter. However, if we take the stance that the policy is trained to take advantage of the advice provided by the attentional model, then it would seem that the blame primarily rests on shoulders of the attention model. This apportionment of responsibility, if strictly adhered to, could serve to simplify training the model. If, as in Merel et al, the weights of the network implementing motor primitives are fixed prior to training the superordinate levels in the executive stack, then it would seem necessary to delegate the responsibility for recognizing and correcting the inevitable errors that likely to crop up when higher levels in the executive hierarchy deploy subroutines composed of motion primitives.
Miscellaneous Loose Ends: I've started enhancing the register-machine compiler to facilitate developing training protocols. The compiler already automates some parts of creating training examples, and there are some aspects of how the compiler runs, that you might want to know if you are developing training models. As a start here is an annotated sequence of compiler instructions along with descriptions of how they are interpreted by the virtual register machine:
INITIALIZE STATE: Load the BUFFIN register block and add any overflow to STAGED-INPUTS, the staging queue used by the OUTPUT register; NOTE: In most cases, initialization is accomplished by running LOAD-REGISTER-MACHINE for each training and evaluation step.
READ INPUT: At this point the NEW-CONTENT-SIGNAL should be #f, return the CURRENT-CONTENT.
WRITE INPUT CONTENT: Set the NEW-CONTENT-SIGNAL to #t, set CURRENT-CONTENT to the supplied CONTENT argument.
WRITE INPUT CONTENT: The NEW-CONTENT-SIGNAL should be #t, set CURRENT-CONTENT to the supplied CONTENT overwriting the old content; NOTE: This shouldn't happen, we assume that the last written content will be READ before the next WRITE.
READ OUTPUT: return the content of the OUTPUT register, no other action is taken.
WRITE OUTPUT CONTENT: Update the BUFFOUT register block, update the OUTPUT register, if STAGED-INPUTS is empty send BUFFIN the empty register codon, if not send the first item in the STAGED-INPUTS; NOTE: This advances the BUFFIN register block by adding to its LIFO queue. Note that what was the oldest content in the input buffer is no longer available to the AGENT. If this content is likely to be needed, the AGENT must store a copy in working memory in order to be prepared for that contingency.
READ INPUT: Set NEW-CONTENT-SIGNAL to #f, updates BUFFIN register block, returns the CURRENT-CONTENT.
READ INPUT: NEW-CONTENT-SIGNAL should be #f, return the CURRENT-CONTENT.
October 26, 2020
%%% Mon Oct 26 14:49:19 PDT 2020
This entry recaps some of the discussion in yesterday's SAIRG meeting and provides a summary for those who couldn't join us. Prior to the meeting Yash sent around a revised perspective on his earlier executive homunculus missive and much of the meeting yesterday revolved around issues raised in that document. This footnote includes Yash's revised perspective with my comments interspersed, as well as the promised brief summary of the meeting16. The main text of this entry focuses on one set of issues that are particularly relevant to training our model. I've included Yash's overview of issues and challenges followed by my attempt to address those issues using register-machine compiler discussed in the previous entry.
YASH: In order to make sure that the model is able to generalize, it is necessary that the model be trained using a curriculum or a game. Unlike other models such as the DNC or NTM, this curriculum exists at the global workspace state level. We use a compiler and code generator that creates an optimal program to solve the current stage of the curriculum. This optimal program is then compared to the actual execution of the executive homunculus. For the earliest stages of the curriculum, where the model is only required to perform simple actions like moving or copying registers, the compiler can be used as a direct supervision signal to train the executive model. As the stages progress, the optimal programs can be used to verify the outputs from the executive model and provide a training signal that is more diffuse. In this way, the executive homunculus can be gradually trained to become more general. Initially, it is trained to perform simple actions whose rewards are dense. As it gains fluency with simple actions, the tasks become more complicated, and the reward signals become more sparse. The goal of the later stages is to train the executive model to compose the low-level operations it learned in the earlier stages to execute more involved tasks. At all stages of the curriculum, the compiler and code generator can be used to provide a training signal for the model. Note we directly train on the global workspace state here because the sparsity of the I/O reward signal would necessitate far too many trials before the model learns to perform any meaningful action. Even once it has learned to execute a task, it is likely that the final execution would be based on specialized operations that are not modular enough to generalize the execution. Instead of learning a general set of skills that are applicable to a variety of cerebral tasks, the model would have learned only to overfit to the current task. By using the curriculum and compiler as supervisors, we can ensure that the model builds up the tools needed to execute the tasks in a hierarchy.
TLD: To support curriculum training, compiler macros can be instrumented so as to generate training data for any task that can be characterized as a specific code fragment. Previous posts suggested that branch points serve to identify such fragments and the subroutines they could be used to train. In programs for solving a given task, branch points are signaled by conditional statements introduced by IF, COND and CASE, but also iterative constructs including FOR, WHILE, UNTIL, MAP and tail recursive functions. We've simplified this by allowing only IF statements and tail recursion, which are sufficient to implement all the others.
This strategy works at multiple levels in the hierarchy of subtasks. For example, in the two-pattern SIRtask there are three levels corresponding to three nested loops. The outermost loop (i) iterates over each item in the input to determine if it is the first character in a sequence matching one of the two patterns. Each character in the input sequence requires a (ii) loop over each pattern in the list of patterns to determine if the immediately-following characters match the pattern. Each pattern requires a loop (iii) over each character in the pattern to determine if the two sequences – one input and one pattern sequence – match where each sequence corresponds to a block of registers.
Finally, in each iteration of the innermost loop, the contents (characters) of two registers are compared and the resultant branching involves four cases determined by one or more loop exit conditions: (a) the pattern character is a stop (end-of-sequence) codon – output 1 and proceed to the next character in the input (return to loop i), (b) the two characters match – continue with the next pattern and input sequence characters (return to loop iii), (c) the two characters don't match and this is the first of the two patterns – continue with next pattern (return to loop ii), and (d) the two characters don't match and this is the second of the two patterns – output 0 and proceed to the next character in the input (return to loop i).
Miscellaneous Loose Ends: These three nested loops don't necessarily have to align with three different levels of abstraction. Recursion is the key innovation and it seems inherent in the way we learn just about anything. What about the challenges involved in maintaining a call stack of any depth? Registers serve as global variables [72] but they don't seem to serve particularly well in dealing with nested namespaces as is required in procedural closures. Items deep in the call stack would have to be allocated protected registers within working memory or depend on the variational autoencoder to learn to remember them along the lines of Wayne et al [145]. This footnote contains a redacted version of an email message that I sent to a friend in response to his question about McFadden's EMI field theory of consciousness17.
October 25, 2020
%%% Fri Sun 25 04:56:45 PDT 2020
There is now a working version of the register-machine compiler along with a set of macros that make it easy to write register-machine programs in Scheme (Lisp) that generate instructions to solve one- and two-pattern SIRtasks. In this case of the register machine, instructions correspond to register transfers. Here's what a Scheme program for solving two-pattern SIRtasks looks like:
(define (simple-sirt-inputRMC) (send BUFFIN registers))
(define (simple-sirtRMC pattern-list)
(or (empty? pattern-list)
(simple-sirt-auxRMC (simple-sirt-inputRMC)
(car pattern-list) (cdr pattern-list))))
(define (simple-sirt-auxRMC input pattern pattern-list)
(if (emptyRMC pattern)
(printRMC 'OUTPUT 1)
(if (equalRMC (car input) (car pattern))
(simple-sirt-auxRMC
(cdr input) (cdr pattern) pattern-list)
(if (empty? pattern-list)
(printRMC 'OUTPUT 0)
(simple-sirtRMC pattern-list)))))
In the above listing, emptyRMC, equalRMC and printRMC are implemented as Lisp macros and the other function names ending with RMC are simple Lisp procedures. On the surface, the three macros behave like the Scheme built-in functions empty?, equal? and printf, while at the same time producing side effects that generate the required register transfers:
(define-macro (equalRMC ARG1 ARG2)
#'(let ((input-one (send ARG1 read))
(input-two (send ARG2 read)) (flag (void)))
(send (operator-input-one COMPARE) write input-one)
(send (operator-input-two COMPARE) write input-two)
(set! flag (equal? input-one input-two))
(if flag
(send (operator-output COMPARE) write 1)
(send (operator-output COMPARE) write 0)) flag))
(define-macro (emptyRMC REGISTERS)
#'(or (empty? REGISTERS)
(send (car REGISTERS) empty?)))
(define-macro (printRMC FORMAT VALUE)
#'(begin (datalogRMC 'OUTPUT VALUE)
(if (not (equal? FORMAT 'OUTPUT))
(error "PRINTRMC macro expects FORMAT = OUTPUT")
(if (not (or (equal? VALUE 1) (equal? VALUE 0)))
(error "PRINTRMC macro expects VALUE = 0 or 1")
(send (send RMC select FORMAT 1) write VALUE)))))
If you are interested in playing with the implementation there is a tar file available here. To run the code, you'll need to download the Racket implementation of Scheme here and you'll also have to install the Beautiful Racket macro package – once you've installed Racket just type /Applications/Racket/bin/raco beautiful-racket-macro to a shell. Here are the first few lines from the output generated by a demo running the above program on a two-pattern SIRtask – the rest in this footnote18:
Welcome to Racket v7.7. > (require "Register_Machine_Macros.rkt") PATONE : 1 A X <<< The first 4 lines describe this problem and first 2 list patterns. PATTWO : 2 B Y BUFFIN : 1 Q 1 A 0 Z 2 B Y 0 <<< The input buffer (BUFFIN) was preloaded to run this demonstration. BUFFOUT : () STAGED : 1 1 A X W <<< BUFFIN holds 10 items maintaining this queue to handle extra input. BUFFIN : (Q 1 A 0 Z 2 B Y 0 1) <<< In the first iteration, item 1 is processed and BUFFIN incremented BUFFOUT : (? ? ? ? ? ? ? ? ? 0) <<< BUFFOUT routinely logs the items transferred to the OUTPUT register PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) <<< BUFFIN was preloaded and INPUT remains empty throughout this demo. OUTPUT : (0) <<< The OUTPUT register is 0 indicating the first item did not match. STAGED : (1 A X W) COMPARE : (1 2 0) <<< These three registers are associated with the comparison operator. CONJOIN : (? ? ?) <<< COMPARE checked for a match while CONJOIN and DISJOIN remain idle. DISJOIN : (? ? ?) BUFFIN : (1 A 0 Z 2 B Y 0 1 1) BUFFOUT : (? ? ? ? ? ? ? ? 0 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : (A X W) COMPARE : (Q 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) ...
Miscellaneous Loose Ends: I don't see any straightforward way of getting the current implementation of the compiler and register machine interface to solve AWK string substitution tasks. The program would have to look ahead at least the length of any sequence recognized by the provided regular expression that could be longer or shorter than the pattern specified to be replaced by the substitution sequence. Moreover, the length of the sequences recognized by the regular expression could be of arbitrary length even in the case of the simplest sort of regular expression routinely employed in AWK tasks, e.g., [0-9]+ or [A-Z]*. Even in cases in which there is a fixed-length sequence to be replaced, it may be necessary to provide an additional block of registers allocated specifically for scratch memory.
October 16, 2020
%%% Fri Oct 16 03:35:02 PDT 2020
This entry builds on the sketch of a register-machine compiler featured in the entry in this log by describing the implementation of such a compiler. It is a proof-of-concept version intended to make clear what I have in mind and perhaps serve as the impetus for one of you to build a more powerful tool using this design as a starting point. Having written much about the topic in this log, this entry is made relatively brief by leveraging several resources – some old and some new, summarized in a few figures.
The basic architecture that we have more-or-less settled on is built around a simple Turing-complete computational model called a register machine introduced here relating to our architecture, and illustrated in a revised version here. The register machine memory is divided into register blocks that serve to structure working memory along the lines of O'Reilly and Frank [98], making it more easily addressed and hence easier to learn. Figure 5 summarizes this block structure, providing examples of its implementation.
| |
| Figure 5: The register machine discussed the main text consists of six blocks of registers. Two of them buffer input and output character streams making it possible to solve problems that would be difficult or impossible otherwise. Two are used to store information required for solving particular problems including patterns of the sort required in SIRand AWK tasks. Another block consists of two registers, each capable of storing one character, and used to keep track of the most recent input and output characters. The last block contains the input and output registers used to temporarily store the operands and resulting products required for carrying out general-purpose primitive functions. The code listing above shows how object classes for register and pattern buffers are implemented in the Scheme dialect of Lisp. | |
|
|

The previous entry in this appendix sketches the design of a compiler that targets the register machine described above. As is common in programming language design, we use a dialect of Lisp to implement the compiler by leveraging the powerful Lisp macro package to alter the semantics of Lisp so we can write programs to solve AWK and SIRtasks that compile into assembly instructions that run on register machines. Figure 6 summarizes how macros are used in developing specialized languages, providing an example of the macros we've implemented for the register-machine target, and describing one way in which they can be used in training and debugging our differentiable register-machine code generator.
| |
| Figure 6: The expression shown above is a Scheme macro. Macros were originally developed in Lisp to make it easy to develop specialized programming languages and compilers for virtual machines. They also make it relatively easy to create novel syntax very different from Lisp syntax. The general form is (define-macro syntax body). The body of a macro is expanded to yield an expression that defines the function associated with a syntax pattern specified as the first argument. Since this expansion happens at runtime, macros can be thought of as another level of compilation. We use the same syntax as Scheme but alter the semantics to target a specified virtual machine. This makes it possible for us to write Scheme programs that compile into code that runs on a register machine and check that the result produced by the register machine matches that produced by the original Scheme program. | |
|
|

The expression (equal? (cadr input) (cadr pattern-one)) is typical of the code used to write programs that solve AWK and SIRtasks. Figure 6 lists a macro named equal that performs the same function as does equal? in the expression just mentioned, while at the same time executing register-machine instructions that carry out the function executed on a virtual register machine. The following trace shown on the left illustrates the use of equal and a display of the register contents following the execution of (equal (cadr input) (cadr pattern-one)). Entries shown as ? in the register dump indicate empty registers that were not assigned for purposes of this simple demonstration. The listing on the right shows a solution to the SIRtask and its execution with the initial input-buffer set to (1 Q 1 A 0 Z 2 B Y 0 1 1 A X Q) and patern-list set to ((1 A X) (Q) (2 B Y) (3 Q 7 W)):
> (define input (send BUFFIN registers)) | (define (simple-sirt pattern-list)
> (define pattern-one (send PATONE registers)) | (or (empty? pattern-list)
> (send (cadr input) write 3) | (simple-sirt-aux input-buffer
> (send (cadr pattern-one) write 3) | (car pattern-list) (cdr pattern-list))))
> (equal (cadr input) (cadr pattern-one)) |
OUTPUT = 1 | (define (simple-sirt-aux input pattern pattern-list)
| (if (empty? pattern)
> (send (cadr pattern-one) write 5) | (printf "~a " 1)
> (equal (cadr input) (cadr pattern-one)) | (if (equal? (car input) (car pattern))
OUTPUT = 0 | (simple-sirt-aux
| (cdr input) (cdr pattern) pattern-list)
> (dump-register-machine) | (if (empty? pattern-list)
BUFFIN : (? 3 ? ? ? ? ? ? ? ?) | (printf "~a " 0)
BUFFOUT : (? ? ? ? ? ? ? ? ? ?) | (simple-sirt pattern-list)))))
PATONE : (? 5 ? ? ? ? ? ? ? ?) |
PATTWO : (? ? ? ? ? ? ? ? ? ?) | (do ((i 1 (+ i 1))) ((= i 14))
INPUT : (?) | (simple-sirt pattern-list)
OUTPUT : (?) | (set! input-buffer (cdr input-buffer)))
COMPARE : (3 5 0) |
CONJOIN : (? ? ?) | 1 Q 1 A 0 Z 2 B Y 0 1 1 A X
| 0 1 0 0 0 0 1 0 0 0 0 1 0 0
Consider what may happen as a result of executing the expression mentioned above. If (cadr pattern-one) is equal to the default-empty-character (?), then the pattern match succeeds and the system should output a sequence of 0's of length (- (length pattern-one) 1) and then output a 1 thereby consuming the matching segment of input, where the 1 indicates the end of the matched segment of input. If (cadr input) is not equal to either ? or (cadr pattern-one), then the (pattern) match fails and the system should do one of two things: if there exists a second pattern (PATTWO) then the input should return to the head of input and the search for a match should commence with the second pattern bound to (send PATTTWO registers).
October 11, 2020
%%% Sun Oct 11 05:43:43 PDT 2020
In the previous section we discussed how a register-machine compiler could facilitate training and testing by generating unlimited training data for learning differentiable models that solve SIRand AWK tasks. It would also come in handy in debugging models and facilitating curriculum learning. As mentioned earlier such a compiler will be useful – possibly essential from a practical perspective – whether we use reinforcement learning or supervised learning to the train our models. The remainder of this entry provides a sketch of how one might go about building such a compiler.
Register Machine Classes
The following is a very rough sketch of how you might go about building a register-machine compiler for generating training and testing data for the model we have been talking about. I've used Scheme in the following to illustrate the basic steps, but you could just as easily use some other functional programming language like Scala or a high-level, object-oriented scripting language like Python. Here are some of the basic object classes for the implementation that I have in mind. You might have some very different ideas – as I said, this is a very rough sketch.
;; Recursive-function register machine [Minsky, 1961] ;; Layout of registers comprising working memory
(define RegisterMachine% (define RegisterMemoryMap%
[class object% [class object%
(init memory-map ... ) (define/public (read-from-register key) ... )
(super-new) (define/public (write-to-register key) ... )
(define/public (transfer source sink) ... ) ]) (define/public (erase-register-content key) ... ) ])
;; Registers capable of storing one embedding vector ;; FIFO register buffers for patterns and I/O
(define Register% (define Buffer%
[class object% [class object%
(define/public read-from-register ... ) (define/public enqueue ... )
(define/public write-to-register ... ) (define/public dequeue ... )
(define/public erase-register-contents ... ) (define/public clear ... )
(define/private empty? ... ) (define/public empty? ... ) ])
(define/private locked? ... ) ])
;; Equality predicate plus Boolean functions
(define Operator%
[class object%
(define/public write-to-input-1 ... )
(define/public write-to-input-2 ... )
(define/public read-from-output ... ) ])
Register Machine Compiler
The compiler takes as input a program written in Scheme – see Figure 21 for examples – that implements a solution to a SIRor AWK task and generates as output machine code for a register machine [85]. The compiler is also written in Scheme and essentially single steps through the Scheme code implementing the solution to the SIR/AWK task generating machine code for the register machine one expression at a time.
There are two events that signal branching: (i) the result upon performing an equality check, and (ii) arriving at the end of a pattern sequence – essentially satisfying the termination condition for a loop or recursion. Barring intervention by its superordinate, every pass through the first-level network results in one action corresponding to a single register transfer. You can think of the compiler as evaluating a sequence of expressions of the form (subexpression 1) ? (subexpression 2) : (subexpression 3) (using the ternary operator to highlight the relative uniformity of each stage) such that working memory is updated following each subexpression and the ? is resolved by inspection of the resulting working memory contents.
Calling it compiler can be a bit confusing for the uninitiated. It behaves like a compiler insofar as it generates machine code for a register machine. On the other hand, it behaves like an interpreter in that when it arrives at a conditional branch instruction it only compiles the branch on which the condition is true, and every time it returns to the same location in the source code it has to recompile whatever branch is dictated by the branch condition, possibly compiling the same instructions many times. This is essentially the behavior you would expect of a just-in-time compiler (JIT)19).
Compiler Execution Macros
Building the register-machine compiler is relatively simple. We assume that in the case of Scheme or Lisp you restrict yourself to the following primitives: IF (COND), FIRST (CAR), SECOND (CADR) and REST (CADR). If you prefer, you can use just the parenthesized primitives and use any dialect of Lisp, or you can use just the primitives that are not parenthesized, and use a modern dialect of Scheme such as Racket.
Having implemented the high-level code for solving SIR/AWK tasks, the easiest way to implement the compiler is to write macros for each of the primitives to generate the corresponding register transfers and update the RegisterMachine to provide working memory snapshots that can be used to train or test the differentiable register machine implementing the neural-network model that we are now working on. Lisp is well suited for this task since it has a powerful macro package that makes it easy to define new syntax, develop compilers and create virtual machines supporting new languages.
October 7-9, 2020
%%% Wed Oct 7 04:54:47 PDT 2020
In this entry we consider the interaction between level I (L1) and level II (L2) components. In particular, there are prescriptive components that Merel et al refers to as modulatory control layers, proprioceptive components that correspond to kinesthetic awareness in robotic applications, predictive components that among other things deal with the partially observable characteristics of the underlying Markov model, and executive control components that are also modulatory, providing, for example, the means by which level III (L3) provides high-level direction to L2.
The actions that comprise the L1 primitive action space in our model correspond to register-to-register transfers, and while there are a finite number of distinct such transfers, their internal representations are continuous and are invoked by using a differentiable neural computer functioning as a lookup table. A similar arrangement is used by L2 to select a subroutine corresponding to a compiled sequence of L1 primitives. These subroutines constitute the L2 action space and correspond to the L2 primitives.
Both L1 and L2 networks employ state representations corresponding to compressed summaries of the contents of working memory as the means of selecting actions for execution. This approach is analogous to the way in which the basal ganglia construct and gate modulated summaries of information collected from throughout the cortex and especially sensory association areas in posterior cortex as a means of providing a context for action selection in the primary motor cortex. The intention in both cases is to provide guidance but ultimately cede control to the corresponding action selection machinery.
We refer to these compressed summaries as action signatures as they serve a similar purpose as function type signatures in programming languages. Since the signatures defined at each level depend on the examples used to train the primitives at that level and the network responsible for action selection is likely to encounter states that it has never seen before, it important to be able to map novel states to familiar ones in applying primitives. This is analogous to the need to interpolate between points in joint-angle (configuration) space in order to compensate for the sparsity of the motion capture training data in Merel et al model.
| |
| Figure 7: The right panel shows the network architecture in Figure 9 masked to highlight the lowest level L1 in the hierarchy. Since training the overall architecture proceeds one level at a time, the first stage of training would focus exclusively on this subnetwork. The left panel shows a simplified rendering of L1 and its parent L2 to accompany the discussion in the main text relating to the interaction between adjacent levels in the hierarchy. Four components of that interaction are annotated as follows: E – executive control modulatory input from L2's superordinate L3, S – system state corresponding to a compressed summary of the contents of working memory, P – proprioceptive input highlighting changes in relevant system state the including the source and destination for the last register transfer, and T – an encoding of the action generated by L2 translated into the language of L1 by the L1 / L2 coding-space interface. Note that, as illustrated on the right, all three levels of the hierarchy have access to the entire state vector corresponding to a compressed summary of the contents of working memory. The graphic on the left simplifies this structure to highlight key inputs and outputs that are discussed in the main text. | |
|
|

Since the language employed by the superordinate is different from that of the subordinate – for the purpose of this discussion the former is a superset of the latter, there needs to be an interface that translates instructions coded in the language of superordinate to that of the subordinate – obviously with some loss of information. This interface serves much the same role as the coding space in Merel et al. The coding space enables a superordinate network to call subroutines that are executed by its subordinate network and compiled from subordinate's primitives – see Figure 7.
In addition to the language interface mentioned above, every level in the hierarchy has read access to the entire working memory; however, superordinate levels have exclusive write privileges to specific registers that are designated for communicating with their respective subordinate levels – see the discussion of wA, wB and wC in Figure 9. In the model described here, the superordinate uses those registers to modulate the behavior of the subordinate and, in particular, enable the subordinate to differentiate between tasks.
Knowing the task is essential, since the part of working memory used to store state information relevant to performing tasks does not uniquely identify the current task. In the current model, working memory registers consist of four, equal-length register banks dedicated to storing character strings. Two of the banks are used to buffer the input and output. The other two banks are dedicated to storing patterns for one- and two-pattern SIRtasks and storing simple regular expressions and replacement strings for find-and-replace AWK tasks. A two-pattern SIRtask can easily be mistaken for an AWK substitution task.
%%% Thu Oct 8 5:40:05 PDT 2020
As Chaufei pointed out, Merel's motor-control task and SIRT involve planning, execution, error correction in each level of the hierarchy. I like O'Reilly's characterization of the division of labor between the basal ganglia and cerebellum,"where the basal ganglia help to select one out of many possible actions to perform, and the cerebellum then makes sure that the selected action is performed well." Randy notes20 that "there are no direct connections between the basal ganglia and cerebellum – instead, each operates in interaction with various areas in the cortex, where the action plans are formulated and coordinated."
I excerpted the relevant passages from the latest edition of CNN and included them here for your convenience. The authors compare the cerebellum and hippocampus in terms of shared cytoarchitecture, neural circuitry, learning signal and dynamics, noting that in terms of dynamics both rely on pattern separation to differentiate between similar inputs and the hippocampus exploits attractor dynamics whereas the cerebellum does not. They note that, "while the cerebellum does not generalize to novel input patterns particularly well, it may be better overall in motor control – and, I would suggest, executing register transfers – to avoid improper generalization".
%%% Fri Oct 9 04:49:08 PDT 2020
I'll try to put together a short list of recent technology advances relating to error correction before Sunday, but that may have to wait until next week. In the meantime, below is a list of subproblems that we may or may not have to solve depending on exactly how we define and scope the overall problem, and, following that, an attempt to describe for what I believe to be the two most promising approaches to solving subproblem #1.
learning L1 primitives (operators)
compiling L2 subroutines21 (fragments)
L1 error identification and correction
L1 / L2 coding-space training
L1 / L2 signature interpolation
learning L2 primitives (programs)
Regarding subproblem #1, I see two contenders for training the model that I'll refer to as the gamification and compilation approaches. As I understood the tentative, perhaps weak, consensus coming out of last Sunday's meeting, we were leaning toward the gamification alternative. To make sure we agree on exactly what these alternative approaches are and what they have to offer, I'll describe each approach and solicit your help in correcting my account.
The compilation approach is the one I suggested several months ago and amounts to writing a register-machine compiler that takes as input a program represented as a recursive function written in a simple functional language like Scheme and the memory layout for a register machine and logs a trace of the program running on the register machine that includes every register transfer and a snapshot of the memory before and after the transfer.
The compiler could generate as much data as we need. Using the debugger trace utility we could generate traces of any subexpression in the scheme code, e.g., loading the operand registers of the comparator operator to test if a pattern character matches the current character in the input-register and writing the correct response to the output register. The compilation approach allows us to use supervised learning.
The gamification approach involves using reinforcement learning and is one way of automating curriculum learning. The idea is to create a game that has multiple skill levels – like Dungeons & Dragons – such that each level requires solving more difficult problems than in the levels below. Rewards accrue from solving a wide variety of problems. Problems featured in earlier levels continue to come up in later levels but receive less reward.
Unlike chess, failure to achieve a particular skill – like acquiring a powerful talisman in Dungeons & Dragons, does not prevent you from getting rewards (points) along the way, though you may not graduate to the next level. On the other hand, forgetting a skill may increase the number of opportunities to learn the forgotten skill in the current level or simply return you to an earlier level to allow you to focus on reacquiring the lost skill.
Miscellaneous Loose Ends: The gamification approach – or any curriculum-learning-based approach for that matter – will entail generating a lot of data starting with relatively simple problems like the pattern-input-comparison example mentioned above and then graduating to more challenging problems. The technology described for the discussion of the compilation approach could greatly simplify generating such data.
October 3, 2020
%%% Sat Oct 3 09:12:43 PDT 2020
Following up on yesterday's post about why it is difficult to generalize sequences of register transfers that work in one situation to work in another, this entry suggests some strategies for making it easier. In the brain, this problem hardly ever arises because data sources and sinks are memory mapped, computations are performed in place, and connections between circuits only exist in those cases where it it is important to carry out some computational task useful to the organism [90].
In this (equal? input (first (rest pattern))) simple Scheme expression, the variables input and pattern refer – or point – to the contents of two locations in memory.22. The existence of these locations, as well as the registers used in comparing the arguments of the equal? invocation, are simply assumed by the programmer. Rather than having to remember the location in which the value of a given variable is stored in order to gain access to or modify that value, we rely on the operating system to do the bookkeeping for us. The value of a variable depends on its current context – or lexical closure – and hence is at all times unambiguously defined even if its location in memory changes.
In our model, some register assignments are functionally specific; these include I/O registers and all of the input and output registers associated with neural circuits that perform comparisons and other basic utilities. Some are regionally constrained, e.g., registers reserved for patterns and input and output buffers. We could structure the content of patterns and buffers further by representing each one as a sequence of N distinct registers, each sequence capable of storing a single pattern or buffer of length K with shorter sequences padded by one-hot STOP codons.
In the following examples, we assume that the layout of working memory is highly structured as discussed above. In particular, working memory includes two dedicated pattern buffers, dedicated input and output buffers and that all buffers have the same capacity and are wiped (each entry replaced by a NOOP codon) whenever the task changes. This layout should suffice for one and two, variable-length-pattern SIRtasks as well as simple substitution AWK tasks with or without wildcards. Given this arrangement, how does the system know where it left off?
Suppose that the source ("from" register) and sink ("to" register) of the last register transfer is available in some form, perhaps in the first attentional subunit of a transformer decoder stack – consisting of a masked multi-head self-attention layer and a point-wise, fully connected layer – so that, for example, if the source is the third character of the first pattern and the sink is the register of the second operand of the comparator, the model should expect that the output register contains a 1 (or some Boolean equivalent) if the current input character matches the third character of the first pattern and zero otherwise.
If the match succeeds, the next step is to (i) advance to the 4th alphanumeric character of the first pattern if one exists, otherwise (ii) the 4th entry in the first pattern buffer must be a STOP codon and the system should output a 1 signaling a successful pattern match and advance to the next input character. To simplify the discussion here, we ignore the problem of updating the input and output buffers; in the implementation we could finesse this problem by either choosing patterns that don't share any characters or automating the management of both buffers.
If the match fails, the next step is to (i) advance to the first character of the second pattern if one exists, otherwise (ii) output a 0 signaling that the current character is not the first character of a pattern and advance to the next input character. Note that it is possible the "current" input character could match, say, a three character pattern and the "next" input character could match the same or another pattern. In fact every character in the stream could be the first character in a pattern, e.g., every character but the last in the input stream, "AAAAAA", matches the pattern "AA". This is the reason it is necessary to buffer the last K input characters.
Originally I assumed that we train the bottom level on SIRtasks, distill subroutines from this and then train the next level to use those subroutines to solve both SIRand AWK tasks. However, I think it makes more sense to train the bottom level on subproblems of both SIRand AWK tasks, distill subroutines from this training and then train the next level to use these more diverse subroutines on complete SIRand AWK tasks. In this approach, the bottom level is encouraged to differentiate between using pattern buffers to match sequences and using them to store substitutions which is necessary when faced with a mix of SIRand AWK tasks.
These observations led me to think more carefully about identifying general-utility reusable sequences of low-level (register transfer) primitives, determining their applicability and adapting them to new situations on the fly as well as methods for composing such primitives in the parent level. As per earlier discussions, perhaps the best way to combine primitives is to adjust their signature context by masking or annotating a composite view of the current contents of working memory. It is also worth noting that one of most useful methods for composing primitives is to embed them in a loop or recursive function.
Miscellaneous Loose Ends: Chaufei made a number of interesting observations in responding to this post23. Here are some excerpts interleaved with my replies:
FAN: I think it would be interesting to think about how we can formulate the SIRT solver with some error correction mechanism.
TLD: I agree wholeheartedly. I think we are being drawn inexorably toward recapitulating the strategies employed in controlling movement and applying them to "thinking". In hindsight, we shouldn't be surprised given that cognitive reasoning evolved on top of a sensory-motor foundation and natural selection seldom invents anything new if an existing solution serves.
FAN: ... in general cases like the abstract reasoning task we talked about before ... the algorithm to read the input tape forward and backward multiple times may make the problem easier to solve ...
TLD: I like the notion of reading the tape backward and forward – it would serve much the same purpose as integrating an imagination-based MCMC lookahead component into a planner and reminds of what Lauren Frank described in his class lecture on the role of sharp-wave ripples in planning and decision making ... see Lauren's recent review paper [65] ... the cerebellum appears to use similar methods and the role of the cerebellar cortex in cognitive tasks is now well established ... see Randy Buckner's recent survey [17];
%%% Thu Oct 1 04:59:53 PDT 2020
What are the advantages of the problem that Merel et al solve in comparison with the SIRT problem? For one, the proprioceptive state defines the state of the body. All by itself, this doesn't determine the complete state representation – in addition to knowing all of the joint angles, the next action depends upon the task. The low-level task in Merel et al is specified as a forward trajectory corresponding to the desired near future path of the body, xt. Interpolation serves to smooth and complete the space filling in gaps in the motion capture data. The high-level task and the targeted near-future-path plus the proprioceptive state completely determine the next action.
Aside from the transparency of the state, the most important advantage in the case of the motor control task is that it is "forgiving", that is to say small errors in movement can be easily quickly identified and corrected on the fly so that errors don't accumulate and, at least in the case of the higher-level tasks described in the paper, the errors that do occur tend not to have catastrophic consequences.
In the case of SIRT problems, the vector of the current contents of working memory does not in and of itself determine the next action to take. This choice depends upon the current problem, the way in which the problem is represented in working memory and the algorithm that the system was taught to follow by observing traces of that algorithm in the process of solving instances of the current problem. We could, of course, try to train the model to adapt to novel circumstances, but this seems a stretch as it is not even clear how we could construct a representative sample for learning. Moreover, it seems likely that it will be challenging just to train a model to span the entire space of SIRtasks with different pattern lengths, multiple patterns and different algorithms for solving such tasks.
In SIRtasks, failures are often silent, their consequences can be fatal, appear long after they occur and be difficult to diagnose. I'm not convinced that it would make much of a difference if we use reinforcement learning or supervised learning to train the model – but I'd love to be shown otherwise. As far as I can tell, the only strategies that hold much promise involve dealing with partial observability by using more powerful attentional or predictive models or by enhancing the state vector with annotations that disambiguate the context and so narrow the possible actions at each stage. Another possibility is to invoke some form of imagination-based planning to search ahead and anticipate problems, but this probably won't work either if the consequences of a poor choice are only apparent after a long delay and even then require careful checking to identify and correct the problem.
I'm not by any means giving up, but I am interested in exploring new ways of simplifying the problem to avoid some of the problems described above. One thing to point out is that versions of the SIRT problem that include multiple patterns are considerably more difficult than those that only include problems with varying lengths of single patterns. The multiple pattern problem requires buffering the input if the strategy is to serially evaluate one pattern at a time or, if the intention is to evaluate only one pattern at a time and not buffer the input, then all of the patterns have to be evaluated in parallel requiring a somewhat more complicated method for testing patterns. In thinking about the challenges, I find it helpful to consider two classes of tasks, and imagine that we train the first level of the hierarchy with the SIRtasks and the second with AWK tasks:
The class of one and two variable-length pattern SIRtasks;
The class of find & replace AWK tasks with or without wildcards;
September 25, 2020
%%% Fri Sep 25 05:17:10 PDT 2020
Met with Rishabh on Tuesday and told him about the hierarchical model featured in the previous entry in this log. He provided lots of useful feedback and in particular suggested the two papers that proved to be both relevant and generally interesting to know about. In Tuesday's meeting I was primarily hoping for a sanity check on the general approach that we are discussing. In this log entry, I address the problem of how to identify and package subroutines so that they are callable by upstream networks. In the following, I will unpack the three italicized terms in the previous sentence.
Consider two adjacent levels in the hierarchical stack described in Figure 9. In the following, we refer to the higher, more abstract (parent) level as the superordinate level and the lower, less abstract (child) level as the subordinate level. Each level has an associated set of primitives that we refer to, respectively, superordinate primitives and subordinate primitives. Each level is responsible for selecting and executing its respective primitives. The superordinate primitives correspond to compiled subroutines that consist of sequences of subordinate primitives. To simplify the terminology in the remainder of this discussion, unless qualified we use the word subroutine to refer to the superordinate's primitives and reserve the word primitive to refer to the subordinate's primitives. In the case of the lowest level in the hierarchy, its primitives correspond to register-to-register transfers.
By identify, I mean that the sequence of primitives at any level is segmented into potentially reusable subsequences that are likely to apply in a wide range of tasks. These potentially reusable subsequences are unlikely to be directly useful in novel situations. For example, in the case of the sequence of loading the operand registers corresponding to a particular comparison operator, the target registers are obvious but the source registers are likely to vary. As a consequence, the execution of such sequences requires taking advantage of contextual clues in the current state vector of working memory contents. In general, the superordinate has to rely on the subordinate to adapt to circumstances in executing a subroutine. In this manner, each level in the hierarchy takes on some of the responsibilities generally attributed to the cerebellum24.
By package, I mean the process whereby a given level compiles sequences of its level-specific primitives and organizes these sequences so as to facilitate its parent in selecting from among them. Barring interference from its parent, on every level-specific execution cycle, each level in the hierarchy selects and executes one of its primitives. For example, this process might entail encoding each such sequence in an embedding vector and storing it in a lookup table (DNC) indexed and made accessible through the coding-space interface described in Merel et al [84]. Figure 8 provides a simplified sketch of the model.
By callable, I mean that the superordinate can appropriately select and then execute a subroutine relevant in the current state. This might be facilitated, for example, by employing a query for the lookup table referred to in the previous paragraph. The query would constitute summary abstraction of the current state, such as a vector of compressed working memory registers, that would serve as a context in which executing the level-specific subroutine is appropriate. The execution of a subroutine could then be carried out by using a decoder stack trained to recover the sequences of primitive operations native to the subordinate and execute them one at a time. The superordinate would have access to the full collection of subroutines inferred from those primitives through the lookup table.
| |
| Figure 8: A simplified sketch illustrating the main functions involved in segmenting primitives in the subordinate level L1, packaging them as key-value pairs in a lookup table and then making them available as subroutines to the superordinate level L2. Note that the subroutine being constructed (pink rectangle with rounded corners enclosing three scroll-like rectangles) is shown depicting the subroutine as a sequence of actions. While conceptually accurate, actions are referenced by their signatures which are state vectors corresponding to compressed representations of the contents of working memory. The signature of an action determines its conditions for application and serves as a key for selecting the action in a given context. The key for a subroutine is the signature of the first action in the sequence of actions that defines the subroutine. | |
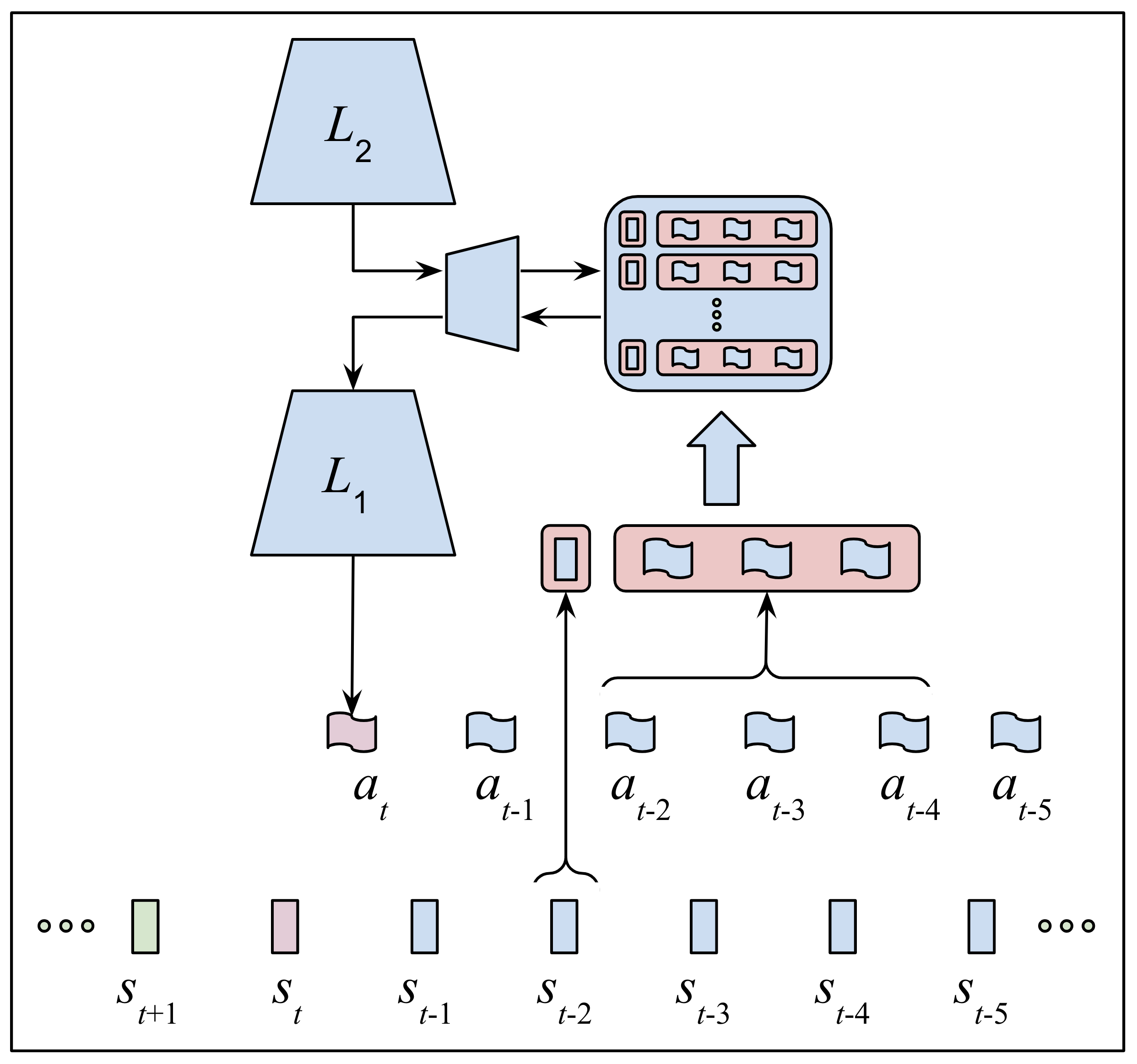
In thinking about these issues I was reminded of the fully-differentiable procedural abstractions that Rishabh and I talked about when I was still at Google. We conceived of those abstractions as graph networks representing the abstract syntax tree of the target procedure in which all of the tokens are one-shot embedding vectors and execution of the procedure was carried out by walking the graph in depth first order with conditional branches for recurrently entering the graph in the case of implicit recursive calls or explicit looping constructs.
This strategy required that the scope of specific named variables be handled appropriately, and to deal with this we assumed the use of a DNC to serve as a differentiable LIFO call stack. In this case, we simply leveraged the abstractions inherent in the source code and so our focus was on turning a conventional program into a differentiable abstraction that could be used to repurpose the program's constituent procedures. I still think this idea has merit, but I don't think that it has the same benefits as the strategy we are pursuing in the current work due to our ability ground learning in the virtual environment of the register machine abstraction.
%%% Sat Sep 26 6:00:53 PDT 2020
The process of segmenting a sequence of subordinate primitives to extract superordinate subroutines is complicated by the fact that a sequence of such primitives may include branches that, while the subsequence of primitives prior to the branch may be relevant to the superordinate’s objective, the primitives following the branch were dictated by the particular branch conditions encountered in the trace being mined for subroutines. For example, loading the operand registers of a comparator and computing the result corresponds to a potentially useful sequence for defining a subroutine. However, extending that sequence to include the next register transfer may not be appropriate if the result in the initial sequence differs from that obtained if executed in a sequence corresponding to a superordinate subroutine.
But neither is it the case that all branch conditions are sufficient cause for terminating the candidate sequence intended for a superordinate subroutine. For example, a common task relevant to the class of problems we aim to solve in this project involves checking a stored pattern against a sequence of input characters. Completing this task requires stepping through the alphanumeric characters in the stored pattern, comparing each one to the next input character and stopping when either the match fails or the end of the pattern is reached as signaled by the character immediately following the pattern turning out to be the special end-of-pattern character.
These complications in identifying good candidates for subroutines are inevitable given that our knowledge of the computations that gave rise to the sequence of primitives in which we are searching for such candidates is limited to the execution traces of an implicit program that we don't have access to and would be hard-pressed to derive from the execution trace alone. In any case, in our initial experiments we can follow the example of Merel et al [83] and perform the search for candidate subroutines offline. Another potential problem involves the possibility of ending up with a set of subroutines that have gaps between them making it impossible to string together a sequence of subroutines able to solve novel problems such as the AWK tasks discussed earlier.
%%% Wed Sep 23 07:31:16 PDT 2020
Here are my notes from the meeting with Rishhabh on Tuesday. The policy distillation method mentioned by Josh in his motor control papers [83, 84] was designed for robot control, but the basic concept of inferring sequences of micro actions – small joint angle changes in Josh's application and short sequences of register transfers in our case – and then using RL to learn a deployment policy and coding space directly applies to learning the lowest abstraction level in our proposed hierarchical model.
Josh et al used the method described by Mordatch et al [92] describing it as "a technically impressive and insightful demonstration that neural networks can effectively distill multiple movements for amortized reuse." Igor Mordatch's presentation at NIPS 2015 talking about his paper on distilling policies from collections of optimized control sequences. Wang et al [142] describe an interesting multimedia graphics application that uses the method described in Mordatch et al.
Rishabh suggested that the method of learning discrete latent spaces developed by van den Oord et al [132] might be well suited for implementing the coding space interface(s) separating levels in our proposed hierarchical model. More generally it looks like it offers an interesting technology that might be useful in any number of applications including the SIRT problem. Aäron van den Oord's presentation provides a nice explanation of the method.
Shashank Yadav's blog posting sketching the basic VQ-VAE architecture and training algorithm is well worth a look. I've included relevan excerpts in the footnote, but encourage you to read the entire posting for Shashank's analysis25. Sigrid Keydana and his colleagues have developed an implementation of VQ-VAE that looks promising if you want to experiment with this technology26.
September 19, 2020
%%% Sat Sep 19 15:22:21 PDT 2020
Motivated by Yash and Gene's concerns about generalization and training data I've been thinking about how to exploit hierarchical structure to reduce training time. There are a lot of ideas out there for harnessing hierarchical structure and we discussed many of them in the course notes. I rediscovered a few more related papers in scanning my class notes.
The neural program interpreter described by Reed and DeFreitas [110] is interesting but not nearly as general as would be needed for our SIRtask problem. There is also a paper out of Francesco Donnarumma's lab that came out about the same time as the NPI paper and is closer to what we have in mind and is intended to shed light on the role of the prefrontal cortex [33].
However, both of these examples fall short of our goals and I think the model we are working on is more general and more interesting from a practical standpoint. My liberal use of computer architecture analogies is not going to win us any advocates within the neuroscience community, but that is not the audience that we're looking to impress. The following account focuses on the use of hierarchy to reduce search and facilitate generalization.
The diagram shown in Figure 9 is a bare-bones architecture that illustrates the main advantages of the concept I have in mind. I've suppressed the details of the Transformer-based architecture we talked about last Sunday in order to focus on two important capabilities necessary to support the class of models I have in mind.
In the figure, you see a stack of three multi-layer recurrent networks each one responsible for one level of abstraction in the proposed model. This organization reflects the motor stack in Fuster's hierarchy with the most abstract on the top and the least abstract on the bottom, and forward propagation running opposite that of the complementary sensory stack. The three levels communicate with one another by updating the proxy state vector corresponding to the current contents of working memory.
Each level has an annotation layer that relies on the output of the corresponding level-specific attentional layer in order to augment the state vector so as to provide the context for selecting the next instruction to carry out. For example, in the lowest level concerned primarily with register transfers, the annotation layer would identify, but not differentiate the source and destination registers for the next transfer.
Output of the annotation layer feeds into a policy layer that selects and then applies the indicated instruction. Continuing with the previous example, the policy layer differentiates the source and destination registers and initiates the register transfer by propagating an appropriate control vector to the DNC controller (referred to as the register switchboard in earlier posts) responsible for carrying out such transfers.
| |
| Figure 9: The above graphic represents a simplified version of the hierarchical model described in this posting. The architecture shown here and explained in the main text features three multi-layer recurrent networks each one responsible for one level of abstraction in the proposed model. Not shown are the attentional layers inherited from the model shown in Figure 12 or the annotation and policy layers introduced in the main text. | |

The expectation is that the entire stack will be trained one level at a time from the bottom up, using a curriculum learning protocol that uses increasingly longer execution trace fragments. Think of the bottom level as implementing assembly code instructions, the middle analogous to the built-in functions in a high-level programming language, and the top to application programs written in that language.
To distinguish between the different executable functions learned in each level of the hierarchy illustrated in Figure 9, we use the following italicized terminology:
Primitive Operations (assembly instructions): REGISTER_REGISTER_TRANSFER, BRANCH_ON_COMPARATOR_OUTPUT and READ_INPUT_FROM_REGISTER;
Utility Subroutines (built-in functions): ENCODE_SEQUENCE_AS_CHUNK, DECODE_CHUNK_AS_SEQUENCE and COPY_INPUT_SEQUENCE_TEMP,
Complete Procedures (stand-alone programs): SIR_TWO_PATTERN_Y23_Z56_TASK, DELETE_FIRST_OCCURRENCE and SUBSTITUTE_ALL_OCCURRENCES
Network A is responsible for implementing a set of primitive operations to perform sequences of register transfers to move information between major divisions in working memory. Network B combines these primitives to define subroutines that transfer sequences of input to specific locations in working memory as in the case of storing the patterns define a new SIRtask.
Finally, network C combines the subroutines in B to learn procedures that solve new SIRtask instances that deviate enough from previously learned instances that they require a substantially different algorithm. For example, this might involve learning to solve multi-pattern SIRtasks by encoding character strings as embedding vectors.
We've already discussed the first of the two properties mentioned above, namely how does each level keep track of where it is in the running program. For the lowest level this is essentially the problem of maintaining an instruction counter. For the other two levels this involves operations that are normally handled by the procedure call stack, but the idea is similar.
The proposed solution for the top two levels is the same as that for the lowest, namely that the state vector is augmented with annotations–represented in Figure 9 as small triangular flags– identified by attentional layers. These annotations serve a similar purpose as the mnemonic affordances that animals use to compensate for the fact that their environment is partially observable [145, 48].
The second of the two properties involves the way in which the top two levels invoke computations corresponding to, respectively, utility subroutines and primitive operators in their immediately subordinate levels. Each of the three levels has an associated region of working memory, labeled, respectively, wA, wB and wC in Figure 9, that you can think of as a function namespace for the associated level. Region wC assumes an absent parent for Level C.
These dedicated regions serve the same purpose as the coding space of Merel et al [83] in which the authors explain that the "coding space, zt, comes to represent each of these movements" – analogous to the primitive operations in our model, and that downstream of this coding space" is a motor policy that when cued with zt and proprioceptive information" – the contents working memory in our case, "is able to generate patterns of human-like movement" – analogous to our utility subroutines, and that upstream of this low-level system is a high-level controller that produces actions of the same size as the coding space and is trained by reinforcement learning to solve problems difficult for non-hierarchical models.
September 17, 2020
%%% Thu Sep 17 04:57:17 PDT 2020
In my continuing efforts to convince you–and me–that the SIRtask (SIRT) problem is tractable, I searched through some recent papers out of Pieter Abbeel's group and ran across a reference to some robotics work going on at OpenAI in which a real robot interacting in a real environment learns how to stack blocks in one-shot from a single VR demonstration [35].
The problem has several interesting parallels with respect to the difficulty of the task and the strategies that we are pursuing for the SIRT problem. The basic architecture consists of two networks: a vision network and an imitation network. The imitation network is trained by presenting it with two demonstrations, each one corresponding to a trajectory of actions solving a specific instance of block stacking. See Figure 10:
Each training example is a pair of demonstrations that perform the same task. The network is given the entirety of the first demonstration and a single observation from the second demonstration. We then use supervised learning to predict what action the demonstrator took at that observation. In order to predict the action effectively, the robot must learn how to infer the relevant portion of the task from the first demonstration.
| |
| Figure 10: Here is the architecture for one-shot imitation learning from Figure 2 in [35]. | |

The vision network is trained using domain randomization [128] a method originally developed for the task of object localization, whereas our task and that of the OpenAI robot is to infer the next action / instruction from the task trajectory / program trace and state vector / working memory contents:
The imitation network uses soft attention over the demonstration trajectory and the state vector which represents the locations of the blocks, allowing the system to work with demonstrations of variable length. It also performs attention over the locations of the different blocks, allowing it to imitate longer trajectories than it's ever seen, and stack blocks into a configuration that has more blocks than any demonstration in its training data.
In addition to the obvious analogies noted above, i.e., "next action" for "instruction", "task trajectory" for "program trace" and "state vector" for "working memory", the "attention over the locations of different blocks" is roughly analogous to our proposed use of a spatial hierarchy in attending to activity in the pattern, program and I/O memory blocks that comprise working memory in service to updating the instruction counter.
September 15, 2020
%%% Tue Sep 15 04:37:19 PDT 2020
In the following we consider a proposal for introducing an inductive bias as a positional encoding / hierarchical attentional model inspired by MERLIN's use of a variational auto encoder as a predictive model for addressing the challenges raised by partial observability [145]. How does positional coding help in question answering, speech recognition, language translation, text summarization or object recognition? How might we learn and apply such an embedding?
There is no free lunch for machine learning. There is no general method that is guaranteed to generalize beyond the data. There are heuristics like Occam's razor and Bayesian priors that can be used to bias search, and domains in which specialized techniques like interpolation and Monte Carlo simulation work well, but there are no guarantees. There also exist domains having structure that can be relatively easily discovered and exploited.
Psychologists distinguish between sequential (temporal) attention and proximal (spatial) attention. Transformer stacks essentially combine both temporal and spatial attention where the former is implicit in the serial embedding of tokens in language processing and frames in video captioning and the latter in positional coding. As pointed out in the previous entry referencing the work of [14, 125], the particular method of positional coding is critical to performance.
| |
| Figure 11: The above graphic relates to the state vectors in the model shown in Figure 12 and illustrates the spatial hierarchy underlying the organization of working memory in our proposed solution to the SIRtask problem. Each level in the hierarchy provides a different set of objects that participate in relationships pertinent to inferring the computational steps in programs solving SIRtasks. We hypothesize that an attentional stack that models this structure will substantially reduce search in learning such programs. | |

Spatial attention is related convolutional weight sharing. In both language processing and computer vision tasks [2, 20, 114, 47], multi-layer convolutional networks coupled with attentional layers and gating have demonstrated significant performance advantages obviating the need for recurrent processing27
Gehring et al [47] note that "multi-layer convolutional neural networks create hierarchical representations over the input sequence in which nearby input elements interact at lower layers while distant elements interact at higher layers" and thus "hierarchical structure provides a shorter path to capture long-range dependencies compared to the chain structure modeled by recurrent networks28."
Figure 11 illustrates the spatial hierarchy underlying the organization of working memory in our proposed solution to the SIRtask challenge. Each level in the hierarchy provides a different set of objects that participate in relationships relevant to performing computational steps corresponding to register-to-register transfers in a program solving an instance of the SIRtask.
Just knowing that the next step in the program under construction requires comparing the contents of registers in pattern memory with the content of input/output registers significantly constrains the search space for determining the next register transfer. Add to that (temporal) features derived from previous steps and you've narrowed down the search space even more. We hypothesize that an attentional stack modeling this structure will substantially reduce search in learning programs that solve SIRtasks.
%%% Wed Sep 16 05:11:17 PDT 2020
Andrew Nam gave an interesting — if somewhat difficult to fully understand — talk in Jay's lab yesterday. His project involves modeling the ability of humans to follow instructions represented as collections of functions that recurrently call one another. The functions are very abstract and there is no conditional branching or parameter passing; the only thing we know about a given function is the name and order of execution of the functions it calls.
Andrew's task has very little to do with ours except that both are related to neural program interpreters [110]29. I was thinking I might invite him to talk with us about his work at some point, but the one thing I took home was his distinction between temporal weight sharing as facilitated by sequential attention and spatial weight sharing as facilitated by convolutional networks.
While listening to Andrew, I realized a bug in my thinking that would prevent our model from solving two-pattern SIRtasks by searching the two patterns sequentially in cases in which the two patterns share prefix characters. A simple example is the case in which the first pattern is equal to AB, the second pattern is equal to AC and the next two characters of input stream are A and C.
In order to determine that the first pattern does not match, the input has to advance to B thereby making the system miss matching the second pattern. The Scheme program I sent around a month ago carries out the matching in parallel. The program to match patterns in parallel is significantly harder, and the task is already hard. To make the problem more tractable we might modify it in way we discussed earlier.
Specifically, we assume that each register contains what cognitive scientists call a chunk represented in our case as an embedding. This could be a one-hot vector representing a single character or an embedding vector encoding a sequence of characters. The system would have to buffer the last n characters of input or encode the input one character at a time. To simplify we assume all patterns are the same fixed length30.
September 11, 2020
%%% Fri Sep 11 04:30:45 PDT 2020
Each inference cycle in MEMO consists of evaluating extensions to a given sequence of relational reasoning steps where these extensions are represented in a homogeneous format that makes execution a (relatively) simple matter of performing a series of dot products or matrix multiplications. You can think of each extension as a rule and evaluation as applying the rule in an effort to infer a particular relationship. The objective is to find a set rules from which one can derive a target relationship. For example, from the two rules {A,B} and {B,C} one can infer {A,C}.
Each rule and target can be represented as a sequence of tokens interpreted as a sentence in natural language. The ability of Transformers to determine the relevance of other nearby words in the process of selecting the next word in a dialog or translation makes them well suited for applications like MEMO. In comparison, the individual operations required in solving SIRtasks are more varied in the number of preparatory steps they require, e.g., operators have varying number of operands, and the complexity of the networks implementing those operations, e.g., Boolean expressions as branch conditions.
In this entry, we return to the idea of using Transformers to maintain the analogue of an instruction counter and perform the task of moving operands between locations in program memory and registers in the arithmetic logic unit (ALU) of a computer implementing the von Neumann architecture. Translating these references from computer architecture to the terminology of neuroscience, the registers correspond to thalamic nuclei that project onto the striatum in the basal ganglia and, from there, to locations in working memory. These locations are aligned with sensorimotor representations and functions in the frontal cortex that process them.
The basal ganglia and related dopaminergic pathways in the midbrain modulate and control access to or gate the projection of these representations to shape the context for performing both motor and cognitive activities in the frontal cortex. It is this ability to control – or at least influence – activity in the frontal cortex that roughly parallels the role of the instruction counter in controlling the flow of execution in a conventional computer. Completing the analogy, the contents of working memory locations correspond to operands and the alignment and topographic mapping roughly correspond to the data type of the register contents determining what computations can be performed on what content. The operators correspond to neural circuits that perform computations on the type of information stored in their accessible working memory locations.
| |
| Figure 12: The above graphic sketches a general architecture for executive control of cognitive reasoning based on the extended global workspace model [77, 11] and the extensive network of long-distance pathways in the primate brain [90] discussed in the previous entry – see Figure 13. The neural network shown here borrows from the papers on MEMO [14] and End-to_End Memory Networks [125] mentioned earlier. This network uses a modified Transformer architecture [133] to create virtual circuits that perform iterated cognitive reasoning tasks. The pink, green and yellow highlights correspond to annotations used by the controller to maintain the instruction counter (define an unambiguous context for initiating the next step in a computation) and transfer content between registers (route information between functional neural networks thereby establishing virtual circuits capable of performing complex iterated cognitive reasoning tasks). Though not shown in the above graphic, following each pass through the transformer stack, working memory is updated to reflect new input and results from operators and subroutines before being fed back into the transformer stack by recurrent connections. See the main text for a discussion of how the modified Transformer architecture accomplishes this. | |

%%% Sat Sep 12 03:56:00 PDT 2020
In the following, the ALU plays the role of the prefrontal cortex, it is implemented as a modified Transformer stack as shown in Figure 12 and we refer to it in the sequel as the executive controller or, simply, the controller. The executive controller provides two primary services. It alters the contents of working memory to ensure that the vector of working memory contents constitutes an unambiguous representation of the system state serving to keep track of the next instruction in any ongoing computations – this is its role as the instruction counter.
In addition, the controller annotates the vector of working memory contents so as to cause registers in working memory to be loaded with specific content and by doing so initiates specific information processing to occur in circuits separate from those implementing the Transformer stack. It does this by first specifying the source register causing its contents to be copied to a temporary register and then specifying the destination register causing the contents of the temporary register to be transferred to the specified destination. Loading registers and carrying out operations could, in principle, be carried out asynchronously.
The controller may have to perform multiple register transfers in order to initiate processing in the case of operators or subroutines that have multiple arguments or require embedding a sequence of arguments. The Transformer network shown in Figure 12 consists of three multi-head-attention-plus-concatenation units. The first unit determines the operation to be performed and updates the instruction counter accordingly and the second and third perform the source and destination transfers respectively. Multiple arguments and embeddings require multiple passes through the full stack. After each pass through the transformer stack, the working memory is updated to reflect new input and results from operators and subroutines, before being fed back into the transformer stack.
The designated (external) input register contains the most recent input changes at the start of each outer execution cycle. The particular input value will influence the next action taken by the controller, e.g., signaling that the current task has ended and that the following sequence of inputs – set off between and tokens – will specify a new task. In the current model, the context is defined by the current contents of working memory and any flags or other attributions attached to registers to disambiguate or highlight specific content. As an example, the new input at the start of the next outer execution cycle is marked by the controller so that it is either loaded in the working memory registers dedicated to storing data relevant to a new task or it is loaded into a comparator input register that determines the next branch instruction of an ongoing task.
September 9, 2020
%%% Wed Sep 9 06:51:18 PDT 2020
This entry consists of observations and relevant bibliography on global workspace theory and cell assemblies plus a reading list for students taking CS379C next spring interested in current neural network architectures using attentional models for iterated cognitive reasoning tasks. The list of papers in their order of publication are as follows: Weston et al [146] Memory Networks, Graves et al [49] Neural Turing Machines (NTM), Sukhbaatar et al [125] End-To-End Memory Networks (EMN), Graves et al [50] Differentiable Neural Computers (DNC), Vaswani et al [133] plus Rush [111] Transformers, Devlin et al [32] Bidirectional Encoder Representations from Transformers (BERT), and Banino et al [14] MEMO. This footnote provides some context for our interest in the MEMO and EMN models31.
Baars et al [11] and Mashour et al [77] describe global neuronal workspace (GNW) theory and its role in supporting abstract cognitive thought. Their emphasis is on conscious thought, but Dehaene – co-author on the Mashour et al [77] paper – has argued for some time now that GNW is the foundation for both conscious and unconscious thought. GNW builds on Donald Hebb's concept of a cell assembly corresponding to a group of neurons that are repeatedly active at the same time and develop as a single functional unit, which may become active when any of its constituent neurons is stimulated32.
| |
| Figure 13: Panel A shows the macaque brain long-distance network. Each vertex of the network corresponds to a brain region in the hierarchical brain map shown on the right and each edge encodes the presence of a long-distance connection between the corresponding brain regions. Panel B makes the hierarchical structure somewhat clearer by eliminating duplicate connections. From Modha and Singh [90]. | |
|
|

Braitenberg [16] elaborated on Hebb's earlier formulation and provided a more detailed neurophysiological account, and, in a recent paper co-authored by Charles Cadieu, Canolty et al [18] provide a model of how oscillatory phase coupling serves to coordinate anatomically dispersed functional cell assemblies. Modha and Singh [90] summarize what is known about the long distance pathways that serve as the theoretical basis for both cell assemblies and the global workspace. Friedemann Pulvermüller [108, 106, 107] – see class discussion notes here, and Murray Shanahan [115] provide additional insights.
September 5, 2020
%%% Sat Sep 5 04:42:20 PDT 2020
| |
| Figure 14: This is an extended and updated version of Figure 15 showing a trace of the contents of working memory changing over time as the system carries out a sequence of register transfers in the process of solving an instance of the SIRtask. We use four special symbols to mark the beginning and ending of patterns and tasks: | |
|
|

September 3, 2020
%%% Thu Sep 3 09:11:17 PDT 2020
You don't explore, collect, integrate and seek to apply new areas of interest without a purpose in mind, where that purpose could be as simple as the intrinsic rewards of satisfying one's curiosity, or as complex as pursuing the extrinsic rewards of excelling at sports, garnering academic honors or achieving social status or political power. The implication is that new representations don't appear in a vacuum, they are constructed on top of an existing collection of representations with which they inevitably share anatomical structure, cognitive function and motivational drive.
Our bodies and brains are designed in such a way that interaction with our physical environment directed by a prolonged and intricately staged developmental process leads to a set of physical and intellectual skills that prepare us, not only for surviving in the physical world driving the evolutionary forces that shaped those bodies, brains and developmental strategies, but also inventing entirely new models and related skills for both physical and metaphysical purposes well beyond those anticipated by natural selection.
Around the age of six, children are introduced to elementary arithmetic, but they've already been exposed to basic mathematical concepts as early as two or three by developing a primitive sense of number, learning to discriminate among different shapes, making rough measurements to compare the sizes of everyday objects, and playing with blocks and other toys that help to develop an understanding of Newtonian mechanics.
Three questions are driving my current research interests: (a) what parts of the brain contribute to the execution of these early cognitive behaviors, (b) during early development does learning math related skills have any impact – positive or negative – on the neural structures that support their performance, and (c) as mathematical thinking matures what other parts of the brain are enlisted and are these parts of the brain co-opted for other purposes in people who never acquire any sophisticated mathematical reasoning skills.
My interest is not mathematics per se, so much as learning where abstract cognitive skills like mathematics are located in the brain and how we carry out computations on abstract representations of mathematical proofs, computer algorithms, etc. I have a partial answer to (a) from following the research of Jean-Pierre Changeux, Stanislas Dehaene, Nancy Kanwisher, Liz Spelke, Josh Tenenbaum and Barbara Tversky: the neural circuitry supporting mathematical thinking is widely distributed throughout the cortex including motor and sensory areas in the anterior and posterior cortex and the prefrontal cortex in particular [66, 25, 43, 28].
I've also found some relevant models of working memory and its relationship to Changeux and Dehaene's extension of Baars' Global Workspace theory that they call the Global Neuronal Workspace Hypothesis (GNW): they note that "many tasks require the interaction between different cortical processors with distinct functions. The GNW interconnects these processors and enables them to exchange information about the object that lies at the current focus of attention" [11, 77]. The neural circuitry posited as being part of GNW initially appears during early postnatal development and is mostly in place by the age of five.
How and to what degree are these large-scale patterns of connectivity influenced by our bodies and the environment in which we evolved? What if for example we lived in Edwin Abbott's "Flatland" or existed at a spatial and temporal scale such that we could directly interact with and intervene in the quantum world, or were able to move both forward and backward in time enabling us to jump between worlds in the multiverse? How would direct experience of elementary particles acting at the quantum level influence how we learn mathematics? More to the point, what if our prior experience was limited to playing Atari computer games?
The initial impetus for these thought experiments was to get some idea of just how powerful are the inductive biases that influence our understanding of the physical and social world we inhabit, and determine if there are any shortcuts that would serve to restrict search and reduce sample complexity. Apart from the small problem of figuring out what sort of models to build – the basic architecture and wiring diagram, we have the advantage that it should be faster to etch traces in silicon than grow neurons on cellular scaffolding and make connections between them by chemotaxis. That said, it could still take years using current computing technology to acquire anything approaching the ability of an adolescent to generalize well beyond direct experience and adapt quickly to new circumstances.
August 27, 2020
%%% Thu Aug 27 15:08:53 PDT 2020
The following is an exercise that I've been meaning to carry out for some time now. Several entries in this addendum mention that the SIRtask architecture we have been developing bears some resemblance to the low-level controller in the Merel et al paper albeit not having anything to do with motor control. I thought it might be useful to describe a more complete instantiation of the hierarchical motor control architecture in that paper reconceived as a cognitive architecture dealing with variable binding, symbolic manipulation, etc. No attempt was made to describe the design completely; the goal was to have something concrete to talk about and help focus our discussion on the challenges of extending the current model.
The overall system consists of three component subsystems:
There are three architectural subsystems described in Merel et al [83]: (i) a reusable low-level control subsystem that decodes internal abstract representations of actions to generate concrete motor commands, (ii) a predictive observer subsystem that encodes perceptions of relevant external phenomena to produce abstract representations of observable state, and (iii) a high-level executive control system that converts tasks into abstract representations of actions. The following account describes the analagous subsystems of our proposed cognitive archtecture focusing primarily on (ii):
I. The perceptual processing subsystem (PPS) implemented as a transformer stack responsible for some of the functions performed by the thalamus and basal ganglia in the PBWM model as well as attentional functions handled by circuits in the temporal and medial lobes and prefrontal cortex.
II. The register machine subsystem (RMS) implemented as a DNC that serves as the cognitive analog of the primary motor cortex providing a collection of information processing primitives analogous to the motor primitives described in Merel et al. The register machine is responsible for moving information from one register to another in working memory and by so doing initiate information processing computations (operators) performed on the contents (operands) of one or more designated (input) registers and depositing the results in one or more designated (output) registers. The RMS will be the primary focus of this exercise.
III. The executive control subsystem (ECS) also implemented as a transformer stack that invokes and coordinates the execution of procedures consisting of the information processing primitives in the RMS that have been trained to bind information in working memory registers and then perform low-level operations analogous to those handled by the arithmetic logic unit in a conventional computer based on the von Neumann architecture. The ECS would learn to write more complicated programs by manipulating working memory to run program primitives as described below. Rather than run an entire primitive, ECS would run fragments of several, stringing them together to construct new programs. The set of ECS target programs would build on the target training set for the extended SIRtask to include line-oriented stream processing AWK and SED tasks.
Novel characteristics of the proposed cognitive architecture:
It makes sense to think of the RMS as carrying out instructions that correspond to loading content into specified registers serving as the input to primitive operators and then loading the result in specified output registers. Once all of the input registers are loaded, the operator initiates computation automatically, transfers the result to the output register and then (optionally) clears the input registers. Essentially all RMS instructions are register-to-register transfers. RMS DNC keys correspond to register locations and DNC values are employed to store the current contents of registers. The DNC controller is trained to feed the contents of the input registers to the designated operator and subsequently move the result to the corresponding output register.
The RMS is trained by having it learn to compute simple low-level programs referred to as program primitives analogous to the motor primitives described in Merel et al33. The RMS uses the vector of working memory contents as an instruction counter – also referred to as a program counter in computer architecture textbooks. Each learned program has a signature corresponding to a specific vector of working memory contents. You can think of this signature as the first instruction in the compiled code implementing a conventional program stored in RAM.
From a biological perspective, this signature plays much the same purpose here as the basal-ganglia-gated contents of the striatum play in influencing motor behavior by providing a context for shaping motor program selection. Early in training the signature will be specific to a particular input. However as the subsystem is trained it will learn to generalize the contents of locations in working memory that vary with different operands while not altering those locations whose content determines the outcome of a branch instruction. For example, the operands of a Boolean operator will vary but the result of the operator is critical as it determines the flow of execution.
Uninterrupted and starting from the signature of a program primitive, the RMS will step through the primitive program one instruction at time, with each instruction altering the contents of working memory so as to unambiguously represent the context for performing the next instruction taking into account branch conditions. However, the ECS can intervene by altering working memory at any step during the execution of one primitive program so as to represent the signature of another, even starting at an arbitrary instruction in the new program. It is this ability to string together program fragments that we hope to harness in designing the executive control subsystem34.
August 21, 2020
%%% Fri Aug 21 5:07:36 PDT 2020
In addressing concerns raised in last Sunday's discussion, I thought more about specific options for both fully and partially differentiable solutions for the generalized SIRtask register-machine architecture that we've been discussing. My primary concern was with the strategies for reducing search by one of two methods. The first method we talked about last Sunday involved creating a discrete action space to finesse much of the busywork required in memory management and register allocation as well as simple scripts that perform more complicated operations common across a wide variety of programming problems, for example, moving an entire pattern from w0 to w1. Aside: We should stop defining our current effort solely in terms of solving the SIRtask since our goals are both more general and ambitious.
The second method, inspired by Merel, Botvinick and Wayne [83], involves first learning a set of primitives similar to the discrete actions described in the first method above, but done so that the resulting primitives are encoded in a neural network that, as in the Merel et al paper, is fully differentiable and can be used in training higher-level, plug-and-play skill modules. Merel et al use motion capture data to learn motion trajectories that track kinematics of the bodies featured in the MOCAP data. In the case of our problem, we would use a compiler to generate microcode corresponding to the operations performed in the arithmetic and logic unit (ALU) of a traditional von Neumann architecture. Of course, we would have to build a compiler that targets the sort of register machine we are imagining – see below.
Conceptually, learning the higher-level skill modules is relatively simple, but to complete the model in the Merel et al paper we would also need to implement the predictive (observer) and coding space (interpreter) modules. I expect a transformer will work for the former but the latter is tricky in that it plays the dual role of an instruction counter and a policy for selecting the next subroutine to run – see Figure 15. The fundamental difference between the motor primitives in the Merel et al paper and what I will call the low-level program primitives in the approach described here is that, in the former, sequences of motor primitives are linked together through the physics of the body and environment of the agent, whereas program primitives are linked through the flow of information between hidden layers and working memory in particular.
Intuitively, the laws of physics ensure that the execution of sequences of motor primitives obey the equations of mass, motion and gravity, and our perceptual apparatus enables us to observe the consequences of our actions and use the difference between what we observe and what we intended to accomplish as a reliable signal for guiding subsequent action selection. This seems simple and obvious until you start thinking about what goes on in the brain. In selecting sequences of program primitives our ability to directly observe and reliably infer the consequences of our internal actions is extremely limited. For example, we can't directly sense activity or access the content in frontal cortex stripe clusters. And so we must rely upon the indirect observable consequences of our attempts to utilize our memory networks as in the case of witnessing our success or failure in carrying out cognitive tasks such as multiplying two multi-digit numbers together.
We have two advantages in training our artificial neural network register machine compared with the challenges faced by a three-year-old in learning basic math and reading skills. First of all, we actually can observe and even control what's going on in the working memory registers. Second, we can design and run experiments in which we assign register contents at ti and observe the resulting contents at tj for any j > i. This allows us to create training examples by setting the directory contents at an arbitrary ti as the input and then comparing the contents at tj with the results of running the compiler-generated microcode on a register-machine simulator. Moreover, we can use this ability to intervene and observe what register transfers are taking place in order to aid in debugging and guiding curriculum design.
I mentioned earlier that we would have to write a compiler that targets our neural register machine. I don't think this is particularly difficult for our use case. I've written compilers for functional languages, and the language I have in mind is much simpler. I would choose a highly-restricted subset of a functional programming language such as Scheme or Haskell as the source language, e.g., the tokens if, then, else, and, or, equal, list, nth and rest should suffice.
The target language would be even simpler since the register machine works (almost) entirely by transferring the contents one register to another. The operators would consist of the following: [TRANSFER R1 R2] – transfer the contents of register R1 to register R2 overwriting any existing content in R2, [NEXT] – advance to the next time step which would either refresh the input register with the next character in the input stream or clear the input register and update the SIRtask patterns thereby signaling the change to a new SIRtask.
Finally, there is [GATE R] – if R is the input register of a subroutine, then this statement causes the contents of R to propagate through the neural network corresponding to the associated subroutine resulting in the output of the subroutine being written into its associated output register. Note that both the NEXT and GATE operators could be eliminated if we (a) designed the system so that simply writing to the input register of a subroutine initiates propagation through the associated subroutine neural network, and (b) arrange so that simply writing to the output register causes the system to advance to the next state. It seems appropriate that all the register machine has to do in order to execute a program is transfer information between registers.
We still have the choice of whether to make register transfers discrete actions in a partially differentiable reinforcement learning approach or create a fully differentiable model that uses multi-cell LSTM constant-error carousels or a DNC key-value memory plus differentiable read-write controller to implement soft register transfers in which case we can use either reinforcement learning or stochastic gradient descent and a curriculum-learning strategy with unlimited training data produced by a compiler with a register machine target.
In general, the advantage you achieve by exploiting hierarchical abstraction, functional modularity and compositional structure is that you can build from concrete to abstract by absorbing the fixed cost of combinatorial search at each level, hiding the complexity in one level from the next higher level, and encapsulating it in a small collection of reusable functional modules, that we generally refer to as subroutines. If the cost of search at each level in the hierarchy is a constant C and the number of levels in the hierarchy is H then the total cost of building the hierarchy C × H in contrast with a flat / single-level structure whose cost is CH.
Hiding also means that the objects of interest at one level are integrated into the functional modules used at the next higher level, reappearing at that level in the form of aggregates that receive new names befitting their functional use. In mathematics and formal language theory these aggregates constitute an ontological hierarchy. For example, bytes and instructions replace bits and binary gates, variables and pointers replace registers and addresses, objects and methods replace closures, etc.
Hiding complexity is harder than you might imagine. Beginning programmers routinely violate the abstractions inherent in object-oriented programs and – perhaps the most egregious failing of beginning students – employ global variables to enable functions to share state. Computations in the brain are inherently local and often hierarchical. That doesn't preclude duplicating effort but the long period of development in humans may help to create hierarchies that observe hierarchy of function while leaving open the option of refining earlier developed circuits post development – though this is complicated by the fact that the development of skills is often accompanied by the development of the neural circuits required to perform these skills.
August 19, 2020
%%% Wed Aug 19 5:38:37 PDT 2020
After thinking more about Yash's and Gene's comments in our discussion on Sunday, I spent the last couple of days thinking about the prospects for a fully differentiable version of the model we are working on. Specifically, I revisited my reasons for suggesting a combination of reinforcement learning and curriculum learning to address Josh Merel's modularity principal and his approach to learning motor primitives as a means of reducing search. In Josh's approach, motor primitives are learned off-line using motion capture data to learn motion trajectories that the track kinematics of the bodies featured in the MOCAP data.35. I asked my self the following questions and came to the following conclusions:
What would correspond to the motor primitives in the SIRtask problem? – Answer: Basically the sort of operations carried out by the arithmetic and logic unit in a conventional von Neumann architecture, e.g., loading registers, comparing the contents of registers and performing simple branching on the basis of such comparisons.
What would play the role of the motion capture data used to train motor primitives in training these basic computational primitives? – Answer: The ALU-inspired primitives would correspond to the microcode instructions that one would obtain by compiling a computer program written in a conventional programming language.
What would serve for the abstract sensory representations that drive motor action selection? – Answer: Missing from the model as we have described it so far is some analogue of the program counter employed by the ALU in conventional computers to keep track of the next instruction in the process of executing programs36.
In the course notes for this year, we explored at some length the notion of a "context for acting" as it applies in explaining the representations of activity in the parietal and temporal cortex that are employed by the basal ganglia in shaping the context for acting and providing the prefrontal cortex with the information it needs to exert executive control over ongoing and future activities37, as well as the use of the term as it has come to be applied in AI and machine learning.
In some respects, the representations of sensory-motor activity serve as a proxy for the state of the dynamical system in which the agent is embedded. Given that system is partially observable, the agent has to do more work in order to provide a suitable context for acting. This is accomplished by the sort of predictive coding that many circuits in the brain appear to be engaged in. Dispensing with my usual elaboration on this topic, suffice it to say that the same can be said to apply to the use of working memory as the basis for a context that would serve in the role of a program counter.
The basic idea is to treat the underlying system as a k-Markov process for some k large enough to uniquely define a context for carrying out the next instruction in a procedure following a branch or interruption in execution, as in the case of a recursive procedure that returns control to the next instruction in an earlier procedure. However, it is not enough to simply make the information available; rather; as in the case of reading, the system has to draw attention to those bits of information that are likely to be useful in determining what actions to perform / instructions to carry out.
Just as transformers assist in shaping the context for reading or speaking by providing a distribution guiding the interpretation or selection of the next word in a dialogue, the same technology could be used to identify and highlight the information required for the executive controller in the SIRtask architecture shown in Figure 16.A to execute the next instruction in the current thread of control. See Figure 15 below for a rough sketch of how we intend to accomplish this.
| |
| Figure 15: This graphic illustrates the use of a context required in order for the executive control system to keep track of where it is in executing programs analogous to the program counter – also referred to as the instruction counter – in a conventional von Neumann architecture computer. We assume for purpose of this discussion that the underlying dynamical system is a k-Markov process for relatively small k and the state space consists of the set of all alphanumeric vectors of length equal to the number registers in working memory. The neural network implementing the executive controller takes as input a embedding of the most recent k state vectors. We assume that given this input, the executive controller can determine what program it is currently executing and what instruction to execute next, and that, moreover, this capability need not depend on any specific register content but rather on the relationships between registers that contain the same content. Note that the registers in wo and w2 are memory mapped and are therefore essentially typed – this may be true of (or would make sense and could be arranged for) all working memory registers in the SIRtask model architecture discussed in Figure 16.A. Note that the contents of registers are not actually alphanumeric characters but rather their corresponding one-hot vectors. In the graphic shown above, if we assume that the class of all problems consists of SIRtasks with two patterns of the same length, then k = 1 so that, for example, the orange-highlighted registers in t0 and t3 are sufficient to disambiguate programs and instruction counters. This process of inference is aided by a BERT-style transformer embedding stack that highlights the most salient contents and their associated relationships. It may be that a BERT network can be trained to retain whatever prior state information is necessary to disambiguate the current program and its corresponding instruction counter thereby handling the class of variable-order Markov processes38. Note: See Figure 14 for an extended and updated version of this slide. | |
|
|

The changes in the model suggested in this entry are significant insofar as how the proposed model differs from earlier models, both algorithmically and in terms of its biological analogue such as it is. In earlier versions, we took much of our inspiration from what we know about executive function in prefrontal cortex. In the model explored here, we have essentially re-introduced the role of basal ganglia to guide the selection and execution of abstract motor primitives.
In the physical world, we perform actions, those actions alter the state of world, we perceive the consequences of our actions and neural circuits in the posterior cortex convert those sensory impressions into representations that serve as the context for determining what actions to take next. All motile organisms – and some sessile – engage in some variant of this cycle. Mammalian brains evolved to optimize such recurrent processing on multiple levels and we humans are particularly adept – comparatively speaking – at using the same machinery for more abstract thinking.
In performing abstract cognitive actions, the consequences of cognitive actions produce changes in the neural substrate that we feed back into the same or other circuits to create the context for planning subsequent actions. For skills like performing complex arithmetic, algebraic and spatial reasoning, we have to use the same circuits we use for carrying out more mundane tasks and as a consequence if often takes years of practice to excel at these skills.
%%% Thu Aug 20 7:28:18 PDT 2020
The model proposed here breaks down along more or less conventional lines with the separation of responsibility between the motor cortex as the basis for planning and executing all motor tasks and the prefrontal cortex in its conventional role as the executive controller in charge of overseeing the execution of motor tasks as well as dealing with more abstract cognitive tasks. Indeed, here we have adopted the framework described by Merel et al [83] in which motor primitives are learned separately to provide a foundation for performing a wide range of other tasks that can be learned more easily by virtue of how the general-purpose motor primitives considerably reduce the amount of search that would be required were we to attempt to learn without that foundation. The primary difference between the model described in Merel et al and the one described here is that our model deals with primitive and complex tasks that require coordination by way of abstract information sharing rather than through the kinematic and dynamic constraints of the physical world.
August 11, 2020
%%% Tue Aug 11 4:15:23 PDT 2020
Panel A in Figure 16 represents a model of executive control in the prefrontal cortex modeled loosely after the work of Koechlin et al [70]. The three green trapezoids correspond to neural circuits responsible for the abstract-to-concrete stages of planning and task management postulated to explain functional / anatomical divisions in the anterior prefrontal cortex [71]39.
Here we characterize planning as selecting a program and controlling its execution. At each of the three stages in this process, the computations performed at one stage communicate with those at the next using working memory to constrain and shape the activity in subsequent stages.
Each trapezoid represents a neural circuit implemented as multilayer network. In practice they are combined to form a single stack, but are shown here interleaved with rows of blue and orange boxes to highlight the role of working memory as it evolves during the process of selecting a program to run.
The model is relatively straightforward to design and build and the neural network is fully differentiable and could be trained end-to-end. Practically speaking however it would take an enormous amount of training data to do so. However, there are steps we could take to reduce the amount of data required.
| |
| Figure 16: The three panels shown above illustrate three neural network architectures for modeling executive control in the prefrontal cortex. Panel A represents a traditional fully-differentiable neural-network architecture that, at least in principle, can be trained end-to-end with stochastic gradient descent or related technologies. Panel B is our current architecture targeted at solving a class of neural programming problems including the SIRtask and its variants. Panel C is an earlier architecture used as a thought experiment in exploring tractable training methods and that lead to the architecture in Panel B. | |
|
|

For example, we could design a curriculum-based learning protocol to generate synthetic data in the form of a series of increasingly difficulty in an attempt to recapitulate early child development. We might introduce an inductive bias to constrain the function of different areas if only we knew what those functions were and how to construct such a bias.
Panel C illustrates one of several designs we have developed in a series of thought experiments intended to think through the consequences of different training strategies. These strategies incorporate reinforcement learning, offline training and specialized differentiable memory models in keeping with complementary learning systems theory [80, 97, 96].
Panel B depicts the SIRmodel described in this appendix and represents our attempt to implement a working model that solves SIRtask [52] and related automated programming problems. The proposed solution incorporates several strategies for dealing with the sample complexity problem mentioned above:
initial offline training primitive relational operators – a collection of logical and relational operators that support conditional branching using embedding-space vector input / output;
transparent architecture that allows selective training – training protocols can manipulate internal state assigning one-hot vectors to alter the contents of registers in working memory;
staged graded-difficulty curriculum learning protocol – list and sequence processing problems including classification, substitution, filtering, and executing simple regular expressions;
reinforcement learning with finite discrete action spaces – the controller performs sequences of discrete actions to construct and carry out the steps in differentiable virtual programs;
action space enables fine-grained architectural control – actions enable the controller to read from, write and control access to, and transfer content between registers in working memory;
Each action alters the content of working memory and the sequence of all such changes constitutes an execution trace of the running program. Some working-memory registers, referred to in the following as volatile memory, are periodically refreshed under the control of subcortical systems such as the basal ganglia.
We don't require a network reprising the role of the basal ganglia for the model described here, but we are planning for an attentional and sensory processing hierarchy implemented as a transformer network [133] that refreshes a designated subset of working memory registers on each execution cycle.
Information temporarily stored in volatile memory will be lost if not transferred to registers under executive control. Rather than the controller having to search for non-volatile storage, it will be more efficient to allow the controller to invoke content-addressable variable names and rely on the underlying memory management system to assign registers.
These names can then be associated with individual programs thereby relieving the controller of having to search for an empty register every time a program is run and then remember the location of that register for the duration of program execution. Once execution is complete, the memory manager would automatically free the storage for reuse40.
The method for reducing sample complexity and focusing search outlined in this proposal is similar in its motivation – though not the particular training strategies or architectural plans – to that articulated in Merel et al [83] for performing hierarchical motor control using probabilistic motor primitives41. Their description of the principle of modular objectives is particularly relevant to our problem42.
August 8, 2020
%%% Sat Aug 8 07:30:47 PDT 2020
The following comments concern the problem of training the SIRmodel architecture. In addition to a proposal for a graded set of problems for training via reinforcement learning, we suggest possible extensions to the model action space to facilitate training. It is also worth pointing out that the suggested extensions could be used to train the model in a self-supervised fashion where "self-supervision" seems to me more apt than "un-supervised".
Proposed Changes to the Basic Model:
Add new actions enabling the PFC to lock/unlock (gate) each register.
Add register status flags visible as part of the system state vector.
Consider replacing each read / write pair with a single register transfer.
Add a program counter that automatically advances and a reset action.
As currently conceived, the state vector does not uniquely define the program state.
Observations on the Register Layout:
It may simplify training somewhat if the system could count on a contiguous set of registers in w1 – call it w1s – that mirrors the memory mapped registers in w0. Then we could have a blanket w0 to w1s bulk transfer action that copies the BG registers to their mirrored registers in w1 respecting register locks. However, this may be short sighted on my part.
As a consistent protocol for training that works throughout all developmental stages of curriculum training and also applies during subsequent testing, we have to be consistent so that the contents of the w0 registers at the start of an outer execution cycle always uniquely identify a specific task.
Then, if the w0 input register is set to the null character, e.g., denoted by ? or any other non-alphanumeric character, and there is exactly one w0 pattern register containing an alphanumeric character, then the system can rely on this as a signal indicating a training exercise that requires the system to move the contents of the non-empty w0 pattern register to the w1 register with the same offset.
Graded Exercises in Curriculum Protocol:
Level 0 (basic register and counter exercises):
transfer contents of one register to another
lock and unlock the contents of each register
start the program counter and reset it at a specified time
Level 1 (basic register transfer exercises)
for all combinations of registers: wi to wj transfers43
consecutive transfers to curried operators that take multiple inputs
Level 2 (advanced register transfer exercises)
transfer contents of all w0 to w1 registers44
transfer all registers but with some w1 registers locked
transfer an entire pattern from w0 to w1
Level 3 (basic primitive operation exercises)
for all combinations of registers: load input register, gate input register, read output register sequences45
Level 4 (graded store, ignore, recall tasks)
one single-character pattern – find all occurrences; remove all occurrences;
two single-character patterns – remove duplicates; substitute first for second;
one double-character pattern – same difficulty as the previous sans chunking;
two double-character patterns – this is as difficult as the original 1AB 2XY;
August 7, 2020
%%% Fri Aug 7 05:39:10 PDT 2020
Thanks to Rafael for pointing out the Andreas et al [8] paper. I missed seeing it when it came out. I particularly appreciated the specific examples of modules – ATTEND, CLASSIFY, MEASURE, though I am somewhat skeptical of the generality that their names suggest. A later [59] paper by some of the same co-authors that I did happen to read at the time of its publication went further by cleaning up some of the hacks in the earlier paper and demonstrating an end-to-end training pipeline. The interesting part for me was the way in which they were able to leverage natural language, but I should point out that this observation is not particularly surprising, there have been quite a few papers that take advantage of the rich structure of natural language in order to exploit that structure in another domain, e.g., training robots or writing code.
Hierarchy, modularity and compositionality go together and are fundamental characteristics of human thought and very likely animal cognition as well. In pursuing the SIRtask, one of my main goals is to directly address the problem of compositionality, finesse the problem of modularity and naïvely claim that recursion provides a credible partial solution to the problem of hierarchy. The SIRtask forces us to address the problem of combining primitive operations to construct programs that solve challenging problems. The SIRtask is challenging for neural network models for exactly the same reasons that three and four-year-olds fail to solve it and older children who don't acquire early enough are disadvantaged in school if they haven't mastered the basic cognitive skills that are essential for solving it.
I want to understand the cognitive foundation that has to be in place for a five-year-old to master the SIRtask. I believe that if we can provide such a foundation, then we'll be able to solve the SIRtask with a reasonable amount of search, and that without it, the necessary search will be combinatorially exhaustive and therefore prohibitive. There is evidence to suggest that the difference between a three-year-old's performance in solving problems like the SIRtask and that of a five-year-old's may have something to do with a five-year-old being able use referents such as nouns and pronouns to refer to abstract concepts that have no direct physical grounding and by so doing can make qualitatively more effective use of short-term memory [38, 10, 19].
In principle, the original SIRtask can be solved using the current version of the architecture described in the addendum but it involves mental gymnastics at a level well beyond the ability of nonhuman primates and young children. Animals employ affordances available in their environment to serve as an extension of their memory essentially leveraging an analogue of the method of loci to store information in locations in physical space so that useful / relevant information will be conveniently available and easily recovered when those locations are recalled from episodic memory or visited in physical space.
In the current version of the architecture, the system has to search for a register in which to store information. The system might end up randomly choosing register #4 on one trial and # on the next. However, having stored the information in a register it now has to remember what register it used in the current trial, but where does it store this information!
For that matter, how does the system "know" that the registers in short-term memory w1 are interchangeable. If the system was presented the problem in natural language, it might be able to conveniently use the supplied referents, e.g., "pattern one" and "pattern two", as a key to store and subsequently retrieve the information from a key-value, content-addressable memory. Automating this capability and integrating it into the PFC's repertoire of actions seems quite reasonable.
A complementary enhancement that would enormously simplify generating solutions to problems like the SIRtask would be to enable the PFC to perform chunking and unchunking and train the primitive operators to handle chunks as well as no-chunked data [63]. Simple chunking and unchunking of objects of the same data type, e.g., alphanumeric characters, could easily be implemented using standard embedding techniques and a LSTM/GRU encoder-decoder pair for chunking and unchunking.
Relevant to creating a curriculum-learning strategy for mastering the SIRtask, here is a set of graded problem classes characterizing the difficulty of tasks related to the original SIRtask as described in [52]:
One single-character pattern – find all occurrences ; remove all occurrences ;
Two single-character patterns – remove duplicates ; substitute first for second ;
One double-character pattern – same difficulty as the previous sans chunking ;
Two double-character patterns – this is as difficult as the original 1AB 2XY ;
Moving beyond two patterns would seem to require a different strategy to avoid the combinatorics and a recurrent approach is the most obvious strategy to use for a suitable algorithmic bias.
%%% Wed Aug 5 4:24:44 PDT 2020
Preview: The important features of the architecture described in this addendum include the transparency and access to the internal behaviors carried out by the PFC in loading registers, moving information from one location to another and invoking computational primitives. Executing a primitive requires the following steps: (a) load the primitive's input register, (b) gate its release allowing the information stored in the input register to propagate through the neural circuitry that defines the behavior of the primitive, and (c) obtain the results by reading from its corresponding output register.
Serving in the role of the arithmetic logic unit in a von Neumann architecture, the PFC manages the flow of control in executing a program by performing the logical operations required to determine branching and initiating the sequence of operations carried out by procedures including all of the I/O required to access and route data to locations in working memory, and maintain that information for subsequent use.
Sequences of select, load, gate and store instructions constitute the assembly language for the model architecture. Such sequences are essentially subroutines that can be compiled and stored in a key-value memory using keys corresponding to the same augmented state vectors that the PFC uses to determine what primitive to perform next. The remainder of this addendum is to intended to supply you with what you need to know in order to evaluate this proposal. Your suggestions for improving it in fulfilling that promise are most welcome.
This version of SIRmodel architecture was initially inspired by ideas from borrowed from systems neuroscience, but the latest revision provided here also draws upon ideas from computer architecture and programming language theory. It would be surprising if the principles of these two areas of computer science apply to our understanding of the structure and function of the human brain, but keep in mind that John von Neumann borrowed a good deal from mid-twentieth century neuroscience in designing the computer architecture that bears his name [138, 137, 136, 94].
Introduction: The following describes an approach to learning a fully differentiable model of procedural abstraction. The approach is similar in spirit to the architecture described by Merel et al [83] in so far as it assumes a set of independently trained primitives that support a variety of computational tasks. See here for an overview of the system architecture.
In the simplest version of this model, the primitives correspond to operators of the sort that we find in conventional programming languages, e.g., AND, OR, EQUAL46, are implemented as MLPs and are trained offline as in the Merel et al model.
For example, we could train an MLP that given an embedding of two items would determine whether the two items are equal. This differentiable comparator could be overloaded so it operates reliably on multiple data types by identifying and applying the appropriate similarity metric as required. Similarly we could train disjunctive and conjunctive operators.
The weights of these primitive would be frozen post training, but it is still possible to propagate error signals backwards through those weights in order to train downstream components. In order solve the SIRtask, the system has to learn how to temporarily store partial results and perform conditional branching using these off-line trained operators.
| |
| Figure 17: The recurrent input to the PFC is essentially the entire working memory which includes the most recent information from the sensory and motor cortex that in a biologically more plausible architecture would constitute the input from the basal ganglia. Importantly, it also includes all of the information in registers involved in performing computations, and as such it serves as the state vector for ongoing computations and in particular provides the context for the PFC make modifications to the contents of registers and choose the next step in the ongoing computation. | |
|
|

Working Memory: We divide working memory (WM) into functionally distinct sections. Let w0 correspond to set of the registers updated by the basal ganglia (BG); w1 is the set of temporary registers used by the PFC to store intermediate results for subsequent use, w2 is the set of registers corresponding to the inputs and outputs of subroutines and w3 corresponds to all of the WM registers minus w0 – see Figure 17.
The approach described here relies on using the entire working memory as the recurrent input to the PFC network, serving a role similar to that of the basal ganglia in shaping the context for action selection in the motor cortex. The PFC constructs and runs algorithms entirely by stringing together computational primitives; it does so by reading data from one register in working memory and writing it to the input register of a specific computational primitive.
To execute a primitive the PFC loads and then gates its input register thereby running and the result is transferred from the output register back working memory. This process of running primitives relies on working memory being mapped and the PFC able to control transfers between registers by performing discrete actions analogous to motor primitives. All primitives are allocated one input registers. Primitives requiring multiple arguments are handled as curried functions.
In following, we refer to the inputs and outputs of subroutines as variables to emphasize their computational role in the model described below. All variables corresponding to the inputs and outputs of subroutines are global. This restriction precludes the ability to store local state on the procedure call stack. This shortcoming, such as it is, can be overcome by simulating the call stack using short-term memory in the form of a DNC serving as a LIFO queue.
Execution Cycle: We assume that different parts of the overall system will cycle at different rates. In the remainder of this discussion, the term execution cycle refers to the slowest or outermost execution cycle. The w0 contents are ephemeral in the sense that every execution cycle each register in w0 is either reset to some default value or updated with information supplied by the basal ganglia.
The set of w1 minus w0 registers corresponds to the PFC-augmented state vector is concatenated with the BG-refreshed w0 registers and serves as the recurrent input to the PFC in the next execution cycle. All PFC actions correspond to either reading from or writing to WM registers, or both as in the case of moving information from one register to another. The sequence of changes – think of them as bindings – to the WM registers that the PFC has control over, i.e., w2, correspond to a trace of the programs being executed by the PFC.
Ignoring possible distractions instituted by the latest BG w0 updates, the current contents of the PFC temporary registers provides all the information that the PFC requires in the next (outer) execution cycle. The sequence of primitives performed in running a program can be recovered from the sequence of PFC reads and writes.
| |
| Figure 18: The primary role of the PFC is to facilitate and coordinate the running of programs by moving information between registers and gating their contents to initiate the execution of specific subroutines that, in the case of the SIRtask, correspond to what are normally referred to as operators when speaking about conventional computer programs. In the SIRtask, the primary operators involve comparing the contents of two registers to determine if they are equivalent and conditioning the choice of subsequent steps based on the results of one or more comparisons. | |
|
|

Discrete Action Space: In each execution cycle, the PFC can perform one or more actions corresponding to register transfers, i.e., a read followed by a write. There are N = |w0| × |w1| possible transfers from w0 to w1 temporary-storage registers, M = |w1| × |w2| × 1/2 possible transfers from w1 temporary-storage registers to w2 input registers, and the same number of transfers from w2 output registers to w1 registers for a total of N + M PFC actions – see Figure 18.
This number could be significantly reduced by partitioning the w1 temporary-storage registers into blocks and assigning each w2 register a w1 block to serve as a shared pool for register-to-register transfers. However, keeping track of register bookkeeping will be a headache for the PFC and an unnecessary one at that. A better approach is to avoid fiddling with registers altogether and instead design the PFC to work with variables and their bindings using fixed-size context-addressable memory and FIFO queue. Chunking based on encoder-decoder embedding networks would be a powerful extension of the PFC memory-management capabilities described here47.
Reinforcement Learning: We train the PFC by simulating the sequence of w1 updates that would occur as a consequence of a correctly running program. The accessibility of the underlying PFC operations facilitate the staged generation of curricular activities starting out with simple programs such as comparing two items in memory or producing an output whose value depends on the conjunction of two predicates, and graduating to simple and the more challenging versions of the SIRtask. My first inclination would be to use reinforcement learning.
The action space for the model discussed here is finite and relatively compact suggesting that some variant of DQN [87, 88, 89] might be a reasonable choice for implementing the model. Rafael and Yash made some suggestions during last Sunday's meeting, but I don't think the model was fleshed out enough at the time to evaluate different learning technologies. Hopefully, the additional detail available in this document will make for a more focused discussion next Sunday.
July 31, 2020
%%% Sat Jan 1 04:11:19 PST 2021
This is the first entry in an appendix to the class discussion list from CS379C taught in the Spring of 2020. Due to the disruption caused by the SARS-CoV-2 outbreak and ensuing pandemic, it was decided that students would not be required to produce a final project including working code. In the last few classes, we discussed possible coding projects that would demonstrate some of the more ambitious ideas we explored during the quarter, and, as an exercise, fleshed out a project related to what we had been calling the SIR task borrowing from O'Reilly and Frank [98] described in this appendix.
The entries in the appendix are listed in reverse chronological order, in keeping with the format of the class discussion lists. If you arrived at this page by clicking on a link in some other document, you might want to refer to the last status update on the project recorded in this document which is available here. Obviously from the timestamp above these three introductory paragraphs were added later. There is no definitive preprint or conference paper for this model as yet. Several of the students who participated in a series of Sunday meetings to discuss the project are interested in working on such a model.
Chaofei Fan, Gene Lewis, Rafael Mitkov Rafailov, Meg Sano, Yash Savani, Rishabh Singh, Veena Ummadisetty and Nikhil Bhattasali were among those who contributed to the ideas chronicled in this document and participated in our Sunday discussions. Starting in late summer, a subset of them started working on an implementation of what we started calling a Differentiable Register Machine patterned after the model we had started out talking about in July. What we started talking about in July has expanded into several new threads that are under discussion as possible topics for CS379C in the Spring of 2021. Join us on the 2021 class discussion list if you are interested in following along.
%%% Fri Jul 31 3:12:36 PDT 2020
| |
| Figure 19: This is a revised version of the store-ignore-recall-task architecture from the 2020 class discussion notes. The description that accompanied the earlier figure also needs to be revised somewhat, but it will have to do for the time being as I haven't the time to pursue now. The important additions to the earlier model are spelled out in the remainder of this entry and revolve around the explanation of Figure 20. | |
|
|

The three panels shown in Figure 20 describe the basic functions whereby executive control networks in the model of frontal cortex discussed here can manage the information flow between locations in working memory that we refer to as registers consistent with terminology used in earlier models. The graphic shown in panel A depicts the frontal cortex as a collection of circuits (orange rectangles) with their inputs and outputs (light blue rectangles with rounded corners) in working memory. These specialized circuits, referred to as subroutines in the following, encode computational components that can be used to construct more complicated programs.
Panel B illustrates how working memory, representing the inputs and outputs of the circuits shown in A, is implemented as a fixed-size differentiable neural computer (DNC) managed by executive control circuits in prefrontal cortex (light green rectangles). To emphasize that the DNC controls all working memory input and output, the curved green lines in B signify identity, meaning that the inputs and outputs of the circuits in A and their corresponding entries in the DNC – the value parts of the key-value entries stored in the DNC – are identical and separated in the figure only for the purpose of clarifying their function.
| |
| Figure 20: The three panels shown in this figure describe the mechanism whereby executive control networks in the prefrontal cortex manage the information flow in working memory to construct and run differentiable programs composed of simpler computational components referred to as subroutines. The graphic in panel A depicts the frontal cortex as a collection of circuits (orange rectangles) along with their inputs and outputs (light blue rectangles with rounded corners) in working memory. Panel B illustrates how the working memory representing the inputs and outputs of circuits shown in A is implemented as a fixed-size differentiable neural computer (DNC) managed by executive control circuits in prefrontal cortex (light green rectangles) to create virtual networks of subroutines that implement differentiable programs capable of parameter passing, conditional branching and other characteristics found in conventional computer programs. Panel C illustrates such a program with dashed red lines that are virtual in the sense that they are not permanently fixed in the model architecture but rather they are created temporarily – as required during program execution – to facilitate the flow of information between program components using the DNC to transfer information from the output register of one component to the input register of another. See the main text for a more detailed account. | |
|
|

The directed red and green lines from the DNC memory storage to the DNC controller (blue quadrilateral) are used by the executive control circuits (light green rectangles) to gate information originating in the basal ganglia and posterior cortex, route this information to the input of specific subroutines and map the resulting output to either the inputs of other subroutines, or to extra-cortical systems – analogues of motor controllers or other peripheral subsystems – responsible for making changes in the external environment.
The executive control circuits are able to use the DNC as a switchboard to create virtual networks of subroutines that implement differentiable programs complete with parameter passing, conditional branching, parallel processing and iteration in the form of tail recursion. Panel C illustrates such a program with dashed red lines that are virtual in the sense that they facilitate the flow of information between program components using the DNC to transfer information from one component to another. Some of the individual components provide differentiable analogues of operators in conventional programming languages such as comparators that determine if two inputs are equal and conditionals that govern the flow of control.
Ideally these basic types of processes and operators would be overloaded in the sense that they perform the appropriate sort of computation depending upon the type of their inputs, e.g., an equality operator that when fed numbers employs numerical equality and when fed images uses some sort of image processing similarity or content classification as a metric. Back propagation and experience replay should be easy to support using the switchboard to recreate the virtual networks and reverse the forward flow of normal program execution to backpropagate errors. By establishing only those connections required for the circuit being trained, the switchboard should mitigate some of the problems relating to catastrophic interference.
While the model described in Figures 19 and 20 was inspired by current models of basal ganglia and prefrontal cortex function [101], we have deviated significantly from these models in the current design. However, the STRUCTURED WORKING MEMORY and PERCEPTION & ATTENTION LAYERS components shown in Figure 19 perform much the same context-shaping and gating functions described in the PBWM model [98], the prefrontal-cortex proxy in Figure 20 (B) has access to the entire highly-structured and gated output of the basal ganglia, and the circuits in the subroutine library operate on content-specific subregions of the basal ganglia output.
Not shown are the connections to additional DNC components that serve as a call stack and repository of program traces, the latter used in learning and debugging subroutines and serving as a proxy for more a more conventional analogue of the hippocampus. The use of an explicit call stack was introduced in another project relating to the programmer's apprentice48 and is not necessary to support the functionality described here, however maintaining a repository of program traces is likely to appear in future instantiations of the model presented here.
The model presented here is not intended to emulate a conventional computer despite our convenient use of terminology drawn from computer science. Nor is it a complete solution to the problem of building useful agents like the programmer’s apprentice. In particular, it does not support switching contexts or dealing with interruptions – problems that inevitably arise when working on complex software engineering projects and collaborating with other programmers. A short- to medium-term memory patterned after the hippocampus and searchable by executive control circuits in the prefrontal cortex will be an essential complement to the the sort of relatively volatile working memory discussed here.
| |
| Figure 21: The above listing includes a Scheme implementation of a solution to the SIR problem that illustrates several aspects of the model discussed here. These include features of the programming language that reflect aspects of the model described here – see the main text for details. The implementation can also be adapted to generate training data for a developmental curriculum learning approach. | |
|
|

Figure 21 is the code listing for a Scheme implementation of a solution to the SIR problem that illustrates several aspects of the model discussed here. In particular, it relies on simple operators, data structures and control structures that have natural connectionist instantiations, e.g., COND, AND, EQUAL? and LIST, and it makes use of a powerful iteration method borrowed from functional programming called tail recursion that is efficient and easily modeled using recurrent neural networks.
The preferred method for handling variable binding and program state in Scheme involves the use of closures that encapsulate functions and local state in a manner analogous to how data and computation are commingled in connectionist models. Interpreting and debugging what's going on in a model such as the one shown in Figure 19 would be made easier by having all outputs made human readable, e.g., alphanumeric characters, and instrumenting the DNC so as to be able to trace which circuits and registers are being used at each timestep – a task made easier using the tools available in most integrated development environments.
The Scheme code could also be used as the basis for a curriculum learning approach that builds from simple components, e.g., (lambda (a b) (if (equal? a b) (output 1))), to more complicated expressions (lambda (a b c) (cond [(and (equal? a b) (equal? (b c)) (output 1)] [else (output 0)]))), where a, b and c are registers in working memory and output writes to the only (motor) output register indicated in the model shown in Figure 19. Of course there is nothing special about Scheme for this application, except for its ease of use as a rapid prototyping language and, conceptually, as a rough approximation for the sort of programming model we have in mind for system proposed here. Along similar lines here are some excerpts from recent correspondence:
%%% Thu Jul 23 17:12:32 PDT 2020
MJF: One thing I think is important from the PBWM standpoint is the content-addressable memory part of it, i.e., that it can learn to use each 'stripe' or buffer as an address and then learn when to read out of that address in a way that can be transferred out of distribution. The SIR2 task is an example of this where the model has to learn to store some info in one buffer for STORE1 and recall from that buffer for RECALL1, but independently and unpredictably in time, store other information and recall it when probed with S2 and R2. Same as the phonological loop task – the model has to learn to structure the inputs in a sequential way so that it can read out from the relevant buffer given a probe at some point later in time, and can do so even if it never saw that particular sequence or order before. The interaction of input and output gating is important here. So my question is whether your version of the model retains this feature?TLD: We've been looking at various content-, temporal- and context-addressable neural-network memory models like NTM and DNC memory systems that are often touted as neural-network proxies for the hippocampal complex but seem even more relevant to managing working memory. Regarding your question, the chapter draft that you co-authored with Randy prompted several of us to review the original NTM and DNC papers to better understand their respective strengths and weaknesses. The model I pointed you to is informed but not restricted to PBWM or any other theory of working memory, and we are currently looking at hybrids that incorporate lessons learned from computer science. An important related issue concerns the downside of content-specificity in subroutines and the danger of duplicating effort by training multiple networks to do highly-related conceptually, e.g., two measures of equivalence, but subtly-different, e.g., images of dogs versus images or images of cats.
In particular, I find it useful to think about the difference between local and global variables in writing programs and the usefulness of nested environments, i.e., symbol tables, as a means of controlling the context for computations, and closures as an effective method for encapsulating state. Environments control what variables the computations performed within the scope of a procedure are allowed to access or alter and they are managed by the LIFO call stack – looking backward in time as it were, whereas closures allow programs to encapsulate state and pass it forward in time.
The way in which neural circuits collocate memory and processing complicates matters somewhat. Essentially all neural computations are performed in place thereby discouraging reentrancy – not to be confused with the use of this term by Gerald Edelman and Giulio Tononi [36]. However, the job of the PFC is to compensate for this shortcoming by storing, protecting and then recovering such context as required and subsequently freeing up the relevant working memory. It's interesting to think about how Wayne et al [145] handle the SIR2 challenge that you mention — the title of the paper "Unsupervised Predictive Memory in a Goal-Directed Agent" and its focus on partially observable Markov decision processes provides yet another perspective. As an exercise, we are currently just trying to channel all these disparate ideas to come with an effective design.
RIS: Thanks for sharing the project draft. The proposed architecture looks very exciting and also closer to how humans perform algorithmic tasks by first decomposing the inputs into corresponding sub-inputs and then learning to compose desired sub-routines to accomplish the final goal. The decomposition of computation from learnt appropriate abstract representations of input patterns is very nice. The explicit controller choice also seems to be quite powerful as it can learn to call sub-routines using various control-flows (iterations, conditional, parallel processing etc.). I also quite liked the idea of generating human readable outputs and instrumenting the controller to find which sub-routines and memory are being used at different timestamps.
In terms of curriculum learning, there was a recent followup work from Josh Tenenbaum's group on growing a library of sub-routines in a way that the learner learns to solve problems of growing complexity [37]. Maybe some similar idea could be useful in this setting as well where the library of sub-routines is grown incrementally as the agent learns more problems of increasing complexity. There are also a couple of nice demos people have built recently using GPT-3 for generating code from natural language. I was planning to spend some time looking at what forms of abstraction these models are learning from inputs, and that could also be interesting to see if they might be useful for the perception and attention layers component.
TLD: Thanks for the feedback. The paper from Tenenbaum's lab is particularly relevant. My original focus was on building a "cognitive" version of Merel et al's hierarchical motor control architecture, but it soon became apparent that the problem of motor control is very different from that of cognitive control in that the interactions between motor control primitives are mediated through the environment and accounting for these interactions is facilitated through perceptual, attentional and (intrinsic) motivational pathways.
In some cases, cognitive control systems can – or plausible could – exploit these same pathways, but, generally speaking, the match between motor control and environmental feedback is more direct and relevant given their evolutionary pairing. The proposed architecture that I sent you provides the necessary pathways for connecting cognitive primitives in the form of subroutines passing arguments, but lacks the more direct and relevant feedback afforded by physical interactions – at least for the relatively simple robotic tasks of the sort most common in the literature. I'd love to hear what you find out about the abstractions derived from the GPT-3 NLP-guided code-generation demos.
RAS: What did you have in mind for the perception & attention layers?
TLD: Probably some sort of BERT-like stack and treating extrinsic rewards as just another perceived feature of the external environment. In such a model, representing the context at multiple levels of abstraction becomes paramount and inferring the probabilities of new information and their derived abstractions conditioned on that context is key. It's also becoming much more common to think about implementing those distributions using nonparametric, kernel-based models like VAE which makes sense in dealing with the sort of sparse, arbitrarily structured data that we expect. For the SIR problem addressed in the model description I sent you, we can finesse most of that complexity so as to focus on the problem of learning both the core primitive subroutines and the task of combining those primitives to construct more complicated programs.
At some level, the critical challenge becomes one of solving a search problem in a combinatorial space of possible programs. There are two factors that I believe will determine success, both of which depend on reducing the search. The first involves a curriculum learning strategy that focuses on learning a collection of useful primitives coupled with an exploratory behavioral bias to experiment with – induce constructive "child's play" – implementing simple programs consisting of short strings of primitives analogous to "motor babbling" in robotics. The second involves learning to observe bespoke "execution traces" and generalizing them to solve a wider range of problems. That may seem like cheating, but I believe that most of what we humans "invent" depends heavily on our observation of other people solving problems combined with our analogical skills and facility with language.
%%% Sun Jul 26 05:14:06 PDT 2020
As I mentioned in our discussion this morning, the perception-attention stack is not necessary in order to demonstrate the core capability of the SIR model. Initially, we can simply use one-hot vectors to represent alphanumeric characters, and one of the first steps in curriculum learning will be to learn a simple comparator to determine when the contents of two working memory registers are the same. To illustrate the role of perception we could train a classifier for MNIST digits and use only digits for the input sequence and the two three-character patterns.
The next level of complexity might employ digits again, but at this level the digits would appear against a white background at random locations in the image having undergone a linear combination of affine transformations. In this case, the attention layer would identify the area containing the target and the perceptual layer would produce representations analogous to those generated by the dorsal and ventral visual streams. These would then be mapped to different thalamic nuclei, gated by the basal ganglia and projected to predetermined registers in working memory.
Alternatively, we could employ a MERLIN style VAE to both focus attention and judge whether two images represent the same digit. Note that you don't necessarily need to classify two patches in order to make a good guess as to whether they are similar enough to warrant identifying them as representing the same character. It would be interesting if we could demonstrate learning and deploying a more general-purpose comparator useful in a wider range of tasks – of course we'd also have to explain how to avoid catastrophic interference in this setting.
It's worth pointing out that the content-structured summary of active circuits in the sensory cortex gated by the BG explains how we are able to line up sensory motor features with appropriate control circuits in the frontal cortex to enable a special case of variable binding. The prefrontal cortex is able to perform a more general version of variable binding allowing humans to carry out planning and abstract cognitive information processing – however, while they have the capacity, it requires skill to become proficient exercising this capability. Ericsson and Kintsch [39] offer an alternative called long-term working memory by combining episodic and working memory to address this capability49.
%%% Tue Jul 28 05:14:41 PDT 2020
In an earlier exchange, Michael Frank commented on the utility of content-addressable buffers / 'stripes' and I raised a related issue – also mentioned above – concerning the specificity of subroutines and the possibility of duplicating effort or falling prey to catastrophic forgetting. In Michael's papers he often makes reference to the phonological loop in Baddeley and Hitch's theory of working memory [13]. The Baddeley and Hitch model is related to the DNC controlled switchboard model proposed for the SIR model discussed in this appendix. If you haven't already, it might be worth your time to at least read the Wikipedia page or a recent review paper50.
The key issue is that the probes used to access the content-addressable buffers corresponding to the inputs and outputs of subroutines should account for both the function of the subroutines and their type specificity. For example you might want to train a comparator for determining if two image patches contain the same content. You might train a specialized comparator that works for animals but not for automobiles or computer programs, but it would be more economical if you had a comparator that works for a wide range of content and could easily be updated to handle novel content. Note that in order to deploy this comparator, you would probably need to use attention and visual servoing to accomplish the task.
These examples constitute special cases of a general workflow that you would probably want a subroutine to handle. Just as the nuclei in the striatum partition sensory-motor content into blocks that map to specific functional circuits in the frontal cortex, so too the prefrontal cortex will have to learn how to map novel content and structure to functional circuits by either adapting existing frontal circuits — preferably without jeopardizing their original function, or developing new subroutines that combine existing functions. The argument here aligns with our general interest in exploiting implicit hierarchy in the form of tail recursive subroutines to simplify behaviors of all sorts and avoid duplication of effort.
Essentially, we are interested in content-adaptive subroutines. One way to facilitate these involves not only organizing content in blocks as mentioned in the previous paragraph, but also standardizing formats within blocks. For example, it might make sense to use a standard format for all the higher-order association areas that contribute to the BG and PFC, e.g., fixed-dimension, normalized embedding vectors. The relatively small variation in the size of cortical stripes suggests that evolution has already stumbled on this strategy. One could also think about concatenating such vectors with short "tag" vectors that identify their origin51. This would enable building general-purpose or at least multiple-purpose components that could, for example, take two vectors with the same origin tag, transform the content portion of the vectors into a canonical format and feed them to the general-purpose comparator.
%%% Wed Jul 29 4:16:57 PDT 2020
In order to add two numbers you need to know where those numbers are represented in memory and then copy the representations to a temporary location where appropriate information processing operations can be performed on them. Conceptually, this is no different from identifying the address of a byte code in random-access memory and transferring it to a register in the arithmetic and logic unit where binary circuits specially designed to perform addition can access it. In both cases memory is mapped. The same has to be true for the brain.
For example, if you want to move your arm from its current position in joint space to a new position, relevant information from the appropriate somatosensory and proprioceptive locations in the posterior cortex has to be transferred to working memory locations in the frontal cortex where the motor areas can expect to find this particular information. The prefrontal cortex has to rely on the same sort of capability in performing abstract cognitive functions; the only difference is that the PFC has to create the necessary memory map and learn how to transfer information – often generated by novel sources — from locations in working memory to specific circuits in the frontal cortex that perform the necessary processing.
Cognitive processing circuits in the prefrontal cortex, unlike those involving physical movement, are not guaranteed to be located in highly-conserved, phenotypically-stereotyped locations and so this too has to be learned by the prefrontal cortex; however – at least in some cases – the prefrontal cortex may be predisposed to employ specific circuits in frontal cortex that do serve evolutionarily or developmentally conserved operations, but it must do so in such a way that those operations are not compromised in the process of integrating new cognitive functions.
Given that as engineers building network architectures unfettered by having to slavishly recapitulate biology, why wouldn't we simply initialize the architecture with a collection of functionally agnostic interchangeable networks and allow the executive control network analogue to sort out their functional assignments in a manner that supports transfer learning and at the same time avoids negative consequences of catastrophic interference?
We could, for example, allow the executive control network to add new networks to the collection or augment existing networks by either adding or augmenting layers in the same way that the hippocampus adds new dentate gyrus granule cells ostensibly to improve pattern separation and integration [3]. Research on transfer learning from Raia Hadsell's team at Deepmind offers several promising approaches to avoiding catastrophic inference, e.g., see Rusu et al [112] on progressive neural networks and Kirkpatrick et al [69] on elastic weight consolidation.
From a neuroscience perspective, there are benefits to be had from co-locating different brain functions that build on one another, often relying on one function providing an inductive bias to bootstrap the other. For example, there is evidence to suggest that high-level mathematical expertise and basic number sense share common roots in a set of nonlinguistic brain circuits involving a set of bilateral frontal, intraparietal, and ventrolateral temporal regions [7, 28]. Early development plays an important role in orchestrating the non-destructive integration of the related skills [30, 22].
One quasi biologically inspired approach would be to use a variant of the DNC-enabled subroutine-library strategy described in Figure 11. We could have introduced this approach earlier; however, for pedagogical reasons, we introduced the model shown shown in Figure 20 since it captures the procedural abstraction more directly – at least for many computer scientists. That said the two models are not equivalent and I think it is worth pointing out their differences at least in the case where they potentially impact performance and support transfer learning.
In the model described in Figure 11 of the class notes, the keys in the DNC encode contexts and the values encode separate networks referred to generally as subroutines. For background on the technical use of the word "context" and its relationship with hierarchical reinforcement learning, see the May 31 entry in the 2019 class discussion list or search for the word "contexts" in the 2020 list – use the plural to focus your search. Simply put, a context corresponds to a summary of a perceptual state that serves as a proxy for the true system state augmented with predictions to account for the partial observability of the underlying Markov process. The information that the basal ganglia project forward to working memory in the frontal cortex corresponds to a context.
The keys are conceptually similar to the indices generated by the dentate gyrus in the hippocampal formation, and during learning they are subjected to adjustments in order to make them generally more useful just as we hypothesize that the hippocampus does during reconsolidation. In the case of the subroutine library as we imagine it here, the prefrontal cortex would modulate the augmented perceptual state vector to emphasize those parts most relevant to current subroutine selection – in this case playing the role the basal ganglia working in collaboration with PFC to shape action selection.
The contexts serve as probes – roughly corresponding to stimuli in psychology – for finding appropriate subroutines to run. We expect such probes will partially match several keys and so, in selecting a subroutine to run, the system essentially creates a weighted combination of the DNC values where each weight corresponds to the dot product of one of the keys with the context probe. The idea of combining subroutines in this fashion is intended to address the problem of increasing weight sharing to encourage transfer learning while decreasing weight sharing to avoid the consequences of catastrophic forgetting.
This approach simplifies the procedural abstraction so that planning and execution primarily involve stringing together subroutines and branching instructions and next subroutine selections are carried out by the PFC based on the output of the most recent procedure call. In principle, this architecture could accommodate arbitrary finite-length programs and hence is Turing complete in the strict sense – a somewhat dubious distinction but worth pointing out nonetheless.
References
| [1] |
Josh Abramson, Arun Ahuja, Arthur Brussee, Federico Carnevale, Mary Cassin,
Stephen Clark, Andrew Dudzik, Petko Georgiev, Aurelia Guy, Tim Harley, Felix
Hill, Alden Hung, Zachary Kenton, Jessica Landon, Timothy Lillicrap, Kory
Mathewson, Alistair Muldal, Adam Santoro, Nikolay Savinov, Vikrant Varma,
Greg Wayne, Nathaniel Wong, Chen Yan, and Rui Zhu.
Imitating interactive intelligence.
CoRR, arXiv:2012.05672, 2020.
|
| [2] |
Jader Abreu, Luis Fred, David Macêdo, and Cleber Zanchettin.
Hierarchical attentional hybrid neural networks for document
classification.
CoRR, arXiv:1901.06610, 2019.
|
| [3] |
J. B. Aimone, J. Wiles, and F. H. Gage.
Computational influence of adult neurogenesis on memory encoding.
Neuron, 61(2):187--202, 2009.
|
| [4] |
Ben Alderson-Day and Charles Fernyhough.
Inner speech: Development, cognitive functions, phenomenology, and
neurobiology.
Psychological bulletin, 141:931--965, 2015.
|
| [5] |
Ben Alderson-Day, Simon McCarthy-Jones, and Charles Fernyhough.
Hearing voices in the resting brain: A review of intrinsic functional
connectivity research on auditory verbal hallucinations.
Neuroscience and Biobehavioral Reviews, 55:78--87, 2015.
|
| [6] |
Miltiadis Allamanis and Marc Brockschmidt.
Smartpaste: Learning to adapt source code.
CoRR, arXiv:1705.07867, 2017.
|
| [7] |
Marie Amalric and Stanislas Dehaene.
Origins of the brain networks for advanced mathematics in expert
mathematicians.
Proceedings of the National Academy of Sciences,
113(18):4909--4917, 2016.
|
| [8] |
Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein.
Deep compositional question answering with neural module networks.
CoRR, arXiv:1511.02799, 2015.
|
| [9] |
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong,
Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, and Wojciech Zaremba.
Hindsight experience replay.
CoRR, arXiv:1707.01495, 2017.
|
| [10] |
Susan. E. Gathercole Anne-Marie Adams.
Limitations in working memory: implications for language development.
International Journal of Language & Communication Disorders,
35(1):95--116, 2000.
|
| [11] |
Bernard Baars, Stan Franklin, and Thomas Ramsy.
Global workspace dynamics: Cortical "binding and propagation" enables
conscious contents.
Frontiers in Psychology, 4:200, 2013.
|
| [12] |
A. Baddeley, S. Gathercole, and C. Papagno.
The phonological loop as a language learning device.
Psychological Review, 105(1):158--173, 1998.
|
| [13] |
Alan Baddeley and Graham James Hitch.
Working memory.
In G.A. Bower, editor, Recent Advances in Learning and
Motivation, volume 8, pages 47--90. Academic Press, 1974.
|
| [14] |
Andrea Banino, Adrià Puigdomènech Badia, Raphael Köster, Martin J.
Chadwick, Vinícius Flores Zambaldi, Demis Hassabis, Caswell Barry,
Matthew M Botvinick, Dharshan Kumaran, and Charles Blundell.
Memo: A deep network for flexible combination of episodic memories.
CoRR, arXiv:2001.10913, 2020.
|
| [15] |
Yoshua Bengio, Nicholas Léonard, and Aaron C. Courville.
Estimating or propagating gradients through stochastic neurons for
conditional computation.
CoRR, arXiv:1308.3432, 2013.
|
| [16] |
Valentino Braitenberg.
Cell assemblies in the cerebral cortex.
In Roland Heim and Günther Palm, editors, Theoretical
Approaches to Complex Systems, pages 171--188, Berlin, Heidelberg, 1978.
Springer Berlin Heidelberg.
|
| [17] |
R. L. Buckner.
The cerebellum and cognitive function: 25 years of insight from
anatomy and neuroimaging.
Neuron, 80(3):807--815, 2013.
|
| [18] |
Ryan T. Canolty, Karunesh Ganguly, Steven W. Kennerley, Charles F. Cadieu,
Kilian Koepsell, Jonathan D. Wallis, and Jose M. Carmena.
Oscillatory phase coupling coordinates anatomically dispersed
functional cell assemblies.
Proceedings of the National Academy of Sciences,
107:17356--17361, 2010.
|
| [19] |
Meredyth Daneman and Philip M. Merikle.
Working memory and language comprehension: A meta-analysis.
Psychonomic Bulletin & Review, 3:422--433, 1996.
|
| [20] |
Yann N. Dauphin, Angela Fan, Michael Auli, and David Grangier.
Language modeling with gated convolutional networks.
CoRR, arXiv:1612.08083, 2017.
|
| [21] |
Peter Dayan.
Improving generalization for temporal difference learning: The
successor representation.
Neural Computation, 5:613--624, 1993.
|
| [22] |
Maria Dolores de Hevia, Véronique Izard, Aurélie Coubart, Elizabeth S.
Spelke, and Arlette Streri.
Representations of space, time, and number in neonates.
Proceedings of the National Academy of Sciences,
111(13):4809--4813, 2014.
|
| [23] |
Terrence W. Deacon.
The Symbolic Species: The Co-evolution of Language and the
Brain.
W. W. Norton, 1998.
|
| [24] |
Terrence W. Deacon.
Incomplete Nature: How Mind Emerged from Matter.
W. W. Norton, 2012.
|
| [25] |
B. Deen, H. Richardson, D. D. Dilks, A. Takahashi, B. Keil, L. L. Wald,
N. Kanwisher, and R. Saxe.
Organization of high-level visual cortex in human infants.
Nature Communications, 8:13995, 2017.
|
| [26] |
S. Dehaene, M. Piazza, P. Pinel, and L. Cohen.
Three parietal circuits for number processing.
Cognitive Neuropsychology, 20(3):487--506, 2003.
|
| [27] |
Stanislas Dehaene.
Consciousness and the Brain: Deciphering How the Brain Codes Our
Thoughts.
Viking Press, 2014.
|
| [28] |
Stanislas Dehaene and Elizabeth Brannon.
Space, Time and Number in the Brain: Searching for the
Foundations of Mathematical Thought.
Elsevier Science, 2011.
|
| [29] |
Stanislas Dehaene, Michel Kerszberg, and Jean-Pierre Changeux.
A neuronal model of a global workspace in effortful cognitive tasks.
Proceedings of the National Academy of Sciences,
95:14529--14534, 1998.
|
| [30] |
G. Dehaene-Lambertz and E.S. Spelke.
The infancy of the human brain.
Neuron, 88(1):93--109, 2015.
|
| [31] |
Timo Denk.
Linear relationships in the transformer's positional encoding.
https://timodenk.com/blog/linear-relationships-in-the-transformers-positional-encoding/,
2019.
|
| [32] |
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova.
BERT: pre-training of deep bidirectional transformers for language
understanding.
CoRR, arXiv:1810.04805, 2018.
|
| [33] |
F. Donnarumma, R. Prevete, F. Chersi, and G. Pezzulo.
A programmer-interpreter neural network architecture for prefrontal
cognitive control.
International Journal Neural Systems, 25(6):1550017, 2015.
|
| [34] |
Kenji Doya.
Complementary roles of basal ganglia and cerebellum in learning and
motor control.
Current Opinion in Neurobiology, 10(6):732--739, 2000.
|
| [35] |
Yan Duan, Marcin Andrychowicz, Bradly C. Stadie, Jonathan Ho, Jonas Schneider,
Ilya Sutskever, Pieter Abbeel, and Wojciech Zaremba.
One-shot imitation learning.
CoRR, arXiv:1703.07326, 2017.
|
| [36] |
Gerald M. Edelman and Giulio Tononi.
A Universe of Consciousness: How Matter Becomes Imagination.
Basic Books, 2000.
|
| [37] |
Kevin Ellis, Catherine Wong, Maxwell Nye, Mathias Sable-Meyer, Luc Cary, Lucas
Morales, Luke Hewitt, Armando Solar-Lezama, and Joshua B. Tenenbaum.
Dreamcoder: Growing generalizable, interpretable knowledge with
wake-sleep bayesian program learning.
CoRR, arXiv:2006.08381, 2020.
|
| [38] |
Nick C. Ellis.
Working memory in the acquisition of vocabulary and syntax: Putting
language in good order.
The Quarterly Journal of Experimental Psychology Section A,
49(1):234--250, 1996.
|
| [39] |
K. Anders Ericsson and Walter Kintsch.
Long-term working memory.
Psychological Review, 102(2):211--245, 1995.
|
| [40] |
Sabrina Fava.
Fairy tales in italy during the 20th century and the translations of
tales of long ago.
Libri & Liberi, 5(2):373--394, 2016.
|
| [41] |
Charles Fernyhough.
The Voices Within: The History and Science of How We Talk to
Ourselves.
Basic Books, 2016.
|
| [42] |
Charles Fernyhough and Simon McCarthy-Jones.
Thinking aloud about mental voices.
In Fiona Macpherson and Dimitris Platchias, editors, Hallucination: Philosophy and Psychology. The MIT Press, 2013.
|
| [43] |
Jason Fischer, John G. Mikhael, Joshua B. Tenenbaum, and Nancy Kanwisher.
Functional neuroanatomy of intuitive physical inference.
Proceedings of the National Academy of Sciences,
113(34):E5072--E5081, 2016.
|
| [44] |
Karl Friston.
What is optimal about motor control?
Neuron, 72(3):488--498, 2011.
|
| [45] |
M. C. Fu.
Monte carlo tree search: A tutorial.
In M. Rabe, A. A. Juan, N. Mustafee, A. Skoogh, S. Jain, and
B. Johansson, editors, 2018 Winter Simulation Conference (WSC), pages
222--236, 2018.
|
| [46] |
Chao Gao, Martin Müller, and Ryan Hayward.
Three-head neural network architecture for monte carlo tree search.
In Proceedings of the Twenty-Seventh International Joint
Conference on Artificial Intelligence, IJCAI-18, pages 3762--3768.
International Joint Conferences on Artificial Intelligence Organization,
2018.
|
| [47] |
Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin.
Convolutional sequence to sequence learning.
CoRR, axXiv:1705.03122, 2017.
|
| [48] |
Samuel J. Gershman and Nathaniel D. Daw.
Reinforcement learning and episodic memory in humans and animals:
An integrative framework.
Annual Reviews of Psychology, 68:101--128, 2017.
|
| [49] |
Alex Graves, Greg Wayne, and Ivo Danihelka.
Neural Turing machines.
CoRR, arXiv:1410.5401, 2014.
|
| [50] |
Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka
Grabska-Barwińska, Sergio Gómez Colmenarejo, Edward Grefenstette,
Tiago Ramalho, John Agapiou, Adrià Puigdoménech Badia, Karl Moritz
Hermann, Yori Zwols, Georg Ostrovski, Adam Cain, Helen King, Christopher
Summerfield, Phil Blunsom, Koray Kavukcuoglu, and Demis Hassabis.
Hybrid computing using a neural network with dynamic external memory.
Nature, 538:471--476, 2016.
|
| [51] |
Sanket Gujar.
Generative adversarial imitation learning.
https://medium.com/@sanketgujar95/generative-adversarial-imitation-learning-266f45634e60,
2018.
|
| [52] |
T. E. Hazy, M. J. Frank, and R. C. O'Reilly.
Towards an executive without a homunculus: computational models of
the prefrontal cortex/basal ganglia system.
Philosophical Transactions of the Royal Society London B,
Biological Science, 362(1485):1601--1613, 2007.
|
| [53] |
G. Hickok and S.L. Small.
Neurobiology of Language.
Elsevier, 2015.
|
| [54] |
Gregory Hickok.
The functional neuroanatomy of language.
Physics of Life Reviews, 6:121--143, 2009.
|
| [55] |
Gregory Hickok and David Poeppel.
The cortical organization of speech processing.
Nature Reviews Neuroscience, 8:393, 2007.
|
| [56] |
Jonathan Ho and Stefano Ermon.
Generative adversarial imitation learning.
In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett,
editors, Advances in Neural Information Processing Systems, volume 29,
pages 4565--4573. Curran Associates, Inc., 2016.
|
| [57] |
Marc W. Howard, Mrigankka S. Fotedar, Aditya V. Datey, and Michael E. Hasselmo.
The temporal context model in spatial navigation and relational
learning: toward a common explanation of medial temporal lobe function across
domains.
Psychological review, 112:75--116, 2005.
|
| [58] |
Marc W. Howard and Michael J. Kahana.
A distributed representation of temporal context.
Journal of Mathematical Psychology, 46(3):269--299, 2002.
|
| [59] |
Ronghang Hu, Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Kate Saenko.
Learning to reason: End-to-end module networks for visual question
answering.
CoRR, arXiv:1704.05526, 2017.
|
| [60] |
Ahmed Hussein, Mohamed Medhat Gaber, Eyad Elyan, and Chrisina Jayne.
Imitation learning: A survey of learning methods.
ACM Computing Surveys, 50(2), 2017.
|
| [61] |
Alexander G. Huth, Wendy A. de Heer, Thomas L. Griffiths, Frèdèric E.
Theunissen, and Jack L. Gallant.
Natural speech reveals the semantic maps that tile human cerebral
cortex.
Nature, 532:453--458, 2016.
|
| [62] |
Wengong Jin, Regina Barzilay, and Tommi Jaakkola.
Multi-objective molecule generation using interpretable
substructures.
In Proceedings of the 37th International Conference on Machine
Learning, volume arXiv:2002.03244, 2020.
|
| [63] |
Neal F. Johnson.
The role of chunking and organization in the process of recall.
In Gordon H. Bower, editor, Psychology of Learning and
Motivation, volume 4, pages 171--247. Academic Press, 1970.
|
| [64] |
Simon R. Jones and Charles Fernyhough.
Neural correlates of inner speech and auditory verbal hallucinations:
A critical review and theoretical integration.
Clinical Psychology Review, 27(2):140--154, 2007.
|
| [65] |
Hannah R. Joo and Loren M. Frank.
The hippocampal sharp wave-ripple in memory retrieval for immediate
use and consolidation.
Nature Reviews Neuroscience, 19:744--757, 2018.
|
| [66] |
Frederik S. Kamps, Joshua B. Julian, Peter Battaglia, Barbara Landau, Nancy
Kanwisher, and Daniel D. Dilks.
Dissociating intuitive physics from intuitive psychology: Evidence
from williams syndrome.
Cognition, 168:146--153, 2017.
|
| [67] |
Amirhossein Kazemnejad.
Transformer architecture: The role of positional encoding.
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/,
2019.
|
| [68] |
Renu Khandelwal.
An intuitive explanation of beam search - towards data science,
february 1, 2018.
https://towardsdatascience.com/an-intuitive-explanation-of-beam-search-9b1d744e7a0f,
2018.
|
| [69] |
James Kirkpatrick, Razvan Pascanu, Neil C. Rabinowitz, Joel Veness, Guillaume
Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka
Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and
Raia Hadsell.
Overcoming catastrophic forgetting in neural networks.
CoRR, arXiv:1612.00796, 2016.
|
| [70] |
Etienne Koechlin, Gregory Corrado, Pietro Pietrini, and Jordan Grafman.
Dissociating the role of the medial and lateral anterior prefrontal
cortex in human planning.
Proceedings of the National Academy of Sciences, 97:7651--7656,
2000.
|
| [71] |
Etienne Koechlin, Chrystèle Ody, and Frédérique Kouneiher.
The architecture of cognitive control in the human prefrontal cortex.
Science, 302:1181--1185, 2003.
|
| [72] |
Trenton Kriete, David C. Noelle, Jonathan D. Cohen, and Randall C. O'Reilly.
Indirection and symbol-like processing in the prefrontal cortex and
basal ganglia.
Proceedings of the National Academy of Sciences, 2013.
|
| [73] |
Dharshan Kumaran, Demis Hassabis, and James L. McClelland.
What learning systems do intelligent agents need? Complementary
learning systems theory updated.
Trends in Cognitive Sciences, 20(7):512--534, 2016.
|
| [74] |
Dharshan Kumaran and James L. McClelland.
Generalization through the recurrent interaction of episodic
memories: A model of the hippocampal system.
Psychology Review, 119:573--616, 2012.
|
| [75] |
Junyeop Lee, Sungrae Park, Jeonghun Baek, Seong Joon Oh, Seonghyeon Kim, and
Hwalsuk Lee.
On recognizing texts of arbitrary shapes with 2-D self-attention.
CoRR, arXiv:1910.04396, 2019.
|
| [76] |
Adam H. Marblestone, Greg Wayne, and Konrad P. Kording.
Toward an integration of deep learning and neuroscience.
Frontiers in Computational Neuroscience, 10:94, 2016.
|
| [77] |
George A. Mashour, Pieter Roelfsema, Jean-Pierre Changeux, and Stanislas
Dehaene.
Conscious processing and the global neuronal workspace hypothesis.
Neuron, 105(5):776--798, 2020.
|
| [78] |
M. G. Mattar and N. D. Daw.
Prioritized memory access explains planning and hippocampal replay.
Nature Neuroscience, 21(11):1609--1617, 2018.
|
| [79] |
Marcelo G. Mattar and Nathaniel D. Daw.
Prioritized memory access explains planning and hippocampal replay.
Nature Neuroscience, 21:1609--1617, 2018.
|
| [80] |
James L. McClelland, Bruce L. McNaughton, and Randall C. O'Reilly.
Why there are complementary learning systems in the hippocampus and
neocortex: Insights from the successes and failures of connectionist models
of learning and memory.
Psychological Review, 102:419--457, 1995.
|
| [81] |
Johnjoe McFadden.
Integrating information in the brain's EM field: the CEMI field
theory of consciousness.
Neuroscience of Consciousness, 2020(1), 2020.
|
| [82] |
Stephen Mcgregor and Kyungtae Lim.
Affordances in grounded language learning.
In ACL 2018 Workshop on Cognitive Aspects of Computational
Language Learning and Processing, 2018.
|
| [83] |
Josh Merel, Matt Botvinick, and Greg Wayne.
Hierarchical motor control in mammals and machines.
Nature Communications, 10(1):5489, 2019.
|
| [84] |
Josh Merel, Leonard Hasenclever, Alexandre Galashov, Arun Ahuja, Vu Pham, Greg
Wayne, Yee Whye Teh, and Nicolas Heess.
Neural probabilistic motor primitives for humanoid control.
In International Conference on Learning Representations, 2019.
|
| [85] |
Marvin L. Minsky.
Recursive Unsolvability of Post's Problem of "Tag" and other Topics
in Theory of Turing Machines.
Annals of Mathematics, 74(3):437--455, 1961.
|
| [86] |
Melanie Mitchell.
Review of figments of reality by ian stewart and jack cohen cambridge
university press, 1997.
New Scientist, August 1997.
|
| [87] |
Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves,
Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu.
Asynchronous methods for deep reinforcement learning.
CoRR, arXiv:1602.01783, 2016.
|
| [88] |
Volodymyr Mnih, Nicolas Heess, Alex Graves, and Koray Kavukcuoglu.
Recurrent models of visual attention.
CoRR, arXiv:1406.6247, 2014.
|
| [89] |
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis
Antonoglou, Daan Wierstra, and Martin Riedmiller.
Playing Atari with deep reinforcement learning.
CoRR, arXiv:1312.5602, 2013.
|
| [90] |
Dharmendra S. Modha and Raghavendra Singh.
Network architecture of the long-distance pathways in the macaque
brain.
Proceedings of the National Academy of Sciences,
107(30):13485--13490, 2010.
|
| [91] |
Ida Momennejad.
Learning structures: Predictive representations, replay, and
generalization.
Current Opinion in Behavioral Sciences, 32:155--166, 2020.
|
| [92] |
Igor Mordatch, Kendall Lowrey, Galen Andrew, Zoran Popovic, and Emanuel V.
Todorov.
Interactive control of diverse complex characters with neural
networks.
In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett,
editors, Advances in Neural Information Processing Systems 28, pages
3132--3140. Curran Associates, Inc., 2015.
|
| [93] |
Aviv Navon, Idan Achituve, Haggai Maron, Gal Chechik, and Ethan Fetaya.
Auxiliary learning by implicit differentiation.
CoRR, arXiv:2007.02693, 2020.
|
| [94] |
John von Neumann.
First draft of a report on the EDVAC.
Technical report, Institute for Advanced Study, 1945.
|
| [95] |
Austin Nguyen.
Four ways to boost experience replay: Making agents remember the
important things.
https://towardsdatascience.com/4-ways-to-boost-experience-replay-999d9f17f7b6,
2019.
|
| [96] |
Kenneth Norman and Randall O'Reilly.
Modeling hippocampal and neocortical contributions to recognition
memory: A complementary learning systems approach.
Psychological review, 110:611--46, 2003.
|
| [97] |
Randall C. O'Reilly, Rajan Bhattacharyya, Michael D. Howard, and Nicholas Ketz.
Complementary learning systems.
Cognitive Science, 38(6):1229--1248, 2014.
|
| [98] |
Randall C. O'Reilly and Michael J. Frank.
Making working memory work: A computational model of learning in the
prefrontal cortex and basal ganglia.
Neural Computation, 18:283--328, 2006.
|
| [99] |
Randall C. O'Reilly, Yuko Munakata, Michael J. Frank, and Thomas E. Hazy
Contributors.
Computational Cognitive Neuroscience.
Wiki Book, 4th Edition, 2020.
|
| [100] |
Randall C. O'Reilly and R. Soto.
A model of the phonological loop: Generalization and binding.
In T. G. Dietterich, S. Becker, and Z. Ghahramani, editors, Advances in Neural Information Processing Systems 14, pages 83--90. MIT
Press, 2002.
|
| [101] |
Torben Ott and Andreas Nieder.
Dopamine and cognitive control in prefrontal cortex.
Trends in Cognitive Sciences, 23(3):213--234, 2019.
|
| [102] |
L.A. Petitto and P.F. Marentette.
Babbling in the manual mode: evidence for the ontogeny of language.
Science, 251(5000):1493--1496, 1991.
|
| [103] |
Laura Ann Petitto, Siobhan Holowka, Lauren E. Sergio, and David Ostry.
Language rhythms in baby hand movements.
Nature, 413:35--36, 2001.
|
| [104] |
Thomas Pierrot, Guillaume Ligner, Scott E. Reed, Olivier Sigaud, Nicolas
Perrin, Alexandre Laterre, David Kas, Karim Beguir, and Nando de Freitas.
Learning compositional neural programs with recursive tree search and
planning.
CoRR, arXiv:1905.12941, 2019.
|
| [105] |
David Poeppel, Karen Emmorey, Gregory Hickok, and Liina Pylkkanen.
Towards a new neurobiology of language.
The Journal of Neuroscience: The official journal of the Society
for Neuroscience, 32:14125--14131, 2012.
|
| [106] |
F. Pulvermüller, M. Garagnani, and T. Wennekers.
Thinking in circuits: toward neurobiological explanation in cognitive
neuroscience.
Biological Cybernetics, 108(5):573--593, 2014.
|
| [107] |
Friedemann Pulvermüller.
How neurons make meaning: brain mechanisms for embodied and
abstract-symbolic semantics.
Trends in Cognitive Sciences, 17(9):458--470, 2013.
|
| [108] |
Friedemann Pulvermüller.
Neural reuse of action perception circuits for language, concepts and
communication.
Progress in Neurobiology, 160:1--44, 2018.
|
| [109] |
Rajesh P. N. Rao and Dana H. Ballard.
Predictive coding in the visual cortex: a functional interpretation
of some extra-classical receptive-field effects.
Nature Neuroscience, 2:79--87, 1999.
|
| [110] |
Scott E. Reed and Nando de Freitas.
Neural programmer-interpreters.
CoRR, arXiv:1511.06279, 2015.
|
| [111] |
Alexander Rush.
The annotated transformer.
In Proceedings of Workshop for NLP Open Source Software
(NLP-OSS), pages 52--60, Melbourne, Australia, 2018. Association for
Computational Linguistics.
|
| [112] |
Andrei A. Rusu, Neil C. Rabinowitz, Guillaume Desjardins, Hubert Soyer, James
Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell.
Progressive neural networks.
CoRR, arXiv:1606.04671, 2016.
|
| [113] |
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver.
Prioritized experience replay.
CoRR, arXiv:1511.05952, 2015.
|
| [114] |
Sungyong Seo, Jing Huang, Hao Yang, and Yan Liu.
Interpretable convolutional neural networks with dual local and
global attention for review rating prediction.
In Proceedings of the Eleventh ACM Conference on Recommender
Systems, pages 297--305, New York, NY, USA, 2017. Association for Computing
Machinery.
|
| [115] |
Murray Shanahan.
The brain's connective core and its role in animal cognition.
Philosophical Transactions of the Royal Society B: Biological
Sciences, 367(1603):2704--2714, 2012.
|
| [116] |
Amr Sharaf.
Inroduction to pointer networks - medium, june 2, 2017.
https://medium.com/@sharaf/a-paper-a-day-11-pointer-networks-59f7af1a611c,
2017.
|
| [117] |
Richard Shin, Illia Polosukhin, and Dawn Song.
Towards specification-directed program repair.
In Submitted to International Conference on Learning
Representations, 2018.
|
| [118] |
Vighnesh Leonardo Shiv and Chris Quirk.
Novel positional encodings to enable tree-based transformers.
In NeurIPS 2019, 2019.
|
| [119] |
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George
van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda
Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal
Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray
Kavukcuoglu, Thore Graepel, and Demis Hassabis.
Mastering the game of go with deep neural networks and tree search.
Nature, 529:484--489, 2016.
|
| [120] |
Abhishek Singh.
Understanding pointer networks - medium, may 24, 2017.
https://towardsdatascience.com/understanding-pointer-networks-81fbbc1ddbc8,
2017.
|
| [121] |
Kimberly L. Stachenfeld, Matthew M. Botvinick, and Samuel J. Gershman.
The hippocampus as a predictive map.
Nature Neuroscience, 20(1643):1643--1653, 2017.
|
| [122] |
Ian Stewart and Jack Cohen.
Figments of Reality: The Evolution of the Curious Mind.
Cambridge University Press, 1997.
|
| [123] |
Ian Stewart, Jack Cohen, and Terry Pratchett.
The Science Of Discworld II: The Globe.
Ebury Publishing, 2015.
|
| [124] |
Ian Stewart, Jack Cohen, and Terry Pratchett.
Science of Discworld III: Darwin's Watch.
Ebury Publishing, 2015.
|
| [125] |
Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus.
End-to-end memory networks.
In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett,
editors, Advances in Neural Information Processing Systems 28, pages
2440--2448. Curran Associates, Inc., 2015.
|
| [126] |
Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus.
Weakly supervised memory networks.
CoRR, arXiv:1503.08895, 2015.
|
| [127] |
Naftali Tishby and Daniel Polani.
Information theory of decisions and actions.
In V. Cutsuridis, A. Hussain, and J.G. Taylor, editors, Perception-Action Cycle: Models, Architectures, and Hardware. Springer New
York, 2011.
|
| [128] |
Joshua Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and
Pieter Abbeel.
Domain randomization for transferring deep neural networks from
simulation to the real world.
CoRR, arXiv:1703.06907, 2017.
|
| [129] |
E. Todorov and Z. Ghahramani.
Unsupervised learning of sensory-motor primitives.
In Proceedings of the 25th Annual International Conference of
the IEEE Engineering in Medicine and Biology Society, volume 2, pages
1750--1753, 2003.
|
| [130] |
Emanuel Todorov and Michael I. Jordan.
Optimal feedback control as a theory of motor coordination.
Nature Neuroscience, 5:1226--1235, 2002.
|
| [131] |
Barbara Tversky.
Mind in Motion: How Action Shapes Thought.
Basic Books, 2019.
|
| [132] |
Aäron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu.
Neural discrete representation learning.
CoRR, arXiv:1711.00937, 2017.
|
| [133] |
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin.
Attention is all you need.
CoRR, arXiv:1706.03762, 2017.
|
| [134] |
Oriol Vinyals, Igor Babuschkin, Wojciech M. Czarnecki, Michal Mathieu, Andrew
Dudzik, Junyoung Chung, David H. Choi, Richard Powell, Timo Ewalds, Petko
Georgiev, Junhyuk Oh, Dan Horgan, Manuel Kroiss, Ivo Danihelka, Aja Huang,
Laurent Sifre, Trevor Cai, John P. Agapiou, Max Jaderberg, Alexander S.
Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalibard, David
Budden, Yury Sulsky, James Molloy, Tom L. Paine, Caglar Gulcehre, Ziyu Wang,
Tobias Pfaff, Yuhuai Wu, Roman Ring, Dani Yogatama, Dario Wunsch, Katrina
McKinney, Oliver Smith, Tom Schaul, Timothy Lillicrap, Koray Kavukcuoglu,
Demis Hassabis, Chris Apps, and David Silver.
Grandmaster level in starcraft ii using multi-agent reinforcement
learning.
Nature, 575:350--354, 2019.
|
| [135] |
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly.
Pointer networks.
In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett,
editors, Advances in Neural Information Processing Systems 28, pages
2692--2700. Curran Associates, Inc., 2015.
|
| [136] |
John von Neumann.
Probabilistic logics and the synthesis of reliable organisms from
unreliable components.
In Claude E. Shannon and John McCarthy, editors, Automata
Studies, pages 329--378. Princeton University Press, Princeton, NJ, 1956.
|
| [137] |
John von Neumann.
The computer and the brain.
The Silliman Memorial Lectures Series. Yale University Press, 1958.
|
| [138] |
John von Neumann.
Theory of Self-Reproducing Automata.
University of Illinois Press, Urbana, IL, 1966.
|
| [139] |
Chenglong Wang, Po-Sen Huang, Alex Polozov, Marc Brockschmidt, and Rishabh
Singh.
Execution-guided neural program decoding.
CoRR, arXiv:1807.03100, 2018.
|
| [140] |
Ke Wang, Rishabh Singh, and Zhendong Su.
Dynamic neural program embedding for program repair.
CoRR, arXiv:1711.07163, 2017.
|
| [141] |
Linnan Wang, Yiyang Zhao, and Yuu Jinnai.
AlphaX: eXploring Neural Architectures with Deep Neural Networks and
Monte Carlo Tree Search.
CoRR, arXiv:1805.07440, 2018.
|
| [142] |
Xin Wang, Xiaotao Jiang, Gloria Rumbidzai Regedzai, Haohao Meng, and Lingyun
Sun.
Gated neural network framework for interactive character control.
Multimedia Tools and Applications, 2020.
|
| [143] |
Ziyu Wang, Josh Merel, Scott Reed, Greg Wayne, Nicolas Heess Nando de Freitas,
Ziyu Wang, Josh Merel, Scott Reed, Greg Wayne, Nando de Freitas, and Nicolas
Heess.
Robust imitation of diverse behaviors.
In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus,
S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information
Processing Systems 30, pages 5320--5329. Curran Associates, Inc., 2017.
|
| [144] |
K.E Watkins, A.P. Strafella, and T. Paus.
Seeing and hearing speech excites the motor system involved in speech
production.
Neuropsychologia, 41(8):989--994, 2003.
|
| [145] |
Greg Wayne, Chia-Chun Hung, David Amos, Mehdi Mirza, Arun Ahuja, Agnieszka
Grabska-Barwinska, Jack Rae, Piotr Mirowski, Joel Z. Leibo, Adam Santoro,
Mevlana Gemici, Malcolm Reynolds, Tim Harley, Josh Abramson, Shakir Mohamed,
Danilo Rezende, David Saxton, Adam Cain, Chloe Hillier, David Silver, Koray
Kavukcuoglu, Matt Botvinick, Demis Hassabis, and Timothy Lillicrap.
Unsupervised predictive memory in a goal-directed agent.
CoRR, arXiv:1803.10760, 2018.
|
| [146] |
Jason Weston, Antoine Bordes, Sumit Chopra, and Tomas Mikolov.
Towards ai-complete question answering: A set of prerequisite toy
tasks.
CoRR, arXiv:1502.05698, 2015.
|
| [147] |
Representation Learning with Contrastive Predictive Coding.
Aaron van den oord and yazhe li and oriol vinyals.
CoRR, arXiv:1807.03748, 2018.
|
| [148] |
Ludwig Wittgenstein.
Philosophical Investigations.
John Wiley & Sons, 2009.
|
1 Extelligence is a term coined by Ian Stewart and Jack Cohen in their 1997 book Figments of Reality [122] – which reminded me of Terrence Deacon's Symbolic Species [23] and its extension in Incomplete Nature [24]. Stuart and Cohen define extelligence as the cultural capital that is available to us in the form of external media such as tribal legends, folklore and nursery rhymes:
They contrast extelligence with intelligence, or the knowledge and cognitive processes within the brain. Furthermore, they regard the complicity of extelligence and intelligence as fundamental to the development of consciousness in evolutionary terms for both the species and the individual. Complicity is a combination of complexity and simplicity, and Cohen and Stewart use it to express the interdependent relationship between knowledge-inside-one's-head and knowledge-outside-one's-head that can be readily accessed.Although Cohen's and Stewart's respective disciplines are biology and mathematics, their description of the complicity of intelligence and extelligence is in the tradition of Jean Piaget, Belinda Dewar and David A. Kolb. Philosophers, notably Popper, have also considered the relation between subjective knowledge (which he calls world 2), objective knowledge (world 1) and the knowledge represented by man-made artifacts (world 3).
One of Cohen and Stewart's contributions is the way they relate, through the idea of complicity, the individual to the sum of human knowledge. From the mathematics of complexity and game theory, they use the idea of phase space and talk about extelligence space. There is a total phase space (intelligence space) for the human race, which consists of everything that can be known and represented. Within this there is a smaller set of what is known at any given time. Cohen and Stewart propose the idea that each individual can access the parts of the extelligence space with which their intelligence is complicit. (SOURCE)
2 Thanks for bringing to my attention the topic of auxiliary learning discussed in the Abramson et al paper. I had assumed it was just a matter of adding another term to the objective function in order to facilitate such learning. Clearly they are doing something more interesting / sophisticated. I don't know how familiar you are with designing objective functions – also referred to as loss or cost functions – in developing deep neural networks. I have to say it's generally considered to be more art than science, though of course there are cases in which it is relatively straightforward.
I expect you are familiar with the simple loss functions that are used in classifiers and the use of Kullback-Leibler (or simply KL) divergence to measure "distance" between two distributions as in the case of training variational autoencoders. (KL divergence isn't strictly a distance metric since it doesn't satisfy the triangle inequality.)
A friend of mine, Adam Marblestone wrote an interesting but somewhat controversial paper [76] with Greg Wayne and Konrad Kording arguing that the brain uses multiple objective functions. It is an interesting paper, but they were using the phrase "objective function" in a generic sense, not altogether compatible with the role of objective functions in developing artificial neural networks. One major hurdle concerns how the brain coordinates multiple objectives.
The obvious but ad hoc method of representing the overall loss as the weighted average of several separate terms allows the developer to tweek the weights experimentally, but is considered an unprincipled kludge and last resort when in a hurry to submit a paper. Abramson et al have a somewhat more disciplined approach.
When I was searching for other related work I ran across a paper [93] submitted to ICLR 2021 that proposes a more general / principled approach in which the system learns how to combine different objectives corresponding to different tasks. I haven't yet read the paper in its entirety, but I worked with Gal Chechik, one of the co-authors, during his sabbatical at Google and trust him not to allow his name on a paper with technical problems or misleading results. In any case, I thought you might find it interesting / educational to at least scan the abstracts.
@article{NavonetalCoRR-20,
title = {Auxiliary Learning by Implicit Differentiation},
author = {Aviv Navon and Idan Achituve and Haggai Maron and Gal Chechik and Ethan Fetaya},
year = {2020},
journal = {CoRR},
volume = {arXiv:2007.02693},
abstract = {Training with multiple auxiliary tasks is a common practice used in deep learning for improving the performance on the main task of interest. Two main challenges arise in this multi-task learning setting: (i) Designing useful auxiliary tasks; and (ii) Combining auxiliary tasks into a single coherent loss. We propose a novel framework, AuxiLearn, that targets both challenges, based on implicit differentiation. First, when useful auxiliaries are known, we propose learning a network that combines all losses into a single coherent objective function. This network can learn non-linear interactions between auxiliary tasks. Second, when no useful auxiliary task is known, we describe how to learn a network that generates a meaningful, novel auxiliary task. We evaluate AuxiLearn in a series of tasks and domains, including image segmentation and learning with attributes. We find that AuxiLearn consistently improves accuracy compared with competing methods.},
}
@article{MarblestoneetalFiCN-16,
author = {Marblestone, Adam H. and Wayne, Greg and Kording, Konrad P.},
title = {Toward an Integration of Deep Learning and Neuroscience},
journal = {Frontiers in Computational Neuroscience},
volume = {10},
pages = {94},
year = {2016},
abstract = {Neuroscience has focused on the detailed implementation of computation, studying neural codes, dynamics and circuits. In machine learning, however, artificial neural networks tend to eschew precisely designed codes, dynamics or circuits in favor of brute force optimization of a cost function, often using simple and relatively uniform initial architectures. Two recent developments have emerged within machine learning that create an opportunity to connect these seemingly divergent perspectives. First, structured architectures are used, including dedicated systems for attention, recursion and various forms of short- and long-term memory storage. Second, cost functions and training procedures have become more complex and are varied across layers and over time. Here we think about the brain in terms of these ideas. We hypothesize that (1) the brain optimizes cost functions, (2) the cost functions are diverse and differ across brain locations and over development, and (3) optimization operates within a pre-structured architecture matched to the computational problems posed by behavior. In support of these hypotheses, we argue that a range of implementations of credit assignment through multiple layers of neurons are compatible with our current knowledge of neural circuitry, and that the brain's specialized systems can be interpreted as enabling efficient optimization for specific problem classes. Such a heterogeneously optimized system, enabled by a series of interacting cost functions, serves to make learning data-efficient and precisely targeted to the needs of the organism. We suggest directions by which neuroscience could seek to refine and test these hypotheses.}
}
3 The authors [61] relied on a method called voxel modeling that uses word embeddings, principle components analysis and clustering to identify semantic categories and then regularized linear regression to estimate how a derived set of 985 semantic features influenced the BOLD responses in every cortical voxel of individual subjects:
The four shared semantic dimensions provide a way to succinctly summarize the semantic selectivity of a voxel. However, to interpret projections of the models onto these dimensions we need to understand how semantic information is encoded in this four-dimensional space. To visualize the semantic space we projected the 10,470 words in the stories from the word embedding space onto each dimension. We then used k-means clustering to identify twelve distinct categories (see Supplemental Methods for details). Each category was inspected and labeled by hand. The labels assigned to the twelve categories were tactile (a cluster containing words such as "fingers"), visual (words such as "yellow"), numeric ("four"), locational ("stadium"), abstract ("natural"), temporal ("minute"), professional ("meetings"), violent ("lethal"), communal ("schools"), mental ("asleep"), emotional ("despised"), and social ("child"). (SOURCE)
5 Contrastive Predictive Coding (CPC) learns self-supervised representations by predicting the future in latent space by using powerful autoregressive models. The model uses a probabilistic contrastive loss which induces the latent space to capture information that is maximally useful to predict future samples. The authors demon state that their approach is able to learn useful representations achieving strong performance on four distinct domains: speech, images, text and reinforcement learning in 3D environments [147].
4 An exchange concerning the architecture described in the Abramson et al [1] paper and its possible relevance to our choice of VQ-VAE as the encoder network for the transformer layers in our model:
STF: I'm wondering if we can use similar architecture to solve our SIR task. In their case, they have image and language as input and the agent learns by imitating human demonstration. The internal representations of states are entirely trained with imitation learning and contrastive auxiliary losses5. There is no auto-encoder as in Merlin. Do you guys think we really need VAE like auto-encoder to learn state representation? Or we can train the encoder with imitation loss plus some auxiliary loss? My understanding is that VAE could help learn representation that is predictive of next instructions. But this DM doesn't use it and Greg is on the author list so I bet they probably have tried it and found it not working well.TLD: The model described in the Abramson et al paper is incredibly complicated, as one might expect given that the problem the authors propose to solve aspires to a level of competence well beyond the ability of any existing systems and borders on human-level intelligence. The fact that there is no mention of variational autoencoders does not imply to me that Greg had no use for them, but rather that there were alternatives that better addressed the specific challenges of the Abramson problem. In particular, the state space for the Abramson problem covers several modalities each of which has its dedicated transformer stack. It is pretty clear from how the outputs of these modality-specific stacks are combined to create a joint state space that many of the challenges posed by our problem domain either don't arise, don't matter enough to bother with, or are simply finessed in their model since they don't address the primary objectives of their effort. I think the rationale for using VQ-VAE still makes sense for our use case.
6 Ethological motor learning and imitation. Animals and humans efficiently learn motor behaviors throughout life via active exploration, imitation of conspecifics, and subsequent refinement of skills. Although birdsong is a narrow behavior relative to primate motor control, it serves to illustrate some of the multiple requirements—evolutionarily initialized motor variability (babbling") in juvenile songbirds is shaped into skilled behavior by a process of vocal imitation learning followed by self-directed rehearsal. More broadly and across species, intrinsically motivated active exploration is required to learn both about the environment as well as how self-generated behavior can affect the environment. In humans, imitation-based learning begins with observing the movements of others, but can involve inference of the goals of the demonstrator as well as intelligent exploration to imitate their movements or goal-directed activity. Further, it is thought that non-verbal pedagogical behavior is an evolutionary adaptation, and related imitative behavior may have antecedents in the gestural communication already present in some other species.
At present, the conventional forms of artificial "imitation learning" do not yet match the biological inspiration. Contemporary approaches require that demonstrations are essentially performed on the body of the student (e.g., via teleoperation), granting first-person access to demonstrated behavior. Learning from this information is referred to as behavioral cloning, and usually is implemented as a regressioning with unsupervised auxiliary tasks. But recent advances take steps toward more natural imitation. For example, adversarial imitation can scale to humanoids even without access to actions, possibly from only allocentric, video demonstrations. Another particularly exciting and naturalistic development is "one-shot imitation learning", where, after training, the system is presented with a novel demonstration and immediately attempts to reproduce that demonstrated behavior; this style of approach has also been employed for humanoids. As an intermediate representation that supports one-shot observation and imitation of demonstrations, systems may possess an embedding space that simultaneously encodes the demonstrated behavior and reflects what the agent will do. Conceptually, this is similar to the representation identified for mirror neurons. Page 9 in Merel et al [83].
7 Here are the bibliography entries, including the abstracts, for the papers mentioned in the November 27th entry summarizing the currents status of the network architecture model for the TECH project assembled here for your convenience:
@article{KumaranandMcClellandPR-12,
author = {Kumaran, Dharshan and McClelland, James L.},
title = {Generalization Through the Recurrent Interaction of Episodic Memories: A Model of the Hippocampal System},
journal = {Psychology Review},
publisher = {American Psychological Association},
volume = {119},
issue = {3},
year = {2012},
pages = {573-616},
abstract = {In this article, we present a perspective on the role of the hippocampal system in generalization, instantiated in a computational model called REMERGE (recurrency and episodic memory results in generalization). We expose a fundamental, but neglected, tension between prevailing computational theories that emphasize the function of the hippocampus in pattern separation (Marr, 1971; McClelland, McNaughton, \& O'Reilly, 1995), and empirical support for its role in generalization and flexible relational memory (Cohen \& Eichenbaum, 1993; Eichenbaum, 1999). Our account provides a means by which to resolve this conflict, by demonstrating that the basic representational scheme envisioned by complementary learning systems theory (McClelland et al., 1995), which relies upon orthogonalized codes in the hippocampus, is compatible with efficient generalization - as long as there is recurrence rather than unidirectional flow within the hippocampal circuit or, more widely, between the hippocampus and neocortex. We propose that recurrent similarity computation, a process that facilitates the discovery of higher-order relationships between a set of related experiences, expands the scope of classical exemplar-based models of memory (e.g., Nosofsky, 1984) and allows the hippocampus to support generalization through interactions that unfold within a dynamically created memory space.},
}
@article{KumaranetalTiCS-16,
author = {Dharshan Kumaran and Demis Hassabis and James L. McClelland},
title = {What Learning Systems do Intelligent Agents Need? {C}omplementary Learning Systems Theory Updated},
journal = {Trends in Cognitive Sciences},
volume = {20},
number = {7},
year = {2016},
pages = {512-534},
abstract = {We update complementary learning systems (CLS) theory, which holds that intelligent agents must possess two learning systems, instantiated in mammalians in neocortex and hippocampus. The first gradually acquires structured knowledge representations while the second quickly learns the specifics of individual experiences. We broaden the role of replay of hippocampal memories in the theory, noting that replay allows goal-dependent weighting of experience statistics. We also address recent challenges to the theory and extend it by showing that recurrent activation of hippocampal traces can support some forms of generalization and that neocortical learning can be rapid for information that is consistent with known structure. Finally, we note the relevance of the theory to the design of artificial intelligent agents, highlighting connections between neuroscience and machine learning.}
}
@article{GershmanandDawANNUAL-REVIEWS-17,
title = {Reinforcement Learning and Episodic Memory in Humans and Animals: {A}n Integrative Framework},
author = {Samuel J. Gershman and Nathaniel D. Daw},
journal = {Annual Reviews of Psychology},
year = {2017},
volume = {68},
pages = {101-128},
abstract = {We review the psychology and neuroscience of reinforcement learning (RL), which has experienced significant progress in the past two decades, enabled by the comprehensive experimental study of simple learning and decision-making tasks. However, one challenge in the study of RL is computational: The simplicity of these tasks ignores important aspects of reinforcement learning in the real world: (a) State spaces are high-dimensional, continuous, and partially observable; this implies that (b) data are relatively sparse and, indeed, precisely the same situation may never be encountered twice; furthermore, (c) rewards depend on the long-term consequences of actions in ways that violate the classical assumptions that make RL tractable. A seemingly distinct challenge is that, cognitively, theories of RL have largely involved procedural and semantic memory, the way in which knowledge about action values or world models extracted gradually from many experiences can drive choice. This focus on semantic memory leaves out many aspects of memory, such as episodic memory, related to the traces of individual events. We suggest that these two challenges are related. The computational challenge can be dealt with, in part, by endowing RL systems with episodic memory, allowing them to (a) efficiently approximate value functions over complex state spaces, (b) learn with very little data, and (c) bridge long-term dependencies between actions and rewards. We review the computational theory underlying this proposal and the empirical evidence to support it. Our proposal suggests that the ubiquitous and diverse roles of memory in RL may function as part of an integrated learning system.}
}
@article{MomennejadCOiBS-20,
title = {Learning Structures: Predictive Representations, Replay, and Generalization},
author = {Ida Momennejad},
journal = {Current Opinion in Behavioral Sciences},
volume = {32},
pages = {155-166},
year = {2020},
abstract = {Memory and planning rely on learning the structure of relationships among experiences. Compact representations of these structures guide flexible behavior in humans and animals. A century after 'latent learning' experiments summarized by Tolman, the larger puzzle of cognitive maps remains elusive: how does the brain learn and generalize relational structures? This review focuses on a reinforcement learning (RL) approach to learning compact representations of the structure of states. We review evidence showing that capturing structures as predictive representations updated via replay offers a neurally plausible account of human behavior and the neural representations of predictive cognitive maps. We highlight multi-scale successor representations, prioritized replay, and policy-dependence. These advances call for new directions in studying the entanglement of learning and memory with prediction and planning.}
}
@article{MatterandDowNATURE-NEUROSCIENCE-18,
author = {Mattar, M. G. and Daw, N. D.},
title = {Prioritized memory access explains planning and hippocampal replay},
journal = {Nature Neuroscience},
year = {2018},
volume = {21},
number = {11},
pages = {1609-1617},
abstract = {To make decisions, animals must evaluate candidate choices by accessing memories of relevant experiences. Yet little is known about which experiences are considered or ignored during deliberation, which ultimately governs choice. We propose a normative theory predicting which memories should be accessed at each moment to optimize future decisions. Using nonlocal 'replay' of spatial locations in hippocampus as a window into memory access, we simulate a spatial navigation task in which an agent accesses memories of locations sequentially, ordered by utility: how much extra reward would be earned due to better choices. This prioritization balances two desiderata: the need to evaluate imminent choices versus the gain from propagating newly encountered information to preceding locations. Our theory offers a simple explanation for numerous findings about place cells; unifies seemingly disparate proposed functions of replay including planning, learning, and consolidation; and posits a mechanism whose dysfunction may underlie pathologies like rumination and craving.}
}
@article{SchauletalCoRR-15,
title = {Prioritized Experience Replay},
author = {Tom Schaul and John Quan and Ioannis Antonoglou and David Silver},
journal = {CoRR},
volume = {arXiv:1511.05952},
year = {2015},
abstract = {Experience replay lets online reinforcement learning agents remember and reuse experiences from the past. In prior work, experience transitions were uniformly sampled from a replay memory. However, this approach simply replays transitions at the same frequency that they were originally experienced, regardless of their significance. In this paper we develop a framework for prioritizing experience, so as to replay important transitions more frequently, and therefore learn more efficiently. We use prioritized experience replay in Deep Q-Networks (DQN), a reinforcement learning algorithm that achieved human-level performance across many Atari games. DQN with prioritized experience replay achieves a new state-of-the-art, outperforming DQN with uniform replay on 41 out of 49 game},
}
@inproceedings{VinyalsetalNIPS-16,
author = {Oriol Vinyals and Charles Blundell and Timothy P. Lillicrap and Koray Kavukcuoglu and Daan Wierstra},
title = {Matching networks for one shot learning},
booktitle = {Advances in Neural Information Processing Systems},
publisher = {Curran Associates, Inc.},
year = {2017},
pages = {3630-3638},
abstract = {Learning from a few examples remains a key challenge in machine learning. Despite recent advances in important domains such as vision and language, the standard supervised deep learning paradigm does not offer a satisfactory solution for learning new concepts rapidly from little data. In this work, we employ ideas from metric learning based on deep neural features and from recent advances that augment neural networks with external memories. Our framework learns a network that maps a small labelled support set and an unlabelled example to its label, obviating the need for fine-tuning to adapt to new class types. We then define one-shot learning problems on vision (using Omniglot, ImageNet) and language tasks. Our algorithm improves one-shot accuracy on ImageNet from 87.6\% to 93.2\% and from 88.0\% to 93.8\% on Omniglot compared to competing approaches. We also demonstrate the usefulness of the same model on language modeling by introducing a one-shot task on the Penn Treebank.}
}
@article{vandenOordCoRR-17,
author = {A{\"{a}}ron van den Oord and Oriol Vinyals and Koray Kavukcuoglu},
title = {Neural Discrete Representation Learning},
journal = {CoRR},
volume = {arXiv:1711.00937},
year = {2017},
abstract = {Learning useful representations without supervision remains a key challenge in machine learning. In this paper, we propose a simple yet powerful generative model that learns such discrete representations. Our model, the Vector Quantised-Variational AutoEncoder (VQ-VAE), differs from VAEs in two key ways: the encoder network outputs discrete, rather than continuous, codes; and the prior is learnt rather than static. In order to learn a discrete latent representation, we incorporate ideas from vector quantisation (VQ). Using the VQ method allows the model to circumvent issues of "posterior collapse" -- where the latents are ignored when they are paired with a powerful autoregressive decoder -- typically observed in the VAE framework. Pairing these representations with an autoregressive prior, the model can generate high quality images, videos, and speech as well as doing high quality speaker conversion and unsupervised learning of phonemes, providing further evidence of the utility of the learnt representations.}
}
@misc{YadavVQ-VAE-19,
title = {Understanding Vector Quantized Variational Autoencoders},
author = {Sasshank Kwon},
howpublished = {\url{https://blog.usejournal.com/understanding-vector-quantized-variational-autoencoders-vq-vae-323d710a888a}},
year = {2019},
}
@misc{SharafPOINTER-NETWORKS-17,
title = {Inroduction to Pointer Networks - Medium, June 2, 2017},
author = {Amr Sharaf},
howpublished = {\url{https://medium.com/@sharaf/a-paper-a-day-11-pointer-networks-59f7af1a611c}},
year = {2017},
}
@misc{SinghPOINTER-NETWORKS-17,
title = {Understanding Pointer Networks - Medium, May 24, 2017},
author = {Abhishek Singh},
howpublished = {\url{https://towardsdatascience.com/understanding-pointer-networks-81fbbc1ddbc8}},
year = {2017},
}
@misc{NguyenBOOSTED-HINDSIGHT-REPLAY-19,
title = {Four Ways to Boost Experience Replay: {M}aking agents remember the important things},
author = {Austin Nguyen},
howpublished = {\url{https://towardsdatascience.com/4-ways-to-boost-experience-replay-999d9f17f7b6}},
year = {2019},
}
@misc{KhandelwalBEAM-SEARCH-18,
title = {An intuitive explanation of Beam Search - Towards Data Science, February 1, 2018},
author = {Renu Khandelwal},
howpublished = {\url{https://towardsdatascience.com/an-intuitive-explanation-of-beam-search-9b1d744e7a0f}},
year = {2018},
}
@inproceedings{JinetalICML-20,
title = {Multi-Objective Molecule Generation using Interpretable Substructures},
author = {Wengong Jin and Regina Barzilay and Tommi Jaakkola},
booktitle = {Proceedings of the 37th International Conference on Machine Learning},
volume = {arXiv:2002.03244},
year = {2020},
abstract = {Drug discovery aims to find novel compounds with specified chemical property profiles. In terms of generative modeling, the goal is to learn to sample molecules in the intersection of multiple property constraints. This task becomes increasingly challenging when there are many property constraints. We propose to offset this complexity by composing molecules from a vocabulary of substructures that we call molecular rationales. These rationales are identified from molecules as substructures that are likely responsible for each property of interest. We then learn to expand rationales into a full molecule using graph generative models. Our final generative model composes molecules as mixtures of multiple rationale completions, and this mixture is fine-tuned to preserve the properties of interest. We evaluate our model on various drug design tasks and demonstrate significant improvements over state-of-the-art baselines in terms of accuracy, diversity, and novelty of generated compounds.},
}
@inproceedings{FuWSC-2018,
author = {M. C. {Fu}},
booktitle = {2018 Winter Simulation Conference (WSC)},
editor = {M. Rabe, A. A. Juan, N. Mustafee, A. Skoogh, S. Jain, and B. Johansson},
title = {Monte Carlo Tree Search: A Tutorial},
year = {2018},
pages = {222-236},
abstract = {Monte Carlo tree search (MCTS) is a general approach to solving game problems, playing a central role in Google DeepMind's AlphaZero and its predecessor AlphaGo, which famously defeated the (human) world Go champion Lee Sedol in 2016 and world #1 Go player Ke Jie in 2017. Starting from scratch without using any domain-specific knowledge (other than the game rules), AlphaZero defeated not only its ancestors in Go but also the best computer programs in chess (Stockfish) and shogi (Elmo). In this tutorial, we provide an introduction to MCTS, including a review of its history and relationship to a more general simulation-based algorithm for Markov decision processes (MDPs) published in a 2005 Operations Research article; a demonstration of the basic mechanics of the algorithms via decision trees and the game of tic-tac-toe; and its use in AlphaGo and AlphaZero.}
}
@article{SilveretalNATURE-16,
author = {Silver, David and Huang, Aja and Maddison, Chris J. and Guez, Arthur and Sifre, Laurent and van den Driessche, George and Schrittwieser, Julian and Antonoglou, Ioannis and Panneershelvam, Veda and Lanctot, Marc and Dieleman, Sander and Grewe, Dominik and Nham, John and Kalchbrenner, Nal and Sutskever, Ilya and Lillicrap, Timothy and Leach, Madeleine and Kavukcuoglu, Koray and Graepel, Thore and Hassabis, Demis},
title = {Mastering the game of Go with deep neural networks and tree search},
journal = {Nature},
publisher = {Nature Publishing Group},
volume = {529},
issue = {7587},
year = {2016},
pages = {484-489},
abstract = {The game of Go has long been viewed as the most challenging of classic games for artificial intelligence owing to its enormous search space and the difficulty of evaluating board positions and moves. Here we introduce a new approach to computer Go that uses "value networks" to evaluate board positions and "policy networks" to select moves. These deep neural networks are trained by a novel combination of supervised learning from human expert games, and reinforcement learning from games of self-play. Without any lookahead search, the neural networks play Go at the level of state-of-the-art Monte Carlo tree search programs that simulate thousands of random games of self-play. We also introduce a new search algorithm that combines Monte Carlo simulation with value and policy networks. Using this search algorithm, our program AlphaGo achieved a 99.8\% winning rate against other Go programs, and defeated the human European Go champion by 5 games to 0. This is the first time that a computer program has defeated a human professional player in the full-sized game of Go, a feat previously thought to be at least a decade away.},
}
@article{WangetalCoRR-18b,
author = {Linnan Wang and Yiyang Zhao and Yuu Jinnai},
title = {{AlphaX: eXploring Neural Architectures with Deep Neural Networks and Monte Carlo Tree Search}},
journal = {CoRR},
volume = {arXiv:1805.07440},
year = {2018},
abstract = {Neural Architecture Search (NAS) has shown great success in automating the design of neural networks, but the prohibitive amount of computations behind current NAS methods requires further investigations in improving the sample efficiency and the network evaluation cost to get better results in a shorter time. In this paper, we present a novel scalable Monte Carlo Tree Search (MCTS) based NAS agent, named AlphaX, to tackle these two aspects. AlphaX improves the search efficiency by adaptively balancing the exploration and exploitation at the state level, and by a Meta-Deep Neural Network (DNN) to predict network accuracies for biasing the search toward a promising region. To amortize the network evaluation cost, AlphaX accelerates MCTS rollouts with a distributed design and reduces the number of epochs in evaluating a network by transfer learning, which is guided with the tree structure in MCTS. In 12 GPU days and 1000 samples, AlphaX found an architecture that reaches 97.84\% top-1 accuracy on CIFAR-10, and 75.5\% top-1 accuracy on ImageNet, exceeding SOTA NAS methods in both the accuracy and sampling efficiency. Particularly, we also evaluate AlphaX on NASBench-101, a large scale NAS dataset; AlphaX is 3x and 2.8x more sample efficient than Random Search and Regularized Evolution in finding the global optimum. Finally, we show the searched architecture improves a variety of vision applications from Neural Style Transfer, to Image Captioning and Object Detection.}
}
@inproceedings{GaoetalIJCAI-18,
title = {Three-Head Neural Network Architecture for Monte Carlo Tree Search},
author = {Chao Gao and Martin M{\"{u}}ller and Ryan Hayward},
booktitle = {Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, {IJCAI-18}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {3762-3768},
year = {2018},
abstract = {AlphaGo Zero pioneered the concept of two-head neural networks in Monte Carlo Tree Search (MCTS), where the policy output is used for prior action probability and the state-value estimate is used for leaf node evaluation. We propose a three-head neural net architecture with policy, state- and action-value outputs, which could lead to more efficient MCTS since neural leaf estimate can still be back-propagated in tree with delayed node expansion and evaluation. To effectively train the newly introduced action-value head on the same game dataset as for two-head nets, we exploit the optimal relations between parent and children nodes for data augmentation and regularization. In our experiments for the game of Hex, the action-value head learning achieves similar error as the state-value prediction of a two-head architecture. The resulting neural net models are then combined with the same Policy Value MCTS (PV-MCTS) implementation. We show that, due to more efficient use of neural net evaluations, PV-MCTS with three-head neural nets consistently performs better than the two-head ones, significantly outplaying the state-of-the-art player MoHex-CNN.}
}
@article{HusseinetalACM-17,
author = {Hussein, Ahmed and Gaber, Mohamed Medhat and Elyan, Eyad and Jayne, Chrisina},
title = {Imitation Learning: A Survey of Learning Methods},
journal = {ACM Computing Surveys},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {50},
number = {2},
year = {2017},
abstract = {Imitation learning techniques aim to mimic human behavior in a given task. An agent (a learning machine) is trained to perform a task from demonstrations by learning a mapping between observations and actions. The idea of teaching by imitation has been around for many years; however, the field is gaining attention recently due to advances in computing and sensing as well as rising demand for intelligent applications. The paradigm of learning by imitation is gaining popularity because it facilitates teaching complex tasks with minimal expert knowledge of the tasks. Generic imitation learning methods could potentially reduce the problem of teaching a task to that of providing demonstrations, without the need for explicit programming or designing reward functions specific to the task. Modern sensors are able to collect and transmit high volumes of data rapidly, and processors with high computational power allow fast processing that maps the sensory data to actions in a timely manner. This opens the door for many potential AI applications that require real-time perception and reaction such as humanoid robots, self-driving vehicles, human computer interaction, and computer games, to name a few. However, specialized algorithms are needed to effectively and robustly learn models as learning by imitation poses its own set of challenges. In this article, we survey imitation learning methods and present design options in different steps of the learning process. We introduce a background and motivation for the field as well as highlight challenges specific to the imitation problem. Methods for designing and evaluating imitation learning tasks are categorized and reviewed. Special attention is given to learning methods in robotics and games as these domains are the most popular in the literature and provide a wide array of problems and methodologies. We extensively discuss combining imitation learning approaches using different sources and methods, as well as incorporating other motion learning methods to enhance imitation. We also discuss the potential impact on industry, present major applications, and highlight current and future research directions.},
}
@article{VinyalsetalNATURE-19,
author = {Vinyals, Oriol and Babuschkin, Igor and Czarnecki, Wojciech M. and Mathieu, Michal and Dudzik, Andrew and Chung, Junyoung and Choi, David H. and Powell, Richard and Ewalds, Timo and Georgiev, Petko and Oh, Junhyuk and Horgan, Dan and Kroiss, Manuel and Danihelka, Ivo and Huang, Aja and Sifre, Laurent and Cai, Trevor and Agapiou, John P. and Jaderberg, Max and Vezhnevets, Alexander S. and Leblond, R{\'{e}}mi and Pohlen, Tobias and Dalibard, Valentin and Budden, David and Sulsky, Yury and Molloy, James and Paine, Tom L. and Gulcehre, Caglar and Wang, Ziyu and Pfaff, Tobias and Wu, Yuhuai and Ring, Roman and Yogatama, Dani and Wunsch, Dario and McKinney, Katrina and Smith, Oliver and Schaul, Tom and Lillicrap, Timothy and Kavukcuoglu, Koray and Hassabis, Demis and Apps, Chris and Silver, David},
title = {Grandmaster level in StarCraft II using multi-agent reinforcement learning},
journal = {Nature},
year = {2019},
volume = {575},
issue = {7782},
pages = {350-354},
abstract = {Many real-world applications require artificial agents to compete and coordinate with other agents in complex environments. As a stepping stone to this goal, the domain of StarCraft has emerged as an important challenge for artificial intelligence research, owing to its iconic and enduring status among the most difficult professional esports and its relevance to the real world in terms of its raw complexity and multi-agent challenges. Over the course of a decade and numerous competitions, the strongest agents have simplified important aspects of the game, utilized superhuman capabilities, or employed hand-crafted sub-systems4. Despite these advantages, no previous agent has come close to matching the overall skill of top StarCraft players. We chose to address the challenge of StarCraft using general-purpose learning methods that are in principle applicable to other complex domains: a multi-agent reinforcement learning algorithm that uses data from both human and agent games within a diverse league of continually adapting strategies and counter-strategies, each represented by deep neural networks5,6. We evaluated our agent, AlphaStar, in the full game of StarCraft II, through a series of online games against human players. AlphaStar was rated at Grandmaster level for all three StarCraft races and above 99.8\% of officially ranked human players.},
}
@article{PierrotetalCoRR-19,
author = {Thomas Pierrot and Guillaume Ligner and Scott E. Reed and Olivier Sigaud and Nicolas Perrin and Alexandre Laterre and David Kas and Karim Beguir and Nando de Freitas},
title = {Learning Compositional Neural Programs with Recursive Tree Search and Planning},
journal = {CoRR},
volume = {arXiv:1905.12941},
year = {2019},
abstract = {We propose a novel reinforcement learning algorithm, AlphaNPI, that incorporates the strengths of Neural Programmer-Interpreters (NPI) and AlphaZero. NPI contributes structural biases in the form of modularity, hierarchy and recursion, which are helpful to reduce sample complexity, improve generalization and increase interpretability. AlphaZero contributes powerful neural network guided search algorithms, which we augment with recursion. AlphaNPI only assumes a hierarchical program specification with sparse rewards: 1 when the program execution satisfies the specification, and 0 otherwise. Using this specification, AlphaNPI is able to train NPI models effectively with RL for the first time, completely eliminating the need for strong supervision in the form of execution traces. The experiments show that AlphaNPI can sort as well as previous strongly supervised NPI variants. The AlphaNPI agent is also trained on a Tower of Hanoi puzzle with two disks and is shown to generalize to puzzles with an arbitrary number of disk}
}
8 Here is Merel et al [83] on their implementation of coding space as it relates to the more general issue of inter-region communication between levels of control in designing optimal control systems:
The structure of inter-region communication. At present, we do not fully understand what coding schemes brain regions use to communicate, and we are similarly uncertain how to specify information flow in synthetic hierarchical motor control systems. The default scheme for communication between layers or modules of learning systems is for the output of one layer to serve as an input to another layer. However, there are still various open questions—for example, should communication follow prescribed semantics? Learning systems will not necessarily result in interpretable inter-layer communication, unless structure emerges through the learning process or is encouraged explicitly. A second question is how, mechanistically, the outputs of one system should modulate another—whether activations from one layer should serve as simple inputs or if they should nonlinearly modulate their target, such as via multiplicative gating (e.g., Vaswani et al [133]). Yet another question concerns the level of resolution of the signals sent between regions—what is the balance between communicating abstract goals that only partially specify behavior versus communicating rich instructions that precisely tell the lower-level system what to do? Too intense micromanagement makes the function of a lowlevel system redundant, yet in certain cases it may be useful for a high-level system to entirely override low-level behavior. To ground these issues in neuroscience, we can consider a specific debate in the field. Friston [44] identifies a key difference between classes of proposed hierarchies as having to do with the semantics of signals sent from higher-level controllers to lowerlevel controllers, noting that "In active inference, descending signals are in themselves predictions of sensory consequences." As an alternative, Todorov et al [129, 130] advocated for the interface between the higher-level and lower-level controllers to be engineered and reflect insight into an appropriate set of variables well suited to the range of behavior. Although it is not yet clear which of these proposals, if either, corresponds to biology, the general point is clear—hierarchical systems must employ a language or code at the interface between layers or regions. Here, we do not propose to resolve this issue, but instead suggest that this area presents an opportunity for neuroscience and AI efforts to collaborate in proposing communication schemes and evaluating which are effective.
9 Searching for an action that results in a state s closer to the goal s′ is called means-ends analysis, and is a problem solving technique used commonly in artificial intelligence for limiting search. It is employed as a heuristic in goal-based problem solving, a framework in which the solution to a problem can be described by finding a sequence of actions that lead to a desirable goal. (SOURCE)
10 This reminded me of the difference between classical Newtonian mechanics and Hamiltonian mechanics, and its importance in quantum theory where it is important to account for particles moving at relativistic speeds. I enjoyed Ian Stewart's characterization of Hamiltonian mechanics in discussing Zeno's paradox and other physics-related conundrums in [124], "In Hamiltonian mechanics, the state of a body is given by two quantities, its position and momentum, instead of just position. Momentum is a hidden variable observable only through its effect on subsequent positions, whereas position is something that we can observe directly. Momentum encodes the next change of position, and it encodes it now. Its value now is not observable now, but it will be observable. You just have to wait and find out what it was. Momentum is a hidden variable that encodes transitions from one position to another."
11 To serve as an aid in understanding how working memory might provide clues to uniquely determine what amounts to the instruction counter of an executing program, the following listing highlights changes in working memory as follows: transfer read-register content: SRC, transfer write-register content SNK, comparison result register or the result of clearing the registers CMP. The register machine compiler can be easily configured to produce traces that include such annotations for training purposes:
| BUFFIN | : | 1 | Q | 1 | A | 0 | Z | 2 | B | Y | 0 |
| BUFFOUT | : | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| PATONE | : | 1 | A | ? | ? | ? | ? | ? | ? | ? | ? |
| PATTWO | : | D | E | ? | ? | ? | ? | ? | ? | ? | ? |
| INPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| OUTPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| STAGED | : | 1 | 1 | A | 0 | W | _ | _ | _ | _ | _ |
| COMPARE | : | 1 | 0 | 0 | _ | _ | _ | _ | _ | _ | _ |
>> TRANSFER (BUFFIN 1) TO (COMPARE 1)
| BUFFIN | : | 1 | Q | 1 | A | 0 | Z | 2 | B | Y | 0 |
| BUFFOUT | : | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| PATONE | : | 1 | A | ? | ? | ? | ? | ? | ? | ? | ? |
| PATTWO | : | D | E | ? | ? | ? | ? | ? | ? | ? | ? |
| INPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| OUTPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| STAGED | : | 1 | 1 | A | 0 | W | _ | _ | _ | _ | _ |
| COMPARE | : | 1 | 1 | 0 | _ | _ | _ | _ | _ | _ | _ |
>> TRANSFER (PATONE 1) TO (COMPARE 2)
| BUFFIN | : | 1 | Q | 1 | A | 0 | Z | 2 | B | Y | 0 |
| BUFFOUT | : | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| PATONE | : | 1 | A | ? | ? | ? | ? | ? | ? | ? | ? |
| PATTWO | : | D | E | ? | ? | ? | ? | ? | ? | ? | ? |
| INPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| OUTPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| STAGED | : | 1 | 1 | A | 0 | W | _ | _ | _ | _ | _ |
| COMPARE | : | 1 | 1 | 1 | 0 | _ | _ | _ | _ | _ | _ |
>> COMPARING (COMPARE 1) TO (COMPARE 2) = 1
| BUFFIN | : | 1 | Q | 1 | A | 0 | Z | 2 | B | Y | 0 |
| BUFFOUT | : | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| PATONE | : | 1 | A | ? | ? | ? | ? | ? | ? | ? | ? |
| PATTWO | : | D | E | ? | ? | ? | ? | ? | ? | ? | ? |
| INPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| OUTPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| STAGED | : | 1 | 1 | A | 0 | W | _ | _ | _ | _ | _ |
| COMPARE | : | ? | ? | ? | _ | _ | _ | _ | _ | _ | _ |
>> CLEARING (COMPARE 1) (COMPARE 2) (COMPARE 3)
| BUFFIN | : | 1 | Q | 1 | A | 0 | Z | 2 | B | Y | 0 |
| BUFFOUT | : | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| PATONE | : | 1 | A | ? | ? | ? | ? | ? | ? | ? | ? |
| PATTWO | : | D | E | ? | ? | ? | ? | ? | ? | ? | ? |
| INPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| OUTPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| COMPARE | : | Q | ? | ? | _ | _ | _ | _ | _ | _ | _ |
>> TRANSFER (BUFFIN 2) TO (COMPARE 1)
| BUFFIN | : | 1 | Q | 1 | A | 0 | Z | 2 | B | Y | 0 |
| BUFFOUT | : | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| PATONE | : | 1 | A | ? | ? | ? | ? | ? | ? | ? | ? |
| PATTWO | : | D | E | ? | ? | ? | ? | ? | ? | ? | ? |
| INPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| OUTPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| COMPARE | : | Q | A | ? | _ | _ | _ | _ | _ | _ | _ |
>> TRANSFER (PATONE 2) TO (COMPARE 2)
| BUFFIN | : | 1 | Q | 1 | A | 0 | Z | 2 | B | Y | 0 |
| BUFFOUT | : | ? | ? | ? | ? | ? | ? | ? | ? | ? | ? |
| PATONE | : | 1 | A | ? | ? | ? | ? | ? | ? | ? | ? |
| PATTWO | : | D | E | ? | ? | ? | ? | ? | ? | ? | ? |
| INPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| OUTPUT | : | ? | _ | _ | _ | _ | _ | _ | _ | _ | _ |
| COMPARE | : | Q | A | 0 | _ | _ | _ | _ | _ | _ | _ |
>> COMPARING (COMPARE 1) TO (COMPARE 2) = 0
12 Here is an example run of the register-machine compiler on a simple AWK substitution task showing the first three pages and the last. Each column shows one page and each page shows six snapshots / state vectors listing the contents of all working-memory registers followed by the register-machine microcode instruction that immediately preceded the snapshot. The listing of the full run is provided here:
%
BUFFIN : (1 Q 1 A 0 Z 2 B Y 0) BUFFIN : (1 Q 1 A 0 Z 2 B Y 0) BUFFIN : (Q 1 A 0 Z 2 B Y 0 1) ... BUFFIN : (0 W ? ? ? ? ? ? ? ?)
BUFFOUT : (? ? ? ? ? ? ? ? ? ?) BUFFOUT : (? ? ? ? ? ? ? ? ? ?) BUFFOUT : (? ? ? ? ? ? ? ? ? 1) ... BUFFOUT : (E 0 Z 2 B Y 0 1 D E)
PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) ... PATONE : (1 A ? ? ? ? ? ? ? ?)
PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) ... PATTWO : (D E ? ? ? ? ? ? ? ?)
INPUT : (?) INPUT : (?) INPUT : (?) ... INPUT : (?)
OUTPUT : (?) OUTPUT : (?) OUTPUT : (1) ... OUTPUT : (E)
STAGED : (1 1 A 0 W) STAGED : (1 1 A 0 W) STAGED : (1 A 0 W) ... STAGED : ()
COMPARE : (? ? ?) COMPARE : (Q A ?) COMPARE : (Q 1 0) ... COMPARE : (? ? ?)
INITIALIZING REGISTER MACHINE TRANSFER (PATONE 2) TO (COMPARE 2) COMPARING (COMPARE 1) TO (COMPARE 2) = 0 ... TRANSFER (BUFFIN 1) TO (OUTPUT 1)
...
BUFFIN : (1 Q 1 A 0 Z 2 B Y 0) BUFFIN : (1 Q 1 A 0 Z 2 B Y 0) BUFFIN : (Q 1 A 0 Z 2 B Y 0 1) ... BUFFIN : (W ? ? ? ? ? ? ? ? ?)
BUFFOUT : (? ? ? ? ? ? ? ? ? ?) BUFFOUT : (? ? ? ? ? ? ? ? ? ?) BUFFOUT : (? ? ? ? ? ? ? ? ? 1) ... BUFFOUT : (0 Z 2 B Y 0 1 D E 0)
PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) ... PATONE : (1 A ? ? ? ? ? ? ? ?)
PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) ... PATTWO : (D E ? ? ? ? ? ? ? ?)
INPUT : (?) INPUT : (?) INPUT : (?) ... INPUT : (?)
OUTPUT : (?) OUTPUT : (?) OUTPUT : (1) ... OUTPUT : (0)
STAGED : (1 1 A 0 W) STAGED : (1 1 A 0 W) STAGED : (1 A 0 W) ... STAGED : ()
COMPARE : (1 ? ?) COMPARE : (Q A 0) COMPARE : (? ? ?) [CONTROVERSIAL CLEAR STEP] ... COMPARE : (W ? ?)
TRANSFER (BUFFIN 1) TO (COMPARE 1) COMPARING (COMPARE 1) TO (COMPARE 2) = 0 CLEARING (COMPARE 1) (COMPARE 2) (COMPARE 3) ... TRANSFER (BUFFIN 1) TO (COMPARE 1)
...
BUFFIN : (1 Q 1 A 0 Z 2 B Y 0) BUFFIN : (1 Q 1 A 0 Z 2 B Y 0) BUFFIN : (Q 1 A 0 Z 2 B Y 0 1) ... BUFFIN : (W ? ? ? ? ? ? ? ? ?)
BUFFOUT : (? ? ? ? ? ? ? ? ? ?) BUFFOUT : (? ? ? ? ? ? ? ? ? ?) BUFFOUT : (? ? ? ? ? ? ? ? ? 1) ... BUFFOUT : (0 Z 2 B Y 0 1 D E 0)
PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) ... PATONE : (1 A ? ? ? ? ? ? ? ?)
PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) ... PATTWO : (D E ? ? ? ? ? ? ? ?)
INPUT : (?) INPUT : (?) INPUT : (?) ... INPUT : (?)
OUTPUT : (?) OUTPUT : (?) OUTPUT : (1) ... OUTPUT : (0)
STAGED : (1 1 A 0 W) STAGED : (1 1 A 0 W) STAGED : (1 A 0 W) ... STAGED : ()
COMPARE : (1 1 ?) COMPARE : (? ? ?) [CONTROVERSIAL CLEAR STEP] COMPARE : (? ? ?) ... COMPARE : (W 1 ?)
TRANSFER (PATONE 1) TO (COMPARE 2) CLEARING (COMPARE 1) (COMPARE 2) (COMPARE 3) TRANSFER (BUFFIN 1) TO (OUTPUT 1) ... TRANSFER (PATONE 1) TO (COMPARE 2)
...
BUFFIN : (1 Q 1 A 0 Z 2 B Y 0) BUFFIN : (1 Q 1 A 0 Z 2 B Y 0) BUFFIN : (1 A 0 Z 2 B Y 0 1 1) ... BUFFIN : (W ? ? ? ? ? ? ? ? ?)
BUFFOUT : (? ? ? ? ? ? ? ? ? ?) BUFFOUT : (? ? ? ? ? ? ? ? ? ?) BUFFOUT : (? ? ? ? ? ? ? ? 1 Q) ... BUFFOUT : (0 Z 2 B Y 0 1 D E 0)
PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) ... PATONE : (1 A ? ? ? ? ? ? ? ?)
PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) ... PATTWO : (D E ? ? ? ? ? ? ? ?)
INPUT : (?) INPUT : (?) INPUT : (?) ... INPUT : (?)
OUTPUT : (?) OUTPUT : (?) OUTPUT : (Q) ... OUTPUT : (0)
STAGED : (1 1 A 0 W) STAGED : (1 1 A 0 W) STAGED : (A 0 W) ... STAGED : ()
COMPARE : (1 1 1) COMPARE : (? ? ?) COMPARE : (1 ? ?) ... COMPARE : (W 1 0)
COMPARING (COMPARE 1) TO (COMPARE 2) = 1 TRANSFER (BUFFIN 1) TO (OUTPUT 1) TRANSFER (BUFFIN 1) TO (COMPARE 1) ... COMPARING (COMPARE 1) TO (COMPARE 2) = 0
...
BUFFIN : (1 Q 1 A 0 Z 2 B Y 0) BUFFIN : (Q 1 A 0 Z 2 B Y 0 1) BUFFIN : (1 A 0 Z 2 B Y 0 1 1) ... BUFFIN : (W ? ? ? ? ? ? ? ? ?)
BUFFOUT : (? ? ? ? ? ? ? ? ? ?) BUFFOUT : (? ? ? ? ? ? ? ? ? 1) BUFFOUT : (? ? ? ? ? ? ? ? 1 Q) ... BUFFOUT : (0 Z 2 B Y 0 1 D E 0)
PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) ... PATONE : (1 A ? ? ? ? ? ? ? ?)
PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) ... PATTWO : (D E ? ? ? ? ? ? ? ?)
INPUT : (?) INPUT : (?) INPUT : (?) ... INPUT : (?)
OUTPUT : (?) OUTPUT : (1) OUTPUT : (Q) ... OUTPUT : (0)
STAGED : (1 1 A 0 W) STAGED : (1 A 0 W) STAGED : (A 0 W) ... STAGED : ()
COMPARE : (? ? ?) [CONTROVERSIAL CLEAR STEP] COMPARE : (Q ? ?) COMPARE : (1 1 ?) ... COMPARE : (? ? ?)
CLEARING (COMPARE 1) (COMPARE 2) (COMPARE 3) TRANSFER (BUFFIN 1) TO (COMPARE 1) TRANSFER (PATONE 1) TO (COMPARE 2) ... CLEARING (COMPARE 1) (COMPARE 2) (COMPARE 3)
...
BUFFIN : (1 Q 1 A 0 Z 2 B Y 0) BUFFIN : (Q 1 A 0 Z 2 B Y 0 1) BUFFIN : (1 A 0 Z 2 B Y 0 1 1) ... BUFFIN : (W ? ? ? ? ? ? ? ? ?)
BUFFOUT : (? ? ? ? ? ? ? ? ? ?) BUFFOUT : (? ? ? ? ? ? ? ? ? 1) BUFFOUT : (? ? ? ? ? ? ? ? 1 Q) ... BUFFOUT : (0 Z 2 B Y 0 1 D E 0)
PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) PATONE : (1 A ? ? ? ? ? ? ? ?) ... PATONE : (1 A ? ? ? ? ? ? ? ?)
PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) PATTWO : (D E ? ? ? ? ? ? ? ?) ... PATTWO : (D E ? ? ? ? ? ? ? ?)
INPUT : (?) INPUT : (?) INPUT : (?) ... INPUT : (?)
OUTPUT : (?) OUTPUT : (1) OUTPUT : (Q) ... OUTPUT : (0)
STAGED : (1 1 A 0 W) STAGED : (1 A 0 W) STAGED : (A 0 W) ... STAGED : ()
COMPARE : (Q ? ?) COMPARE : (Q 1 ?) COMPARE : (1 1 1) ... COMPARE : (? ? ?)
TRANSFER (BUFFIN 2) TO (COMPARE 1) TRANSFER (PATONE 1) TO (COMPARE 2) COMPARING (COMPARE 1) TO (COMPARE 2) = 1 ... TRANSFER (BUFFIN 1) TO (OUTPUT 1)
Page 1 Page 2 Page 3 ... PAGE 7
OUTPUT = PATTERNS ((1 A) (D E))
SEQUENCE (1 Q 1 A 0 Z 2 B Y 0 1 1 A 0 W)
OUTPUT (1 Q D E 0 Z 2 B Y 0 1 D E 0 W)
13 Vector quantization (VQ) involves modeling probability density functions by the distribution of prototype vectors. It works by dividing a large set of points (vectors) into groups having approximately the same number of points closest to them. Each group is represented by its centroid point, as in k-means and some other clustering algorithms. Since data points are represented by the index of their closest centroid, commonly occurring data have low error, and rare data high error. VQ is suitable used for lossy data compression and density estimation. Vector quantization is competitive learning method closely related to self-organizing maps and sparse coding models used in deep learning algorithms such as autoencoder. (SOURCE)
14 The autoregressive model specifies that the output variable depends linearly on its own previous values and on a stochastic term (an imperfectly predictable term); thus the model is in the form of a stochastic difference equation (or recurrence relation which should not be confused with differential equation). (SOURCE)
15 Here are the titles and abstracts of the papers that I read in preparing to write this entry. The last paper listed below is an odd duck. The abstract promises a lot, but it's not clear to me whether the authors deliver on those promises. If one of you finds the paper merits a closer look, please tell me:
@article{DayanNC-93b,
title = {Improving generalization for temporal difference learning: The successor representation},
author = {Dayan, Peter},
journal = {Neural Computation},
volume = {5},
issue = {4},
pages = {613-624},
year = {1993},
abstract = {Estimation of returns over time, the focus of temporal difference (TD) algorithms, imposes particular constraints on good function approximators or representations. Appropriate generalisation between states is determined by how similar their successors are, and representations should follow suit. This paper shows how TD machinery can be used to learn such representations, and illustrates, using a navigation task, the appropriately distributed nature of the result.}
}
@article{StachenfeldetalNATURE-NEUROSCIENCE-17,
author = {Stachenfeld, Kimberly L. and Botvinick, Matthew M. and Gershman, Samuel J.},
title = {The hippocampus as a predictive map},
journal = {Nature Neuroscience},
volume = {20},
number = {1643},
year = {2017},
pages = {1643–1653},
publisher = {Nature Publishing Group},
abstract = {A cognitive map has long been the dominant metaphor for hippocampal function, embracing the idea that place cells encode a geometric representation of space. However, evidence for predictive coding, reward sensitivity, and policy dependence in place cells suggests that the representation is not purely spatial. We approach this puzzle from a reinforcement learning perspective: what kind of spatial representation is most useful for maximizing future reward? We show that the answer takes the form of a predictive representation. This representation captures many aspects of place cell responses that fall outside the traditional view of a cognitive map. Furthermore, we argue that entorhinal grid cells encode a low-dimensional basis set for the predictive representation, useful for suppressing noise in predictions and extracting multiscale structure for hierarchical planning.},
}
@article{HowardetalPR-05,
author = {Howard, Marc W. and Fotedar, Mrigankka S. and Datey, Aditya V. and Hasselmo, Michael E.},
title = {The temporal context model in spatial navigation and relational learning: toward a common explanation of medial temporal lobe function across domains},
journal = {Psychological review},
year = {2005},
volume = {112},
issue = {1},
pages = {75-116},
abstract = {The medial temporal lobe (MTL) has been studied extensively at all levels of analysis, yet its function remains unclear. Theory regarding the cognitive function of the MTL has centered along 3 themes. Different authors have emphasized the role of the MTL in episodic recall, spatial navigation, or relational memory. Starting with the temporal context model (M. W. Howard \& M. J. Kahana, 2002a), a distributed memory model that has been applied to benchmark data from episodic recall tasks, the authors propose that the entorhinal cortex supports a gradually changing representation of temporal context and the hippocampus proper enables retrieval of these contextual states. Simulation studies show this hypothesis explains the firing of place cells in the entorhinal cortex and the behavioral effects of hippocampal lesion in relational memory tasks. These results constitute a first step toward a unified computational theory of MTL function that integrates neurophysiological, neuropsychological, and cognitive findings.},
}
@article{HowardandKahanaJoMP-02,
author = {Marc W. Howard and Michael J. Kahana},
title = {A Distributed Representation of Temporal Context},
journal = {Journal of Mathematical Psychology},
volume = {46},
number = {3},
pages = {269-299},
year = {2002},
abstract = {The principles of recency and contiguity are two cornerstones of the theoretical and empirical analysis of human memory. Recency has been alternatively explained by mechanisms of decay, displacement, and retroactive interference. Another account of recency is based on the idea of variable context (Estes, 1955; Mensink \& Raaijmakers, 1989). Such notions are typically cast in terms of a randomly fluctuating population of elements reflective of subtle changes in the environment or in the subjects' mental state. This random context view has recently been incorporated into distributed and neural network memory models (Murdock, 1997; Murdock, Smith, \& Bai, 2001). Here we propose an alternative model. Rather than being driven by random fluctuations, this formulation, the temporal context model (TCM), uses retrieval of prior contextual states to drive contextual drift. In TCM, retrieved context is an inherently asymmetric retrieval cue. This allows the model to provide a principled explanation of the widespread advantage for forward recalls in free and serial recall. Modeling data from single-trial free recall, we demonstrate that TCM can simultaneously explain recency and contiguity effects across time scales.}
}
@article{DonnarummaetalAB-16,
author = {Francesco Donnarumma and Roberto Prevete and Andrea de Giorgio and Guglielmo Montone and Giovanni Pezzulo},
title = {Learning programs is better than learning dynamics: A programmable neural network hierarchical architecture in a multi-task scenario},
journal = {Adaptive Behavior},
volume = {24},
number = {1},
pages = {27-51},
year = {2016},
abstract = {Distributed and hierarchical models of control are nowadays popular in computational modeling and robotics. In the artificial neural network literature, complex behaviors can be produced by composing elementary building blocks or motor primitives, possibly organized in a layered structure. However, it is still unknown how the brain learns and encodes multiple motor primitives, and how it rapidly reassembles, sequences and switches them by exerting cognitive control. In this paper we advance a novel proposal, a hierarchical programmable neural network architecture, based on the notion of programmability and an interpreter-programmer computational scheme. In this approach, complex (and novel) behaviors can be acquired by embedding multiple modules (motor primitives) in a single, multi-purpose neural network. This is supported by recent theories of brain functioning in which skilled behaviors can be generated by combining functional different primitives embedded in "reusable" areas of "recycled" neurons. Such neuronal substrate supports flexible cognitive control, too. Modules are seen as interpreters of behaviors having controlling input parameters, or programs that encode structures of networks to be interpreted. Flexible cognitive control can be exerted by a programmer module feeding the interpreters with appropriate input parameters, without modifying connectivity. Our results in a multiple T-maze robotic scenario show how this computational framework provides a robust, scalable and flexible scheme that can be iterated at different hierarchical layers permitting to learn, encode and control multiple qualitatively different behaviors.}
}
16 Here are some notes from our regularly scheduled Sunday SAIRG meeting on October 25, 2020. The first part is a quick summary of the issues discussed in the meeting for Gene who couldn't attend. The rest consists of Yash's revised perspective on his earlier executive homunculus missive with a couple of my observations interspersed.
Summary of Content Covered
Discussion about the responsibility of consecutive levels in the hierarchy, including the issue of how subroutines are represented and how error correction is handled either by the subordinate level in debugging subroutines prior to generating the coding space for the superordinate level, or noticing when subroutines (generated by the subordinate level) fail in contexts where they might reasonably be expected to succeed.
Understanding the role of the VQ-VAE model in error correction and the representation of the contexts for both primitive actions and subroutines. Characterizing the separation of responsibility between the VQ-VAE state-vector prediction subsystem and the softmax layers in the transformer stack. The VQ-VAE is primarily responsible for predicting the next state for purposes of error prediction.
The softmax layers in each level of the transformer stack are responsible for emphasizing level-specific relationships between – and dependencies on – state variables corresponding to the contents of working memory, e.g., by highlighting the source and sink registers involved in the most recent register transfer.
This information is implicit in the most recent vectors in the state-vector time series with the number of vectors depending on underlying dynamics assuming a partially observable stochastic process. These two sources are combined in each level in the executive hierarchy to provide the context for action selection in the respective transformer levels.
We talked briefly about the interactions between the basal ganglia and the cerebellum in service to coordination and error correction. At each step, the resulting state vector is compared with the predicted state vector and steps are taken to correct for any discrepancies between the two which could involve taking compensatory actions or policy changes.
We discussed the possibility of meetings with Randy O'Reilly and Rishabh Singh to discuss, respectively, error correction at multiple levels of abstraction within the motor cortex and ideas from the neural-network code generation community on analyzing program traces to identify and correct for coding errors.
There was brief discussion about modifications to the register machine compiler to facilitate subroutine segmentation and implementation of the curriculum learning system. I included my comments in response to Yash's summary of his perspective on the current version of the Executive Homunculus that I requested in our meeting last Sunday:
Executive Homunculus Redux
YASH: After several months of discussions, we have arrived at many realizations of the executive homunculus project. This document is a description of my current ideas on the project. For the SIR like tasks we are considering, the input is a sequence of characters communicated through a few channels. The input from these channels is copied into the global workspace state that is used as a scratch space for the executive homunculus to execute on. On every tick of the internal model clock, the entire global state is compressed and represented as a discrete vector using a VQ-VAE. This representation vector as well as a copy of the global workspace state are concatenated and passed as input to the executive homunculus. The executive homunculus has a recurrent transformer architecture that works by recurrently transforming the input using self-attention. Once it has completed the processing of the data, it then returns a series of probability distributions over the global workspace state. These distributions are provided as context for the auxiliary modules to execute their respective operations. One example of such an auxiliary module would be the move operator that may use these multiple distributions to identify where the source and target registers for the move operation are. These auxiliary modules then execute their actions and the global workspace state is updated. On the update, either an output character is generated which is then sent to the I/O stream or more computation needs to be performed and the executive cycle repeats.
TLD: The compiler generates sequences of the working memory contents. The contents are alphanumeric characters plus codons / tokens included in the input and used for identifying and delimiting patterns and SIRT input sequences. As an exercise and preliminary complement to building the other components of the architecture, we could replace the content characters and codons with one-hot vectors and use them to train the VQ-VAE model to see if it can predict the next state vector and transfer input and output from the previous vector or, considering the possibility of non Markovian process – partially-observable of Markov of order greater than one – the previous n vectors. I suggest this as it might enable Raphael and Chaofei to take on the job of implementing the VQ-VAE model and testing it on compiler-generated sequences while you are working on the transformer stack. [There's an expanded discussion of this topic in the main text in which this footnote appears]
YASH: In order to make sure that the model is able to generalize, it is necessary that the model be trained using a curriculum or a game. Unlike other models such as the DNC or NTM, this curriculum exists at the global workspace state level. We use a compiler and code generator that creates an optimal program to solve the current stage of the curriculum. This optimal program is then compared to the actual execution of the executive homunculus. For the earliest stages of the curriculum, where the model is only required to perform simple actions like moving or copying registers, the compiler can be used as a direct supervision signal to train the executive model. As the stages progress, the optimal programs can be used to verify the outputs from the executive model and provide a training signal that is more diffuse. In this way, the executive homunculus can be gradually trained to become more general. Initially, it is trained to perform simple actions whose rewards are dense. As it gains fluency with simple actions, the tasks become more complicated, and the reward signals become more sparse. The goal of the later stages is to train the executive model to compose the low-level operations it learned in the earlier stages to execute more involved tasks. At all stages of the curriculum, the compiler and code generator can be used to provide a training signal for the model. Note we directly train on the global workspace state here because the sparsity of the I/O reward signal would necessitate far too many trials before the model learns to perform any meaningful action. Even once it has learned to execute a task, it is likely that the final execution would be based on specialized operations that are not modular enough to generalize the execution. Instead of learning a general set of skills that are applicable to a variety of cerebral tasks, the model would have learned only to overfit to the current task. By using the curriculum and compiler as supervisors, we can ensure that the model builds up the tools needed to execute the tasks in a hierarchy.
TLD: To support curriculum training the macros could be instrumented so that the compiler can generate training data for any task that can be characterized as a specific code fragment. In previous posts, I suggested that branch points might serve to identify such fragments and the subroutines they could be used to train. In the Lisp code for solving a given task these are generally signaled as conditional statements, introduced by IF, COND and CASE but also iterative constructs FOR, WHILE, MAP and some recursive functions. This strategy would work at multiple levels in the hierarchy. Determining if two sequences (each one corresponding to a register block) match results in a branch point and consists of multiple attempts to determine if two characters match (each one corresponding to the contents a single register) each of which results in a branch – either the two characters match, they don't match, or exactly one of the characters is an end-of-sequence condon.
TLD: I haven't yet commented on rest of Yash's Executive Homunculus email this morning, but the remaining paragraphs of that message provide a good summary of what he had to say about what sort of competing models we should implement and test as due diligence in comparing our approach to the current state of the art:
YASH: As an explicit architecture to train such a hierarchy we also propose a model where the representation vector is used as a coding space for different levels of executive models to communicate. Once the easier tasks of the curriculum are shattered, the later tasks would require that a higher level executive solve more abstract problems and communicate the solutions down to lower levels. In order to do this, the higher-level executive would transform the representation vector from the VQ-VAE, which encodes the current state and the trace of the execution, so that a cue for the next series of low-level actions is encoded within it. The higher levels of the hierarchy learn to use the code space to communicate their higher-level goals to the low-level models. When training on a new task, the lower levels of the hierarchy may be fixed and only the higher levels are trained to transform the code space for the specific problem at hand. In this way, the information learned from the earlier stages of the curriculum can be fixed and exploited for the later stages without needing to retrain the entire model from scratch every-time.
YASH: This is a rather involved model in its current form. In order to build up to this model, we have a strategy that relies on testing out different hypotheses. Initially, we would like to see how well a model without any global workspace other than its hidden state can perform on the more complex SIR tasks. Ideally, we would find that even if such models are able to solve these SIR tasks, they would take an incredible number of examples and compute time to train. Furthermore, the tasks specific skills such a model would use may not be generalizable as the entire model would have to be retrained for every task.
YASH: Secondly, we would want to test how an extremely simplified model with a global workspace would perform without any supervision. An example of such a model is a DNC or an NTM. These models have some form of a global workspace state, but they do not include more sophisticated machinery beyond that. Essentially they are RNN modules trained to directly perform operations on registers of the global workspace using attention. We hypothesize that while such models may learn how to solve advanced cognitive tasks as delineated by the experiments of their respective papers, such models would struggle to execute complex actions that involved the integration of multiple memory registers because of their parochial view on the global state through the attention vectors. Furthermore, these models would struggle to generalize as they may find task-specific solutions that are non-modular. Training these models to perform specific actions on their global state space is not trivial because of the rather complex representations in each register. So training these models using a curriculum devolves into training these models on simple I/O tasks and then hoping that these models will learn to generalize from these tasks.
YASH: The next step in our experiment pipeline would include a model that can operate on an explicit global workspace state. However, such a model would not incorporate any advanced hierarchy, nor would it include any auxiliary modules. Such a model would simply take the global state as input and output a subsequent global state. In this way, the onus for representation, generalization, and execution is placed entirely on the recurrent transformer. It is plausible that such a transformer would accurately learn all the necessary tools needed to shatter the tasks. However, due to the lack of any division of labor, it is possible that such a model may confuse the different subtasks and fall prey to many of the same issues faced by the DNC or NTM. On the other hand, such a model could be trained using the curriculum and compiler and so it is possible that such a model would learn to generalize. However, the degree of generalization is not as clear without further experimentation.
YASH: Penultimately we could introduce the auxiliary modules that accept the context vectors from the executive model and execute the appropriate actions based on the context. By separating out these modules, the recurrent transformer is able to reserve more of its computational budget for deciding what action to take instead of how to take the action. Furthermore, such a model is much easier to debug as the separation of labor allows us to identify where the problem in any particular program execution lies.
YASH: Finally, we can introduce the hierarchy to the model and allow the model to fix the lower levels while contemplating more abstract decisions. Such a model would encompass all of the pieces we described in the initial sections. Note that it is likely that such a model will not be our final result. However, by contemplating the strengths and weaknesses of all the prior approaches we are better prepared to identify and address any potential issues we may find during our experiments. It is likely that there are many more issues we will have to deal with that we may not have considered here. However, this is a good starting point to make sure we evaluate any critical flaws in our design before we actually find further issues with the experiments. In this way, we maintain a distance from the current task and separate as many fundamental problems we may find from other potential minor bugs.
17 Here is a redacted version of an email message that I sent to a friend who asked what I thought about McFadden's EMI field theory of consciousness [81]:
Thanks for the pointer to McFadden's paper on consciousness. I am in agreement with much of what the author has to say, but don't find his invocation of EMI particularly compelling, and I think it likely there is a simpler explanation in terms of diffuse neuromodulatory signaling pathways and the synchronized action potentials of distributed neural ensembles. See this recent entry in my research notes pertaining to the work of Dehaene, Baars, Hebb and others on some of the practical issues that inform the design of the neural network architectures we are developing. The paper by Modha and Singh [90] is particularly interesting.Here's what I tell my students most of the time. Consciousness is just a form of attention. In the brain, attention, prediction and memory are all intertwined and distributed throughout not only the cortex but many subcortical regions as well. The fact that we can discourse about our conscious experience of the world around us, including the quality of how it feels to be conscious of something, is simply an extension of our use of language to signal one another and inform others of our emotional and attentional state so as to facilitate coordinated activity within our various collectives, including family, tribe, etc. While language plays an important role in the human individual and social experience of consciousness, consciousness is ubiquitous within mammals and likely other species including cephalopods, whales and dolphins.
Fundamentally, consciousness is a process and, as such, it has a signature in the form of patterns of activity within the brain. It may be that this signature is indistinguishable against the background of neuronal chatter, but more likely we will find some way to characterize the activity associated with consciousness so as to determine whether or not an animal is conscious and perhaps the quality of that consciousness as a measure of cognitive ability or health. The danger is we use this characterization to guide medical or moral procedure in the same way that we have employed our understanding of intelligence to guide our appreciation and treatment of humans and other animals.
As for the neural correlates of consciousness, my view is that conscious activity can drive neural processing throughout the brain and that once we are able to separate out what is special about conscious thought we will find out that the distinctive patterns of consciousness are sparse and initiated by signals driven by subcortical nuclei in the thalamus and hypothalamus. As for the question of whether or not machines can be engineered to be conscious, I believe we will discover that consciousness is a useful cognitive capacity essential in the design of many machines, and that inevitably we will have to face the moral issues associated with their fair treatment.
18 Here is the complete output generated by the first version of register-machine compiler described in the October 25th entry in this appendix to the 2020 class discussion list:
Welcome to Racket v7.7. > (require "Register_Machine_Macros.rkt") PATONE : 1 A X <<< The first 4 lines describe this problem and first 2 list patterns. PATTWO : 2 B Y BUFFIN : 1 Q 1 A 0 Z 2 B Y 0 <<< The input buffer (BUFFIN) was preloaded to run this demonstration. BUFFOUT : () STAGED : 1 1 A X W <<< BUFFIN holds 10 items maintaining this queue to handle extra input. BUFFIN : (Q 1 A 0 Z 2 B Y 0 1) <<< In the first iteration, item 1 is processed and BUFFIN incremented BUFFOUT : (? ? ? ? ? ? ? ? ? 0) <<< BUFFOUT routinely logs the items transferred to the OUTPUT register PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) <<< BUFFIN was preloaded and INPUT remains empty throughout this demo. OUTPUT : (0) <<< The OUTPUT register is 0 indicating the first item did not match. STAGED : (1 A X W) COMPARE : (1 2 0) <<< These three registers are associated with the comparison operator. CONJOIN : (? ? ?) <<< COMPARE checked for a match while CONJOIN and DISJOIN remain idle. DISJOIN : (? ? ?) BUFFIN : (1 A 0 Z 2 B Y 0 1 1) BUFFOUT : (? ? ? ? ? ? ? ? 0 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : (A X W) COMPARE : (Q 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (A 0 Z 2 B Y 0 1 1 A) BUFFOUT : (? ? ? ? ? ? ? 0 0 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : (X W) COMPARE : (1 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (0 Z 2 B Y 0 1 1 A X) BUFFOUT : (? ? ? ? ? ? 0 0 0 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : (W) COMPARE : (A 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (Z 2 B Y 0 1 1 A X W) BUFFOUT : (? ? ? ? ? 0 0 0 0 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : () COMPARE : (0 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (2 B Y 0 1 1 A X W ?) BUFFOUT : (? ? ? ? 0 0 0 0 0 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : () COMPARE : (Z 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (B Y 0 1 1 A X W ? ?) BUFFOUT : (? ? ? 0 0 0 0 0 0 1) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (1) STAGED : () COMPARE : (Y Y 1) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (Y 0 1 1 A X W ? ? ?) BUFFOUT : (? ? 0 0 0 0 0 0 1 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : () COMPARE : (B 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (0 1 1 A X W ? ? ? ?) BUFFOUT : (? 0 0 0 0 0 0 1 0 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : () COMPARE : (Y 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (1 1 A X W ? ? ? ? ?) BUFFOUT : (0 0 0 0 0 0 1 0 0 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : () COMPARE : (0 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (1 A X W ? ? ? ? ? ?) BUFFOUT : (0 0 0 0 0 1 0 0 0 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : () COMPARE : (1 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (A X W ? ? ? ? ? ? ?) BUFFOUT : (0 0 0 0 1 0 0 0 0 1) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (1) STAGED : () COMPARE : (X X 1) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (X W ? ? ? ? ? ? ? ?) BUFFOUT : (0 0 0 1 0 0 0 0 1 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : () COMPARE : (A 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) BUFFIN : (W ? ? ? ? ? ? ? ? ?) BUFFOUT : (0 0 1 0 0 0 0 1 0 0) PATONE : (1 A X ? ? ? ? ? ? ?) PATTWO : (2 B Y ? ? ? ? ? ? ?) INPUT : (?) OUTPUT : (0) STAGED : () COMPARE : (X 2 0) CONJOIN : (? ? ?) DISJOIN : (? ? ?) PATTERNS ((1 A X) (2 B Y)) <<< The next three lines summarize the results of the demonstration. INPUT (1 Q 1 A 0 Z 2 B Y 0 1 1 A X) OUTPUT (0 0 0 0 0 0 1 0 0 0 0 1 0 0) >
19 One alternative to a JIT is a bytecode interpreter that relies on a specialized fast compiler to compile programs into an intermediate format (bytecode) that runs on a virtual machine implemented in the bytecode interpreter. The bytecode interpreter produces machine code that runs faster than a conventional source-code interpreter although generally slower than an optimizing compiler. The advantage is that in a suitable integrated development environment, you can modify the code you are writing and recompile it as often as you like with a bytecode compiler (the IDE will do this for you automatically) without having to wait for the slower optimizing compiler.
20 The following excerpts are from O'Reilly et al [99] and focus on the role of cerebellum in learning and error correction. They also compare (see Table 5.1 in the text) the cerebellum and hippocampus in terms of shared cytoarchitecture, neural circuitry, learning signal and dynamics. Relevant to their dynamics both rely on pattern separation to differentiate between similar inputs and the hippocampus exploits attractor dynamics whereas the cerebellum does not. Note that the citation and the text below are taken from the 4th edition of the book released in 2020:
@book{OReillyetalCCN-20,
author = {Randall C. O'Reilly and Yuko Munakata and Michael J. Frank and Thomas E. Hazy Contributors},
title = {Computational Cognitive Neuroscience},
year = {2020},
publisher = {Wiki Book, 4th Edition},
}
Page 99:
The evolutionarily older areas of the basal ganglia, cerebellum, and hippocampus employ a separating form of activation dynamics, meaning that they tend to make even somewhat similar inputs map onto more separated patterns of neural activity within the structure. This is a very conservative, robust strategy akin to "memorizing" specific answers to specific inputs – it is likely to work OK, even though it is not very efficient, and does not generalize to new situations very well. Each of these structures can be seen as optimizing a different form of learning within this overall separating dynamic. The basal ganglia are specialized for learning on the basis of reward expectations and outcomes. The cerebellum uses a simple yet effective form of error-driven learning (basically the delta rule as discussed in the Learning Chapter). And the hippocampus relies more on hebbian-style self-organizing learning. Thus, the hippocampus is constantly encoding new episodic memories regardless of error or reward (though these can certainly modulate the rate of learning, as indicated by the weaker + signs in Table 5.1), while the basal ganglia is learning to select motor actions on the basis of potential reward or lack thereof (and is also a control system for regulating the timing of action selection), while the cerebellum is learning to swiftly perform those motor actions by using error signals generated from differences in the sensory feedback relative to the motor plan.
Page 122:
There is a nice division of labor here, where the basal ganglia help to select one out of many possible actions to perform, and the cerebellum then makes sure that the selected action is performed well. Consistent with this rather clean division of labor, there are no direct connections between the basal ganglia and cerebellum – instead, each operates in interaction with various areas in the cortex, where the action plans are formulated and coordinated. Both basal ganglia and cerebellum are densely interconnected with the frontal cortex, including motor control areas in posterior frontal cortex, and the prefrontal cortex anterior to those.
Page 133:
Now that we understand how the basal ganglia can select an action to perform based on reinforcement learning, we turn to the cerebellum, which takes over once the action has been initiated, and uses error-driven learning to shape the performance of the action so that it is accurate and well-coordinated. As shown in Figure 7.10, the cerebellum only receives from cortical areas directly involved in motor production, including the parietal cortex and the motor areas of frontal cortex. Unlike the basal ganglia, it does not receive from the prefrontal cortex or temporal cortex, which makes sense according to their respective functions. Prefrontal cortex and temporal cortex are really important for high-level planning and action selection, but not for action execution. However, we do know from neuroimaging experiments that the cerebellum is engaged in many cognitive tasks – this must reflect its extensive connectivity with the parietal cortex, which is also activated in many cognitive tasks.
Page 134:
Putting all these pieces together, David Marr (Marr 1969) and James Albus (Albus 1971) argued that the cerebellum is a system for error-driven learning, with the error signal coming from the climbing fibers. It is clear that it has the machinery to associate stimulus inputs with motor output commands, under the command of the climbing fiber inputs. One important principle of cerebellar function is the projection of inputs into a very high-dimensional space over the granule cells – computationally this achieves the separation form of learning, where each combination of inputs activates a unique pattern of granule cell neurons. This unique pattern can then be associated with a different output signal from the cerebellum, producing something approximating a lookup table of input/output values (Figure 7.12). A lookup table provides a robust solution to learning even very complex, arbitrary functions – it will always be able to encode any kind of function. The drawback is that it does not generalize to novel input patterns very well. However, it may be better overall in motor control to avoid improper generalization, rather than eek out a bit more efficiency from some form of generalization. This high-dimensional expansion is also used successfully by the support vector machine (SVM), one of the most successful machine learning algorithms.
21 Note that L2 subroutines are essentially frequently-used code fragments that consist of sequences of L1 primitives which, in this case, correspond to register transfers.
22 The functions first and rest were originally called car and cdr and stood for the "Contents of the Address Register" and "Contents of the Decrement Register" which are referred to as index registers on the IBM 704 computer.
In computer programming, car and cdr are primitive operations on cons cells (or "non-atomic S-expressions") introduced in the Lisp programming language. A cons cell is composed of two pointers; the car operation extracts the first pointer, and the cdr operation extracts the second. (SOURCE)
23 Here are Chaufei's observations relating to this post:
I think it would be interesting to think about how we can formulate the SIRT solver with some error correction mechanism. It seems that both Merel's task and SIRT involve planning, execution, error correction in each level of the hierarchy. If the task is to grasp something, the prefrontal cortex may figure out an overall plan/goal and execute it by hierarchically calling motor programs in motor cortex, and both the prefrontal cortex and motor cortex (maybe also cerebellum) monitor the overall progress and correct error if anything happens. And I think the same principle could also be applied to SIRT task. The current solution assumes we can only read one pass through the input. In theory this is enough to solve SIRT. But in more general cases like the abstract reasoning task we talked about before or the analogy task Hofstadter et al used to define intelligence, allowing the algorithm to read the input tape forward and backward multiple times may make the problem easier to solve. And the algorithm can learn to make mistakes (e.g. read in too many characters) and correct them (e.g go back to some point).
24 "The human cerebellum does not initiate movement, but contributes to coordination, precision, and accurate timing: it receives input from sensory systems of the spinal cord and from other parts of the brain, and integrates these inputs to fine-tune motor activity. The cerebellum differs from most other parts of the brain (especially the cerebral cortex) in that the signal processing is almost entirely feedforward—that is, signals move unidirectionally through the system from input to output, with very little recurrent internal transmission. The small amount of recurrence that does exist consists of mutual inhibition; there are no mutually excitatory circuits. [...] The cerebellum, Kenji Doya [34] proposes, is best understood as predictive action selection based on 'internal models' of the environment or a device for supervised learning, in contrast to the basal ganglia, which perform reinforcement learning, and the cerebral cortex, which performs unsupervised learning." (SOURCE)
25 "As you might recall, VAEs consist of 3 parts: (i) an encoder network that parametrizes the posterior q(z | x) over latents, (ii) a prior distribution p(z) and (iii) a decoder with distribution p(x | z) over input data. Typically we assume this prior and posterior to be normally distributed with diagonal variance. The encoder is then used to predict the mean and variances of the posterior.
In the proposed work however, the authors use discrete latent variables (instead of a continuous normal distribution). The posterior and prior distributions are categorical, and the samples drawn from these distributions index an embedding table. In other words: (i) encoders model a categorical distribution, sampling from which you get integral values, (ii) these integral values are used to index a dictionary of embeddings, and (iii) the indexed values are then passed on to the decoder.
 |
Reshape: all dimensions except the last one are combined into one so that we have n × h × w vectors each of dimensionality d;
Calculating distances: for each of the n × h × w vectors we calculate distance from each of k vectors of the embedding dictionary to obtain a matrix of shape (n × h × w, k);
Argmin: for each of the n × h × w vectors we find the the index of closest of the k vectors from dictionary;
Index from dictionary: index the closest vector from the dictionary for each of n × h × w vectors;
Reshape: convert back to shape (n, h, w, d).
Copying gradients: If you followed up till now you'd realize that it's not possible to train this architecture through backpropagation as the gradient won't flow through argmin. Hence we try to approximate by copying the gradients from zq back to ze. In this way we're not actually minimizing the loss function but are still able to pass some information back for training." (SOURCE)
26 "Mostly when thinking of Variational Autoencoders (VAEs), we picture the prior as an isotropic Gaussian. But this is by no means a necessity. The Vector Quantised Variational Autoencoder (VQ-VAE) described in van den Oord et al's "Neural Discrete Representation Learning" features a discrete latent space that allows to learn impressively concise latent representations. In this post, we combine elements of Keras, TensorFlow, and TensorFlow Probability to see if we can generate convincing letters resembling those in Kuzushiji-MNIST. [...]
About two weeks ago, we introduced TensorFlow Probability (TFP), showing how to create and sample from distributions and put them to use in a Variational Autoencoder (VAE) that learns its prior. Today, we move on to a different specimen in the VAE model zoo: the Vector Quantised Variational Autoencoder (VQ-VAE) described in Neural Discrete Representation Learning. This model differs from most VAEs in that its approximate posterior is not continuous, but discrete - hence the "quantised" in the article's title. We'll quickly look at what this means, and then dive directly into the code, combining Keras layers, eager execution, and TFP." (SOURCE)
27 Dauphin et al [20] suggest that "convolutional networks can be stacked to represent large context sizes and extract hierarchical features over larger and larger contexts with more abstract features [. . .] Gating has been shown to be essential for recurrent neural networks to reach state-of-the-art performance. Our gated linear units reduce the vanishing gradient problem for deep architectures by providing a linear path for the gradients while retaining non-linear capabilities."
28 Gehring et al [47] note that "convolutional neural networks are less common for sequence modeling, despite several advantages. Compared to recurrent layers, convolutions create representations for fixed size contexts, however, the effective context size of the network can easily be made larger by stacking several layers on top of each other. This allows to precisely control the maximum length of dependencies to be modeled."
29 By the way, if you haven't read Reed and DeFreitas [110] neural program interpreter (NPI) paper or aren't familiar with either their training approach or the related work mentioned in that paper, then I suggest you do. In their related work section, the authors mention several papers that were discussed in class last year:
Several ideas related to our approach have a long history. For example, the idea of using dynamically programmable networks in which the activations of one network become the weights (the program) of a second network was mentioned in the Sigma-Pi units section of the influential PDP paper (Rumelhart et al., 1986). This idea appeared in (Sutskever & Hinton, 2009) in the context of learning higher order symbolic relations and in (Donnarumma et al., 2015) as the key ingredient of an architecture for prefrontal cognitive control.Schmidhuber (1992) proposed a related meta-learning idea, whereby one learns the parameters of a slowly changing network, which in turn generates context dependent weight changes for a second rapidly changing network. These approaches have only been demonstrated in very limited settings. In cognitive science, several theories of brain areas controlling other brain parts so as to carry out multiple tasks have been proposed; see for example Schneider & Chein (2003); Anderson (2010) and Donnarumma et al. (2012).
The paper also provides details about the authors method for training which is similar to the method that I outlined in appendix and its addendum:
In this work we train the NPI with fully-supervised execution traces; each program has example sequences of calls to the immediate subprograms conditioned on the input. Rather than training on a huge number of relatively weak labels, NPI learns from a small number of rich examples. We demonstrate the capability of our model to learn several types of compositional programs: addition, sorting, and canonicalizing 3D models. Furthermore, a single NPI learns to execute these programs and all 21 associated subprograms.To train the NPI we use curriculum learning and supervision via example execution traces. Each program has example sequences of calls to the immediate subprograms conditioned on the input. We may envision two approaches to provide supervision. In one, we provide a very large number of labeled examples, as in object recognition, speech and machine translation. In the other, the approached followed in this paper, the aim is to provide far fewer labeled examples, but where the labels contain richer information allowing the model to learn compositional structure.
30 O'Reilly and Frank adopt a similar strategy in the PBWM paper [98] citing earlier work [100] on the phonological loop a working memory system [12] that can "actively maintain a short chunk of phonological (verbal) information. In essence, the task of this model is to encode and replay a sequence of 'phoneme' inputs, much as in the classic psychological task of short-term serial recall.
31 Here are Yash Savani's notes along with my comments on the challenges relating to the proposed effort to implement a system capable of learning to solve the Store Ignore Recall task and related symbol manipulation tasks requiring working memory:
# Executive Homunculus
Introduction
We want to leverage the recent innovations in machine learning and neuroscience to come up with a model that is able to solve cognitively challenging problems. An example of a problem we are interested in solving is the SIR (Store Ignore Recall) task that we have already discussed in some detail. We draw inspiration from the cognitive neuroscience literature to come up with a model that can solve such problems in a general way, with minimal exploitation of developer bias.
We abstract the roles of the posterior cortex, which processes and synthesizes complex multidimensional sensory inputs; and the anterior cortex, which executes and coordinates motor actions, as general neural network architectures that are trained using backpropagation. The primary focus of our discussion is the role of the execution management system, which we call the executive homunculus, that functionally sits between the posterior and anterior cortices. This system receives the output vectors from the posterior cortex and selects the value-maximizing action or subroutine vectors to send to the anterior cortex -- here we use the RL definition of value as the expected cumulative reward following a specific policy.
Memory Management
In order to solve most non-bandit tasks (tasks that have more than one state), the executive homunculus must have some form of memory to keep track of previous observations. Therefore, the simplest model we consider for the executive homunculus is an RNN. An RNN accepts a vector representing the semantic context derived from the sensory input. It then synthesizes this semantic vector with a hidden state from the previous time step. The synthesized output is represented by an action or subroutine vector used to execute the appropriate action. An RNN satisfies most of our needs since it can be used for any sequence-based task and is therefore general enough to exclude most developer bias. Furthermore, it uses a hidden vector that can encode any historical information needed to execute the desired functionality. It is also fully differentiable and can be trained using backpropagation. However, the RNN suffers from two key problems. First, it struggles with long sequences and has been shown to suffer from catastrophic forgetting. In other words, the RNN struggles to remember important information for long periods of time. So if the sequence began with a pattern the model is supposed to remember for the remainder of its execution, the RNN may struggle to remember that pattern beyond a few characters. Although, if the number of characters in the pattern is small, and it is allowed to forget elements in the sequence that can no longer contribute to a match, then theoretically an RNN should still be able to solve the SIR task. In practice, finding an appropriate algorithm may still take too long. The second flaw with the RNN is the amount of time required to train it. RNN models are extremely sample inefficient and take far too long to train well. This has something to do with the fact that the RNN model is too general. Since the RNN doesn't have any specialized methods to exploit the structure in the task, it takes too long for the RNN to learn any sufficiently acceptable algorithm given the complexity of the search space. Here we encounter a fundamental issue faced by the executive homunculus. The executive homunculus needs to be general enough so that it can solve most tasks without any change to the architecture or training mechanism, but it also needs to be efficient and exploit the structure of the task so it doesn't take too long and too many samples to train. Finding the correct level of abstraction is a fundamental issue we need to tackle when considering how to build such an executive homunculus. Our first attempt at tackling this issue is considering the LSTM.
The LSTM can be considered as an RNN with additional gating functionality. In other words, the LSTM is capable of storing its hidden state for longer periods of time. It can decide whether or not to change the contents of its hidden state using gates. This helps tackle the first problem with the RNN. By explicitly storing the contents of its hidden state for longer periods of time, the LSTM is able to remember important patterns for longer without falling prey to the catastrophic forgetting issue faced by the RNN. An LSTM would theoretically be able to remember the initial patterns in the sequence for as long as required and forget the patterns whenever prompted. However, the LSTM only has one hidden state that can be modified coarsely using the gating mechanism. This means that the LSTM would not be able to hold different pieces of information for different lengths of time. In other words, the memory management system for the LSTM is very coarse, though it is better than that of the RNN. Furthermore, the LSTM also suffers from similar sample complexity problems as the RNN. The LSTM is unable to learn the general task very quickly because other than a coarse gating mechanism, the LSTM has no other prior information or tools that it can use to exploit the structure of the problem. Therefore, while the model does take advantage of the gating mechanism to perform rudimentary memory management, the LSTM still takes a long time to learn.
In order to augment the memory of these recurrent networks even further, recent advances in NLP have introduced ideas of differentiable attention, where not only is the model able to use its memory but also it is able to use a differentiable attention layer to select prior tokens in the sequence to look at for additional context. In other words, the model is able to select previous parts of the sequence to look at again during its computation. An extreme version of such attentional models is the transformer model that has produced amazing results in the NLP domain. Essentially, these transformer models substitute the recurrent ideas from the LSTM and RNN with attentional components. The attentional components can select historical parts of the sequence to attend to and can combine these parts to create a semantic context on which to perform computation. Such a model would theoretically have infinite memory as it could easily attend to any part of the input sequence. It would be useful to see how well such a model would perform on the SIR task even though the ability of the transformer model to look at previous tokens might be considered cheating.
A final baseline model we might want to consider when comparing potential executive homunculi implementations is the DNC model. This is another model that takes inspiration from the attentional ideas like the transformer model. However, unlike the transformer model, the DNC does not abandon the recurrent ideas from the LSTM. Instead, it uses attentional ideas to extend the memory management system. Instead of relying on a single vector of memory like the LSTM, the DNC generalizes the memory so it is expandable and external to the memory management system. In other words, the DNC has an external reserve of memory in matrix form. It communicates with this external memory using read and write control heads. Based on the contextual input, the DNC uses the attentional functionality of its read and write heads to control I/O with the external memory. The attentional ideas are used here to ensure that the I/O operations of the DNC are differentiable and therefore backpropable. By using this external memory, the DNC is able to store complex context information for different lengths of time in its memory and can retrieve it with higher fidelity than the LSTM because of the more extensive memory management mechanism. Therefore, theoretically, the DNC would be able to store and retrieve the correct context for any task depending on the input. The DNC model, therefore, seems particularly well suited for complex retrieval tasks such as the SIR task. However, one potential drawback of the DNC model is its sample inefficiency when it comes to solving more complex tasks. This is because of the DNC's limited ability to synthesize contextual memory with the current sensory context. That is, the DNC relies on a simple LSTM or fully connected network to combine the memory vectors with the current sensory vector. The generality of the LSTM and the fully connected network means that learning how to combine these vectors would take a very long time.
Algorithmic Search Problem
While memory management is a critical tool to solve many non-bandit problems, care needs to be taken to not conflate the memory management problem with the search problem, which attempts to find the best algorithm for the task. Many problems may have a fully specified state where the state provides all the information needed by the model to select the best action. However, despite having all the required information, there are some problems that are still hard to solve because the number of possible ways to parse the available information may be combinatorially explosive. A classic example of such a problem is a chessboard configuration, where no historical information is needed to identify the optimal move, but finding the optimal move is still a challenge. Having a model that is able to choose a good policy when all the information is available is critical to building a workable executive homunculus.
TLD: We can arrange a curriculum learning protocol that starts with simple register-to-register transfers, graduates to conditional register-to-register transfers and then on to multiple transfers with a strong bias for reusing and adapting earlier learned subroutines. However, in order for this to work, the system has to be able to generalize– check out the comments about REMERGE and MEMO below. I would guess that, in the case of the tasks we are considering, the adaptations are easier to make and the consequences of failure less damaging. The importance of the bias for reusing earlier and thus simpler subroutines is to create a natural hierarchy. From my reading of the recent work on neural code generation, it appears to be generally simpler to repair a program than it is to construct a new one out of whole cloth – see [6, 117] and, in particular, Rishabh's papers [139, 140].
For all of the models we have considered, this algorithmic search task is handled using fairly general fully connected, or recurrent neural networks. While theoretically, such networks should be able to find the correct solution given enough data and compute power, we are obviously looking for the most efficient solution. In order to come up with such a solution, it is worthwhile to consider the approach taken by a human when solving a novel task. The human would first look at the task definition to see what the expected inputs, actions, and goals look like. They might tinker with a simulation of the task to make sure they understand the boundaries of the task, but after a while, they should get a sense of the problem. Then, either they will have been exposed to this problem before in some similar enough form that they can reproduce the solution with minimal changes, or they might break the task up into more manageable chunks, where each chunk seems isolated enough that it can be solved independently and then recombined later with the other chunks to produce the final solution. The way this chunking takes place is by looking for resonating chunks. Resonating chunks are chunks that follow a pattern that the human has already been exposed to in the past. Such patterns may take the form of an isomorphism where the human has been exposed to the symmetry of the state and action space before, perhaps in a different form. An example of a resonating chunk is a comparison operator, where part of the problem may be to compare two characters. While the human may never have compared two characters before, they may have compared two numbers and can generalize the idea of comparison to characters. Furthermore, when chunking the task the human would have to be aware of the way in which the solutions of the chunks are recombined. The chunk solutions may be recombined using different patterns, and knowing which recombination pattern to use is another key part of solving the problem. A classic example of a recombination pattern is recursion. A human might notice that a problem may be broken into simple comparison chunks whose solutions can be combined using the recursion pattern. Therefore guided by both experience and the boundaries of the problem, the human would be able to decompose the given problem into manageable chunks whose form and recombinations they have been exposed to and understand well enough to generalize to the current problem. Note that both the chunks and the recombination of the chunks can be thought of as functions, where the solution to the chunks involves functions that directly operate on the data, and the solution for the recombinations involve higher-order functions that operate on the functional solution of the chunks.
Curriculum Learning
An important part of solving any task involves recognizing the appropriate cues for what operations need to be performed. Any solution to a complex problem may involve the composition of multiple complex operations. In order to identify the correct operation, it is necessary for the agent to recognize the corresponding cues. For instance when solving any sentential logic problem, one would look for cues like the words "and," "or," and "not" to successfully parse the sentence. Similarly, when solving other problems, it is important to look for appropriate cues to know which operation to use. Learning to identify such cues is usually done using a curriculum learning regiment where multiple instances of the cue are provided to the model so it can learn to generalize the recognition of the cue from the example data.
Crude Prediction Model
While the curriculum forms a solid foundation on which the model can be trained to identify the appropriate cues, such cues may not be directly available in a more complex problem that involves combining several subproblems. To teach our executive homunculus to identify appropriate cues within the subproblems of a task, we hypothesize that the model will need to have access to a crude prediction model. The crude prediction model should be able to predict a compressed representation of the output of a given subprocess for any input. That is, if a neural subprocess outputs a high dimensional vector, the prediction model is only expected to be able to predict a low dimensional representation of the full output vector. The hope is that by using such a prediction model, the executive homunculus will be able to gain a high-level picture for what each subprocess does without reproducing the output of every subprocess perfectly. The executive homunculus could then use this prediction model to attempt to solve low dimensional versions of the original problem that may scale up to the larger problem. Furthermore, a crude predictor may be considered as an abstract representation of the full subprocess. This low dimensional representation of the task should be conditioned on the requirements of the task and the potential actions/subprocesses available. For instance, in a sorting task, the low dimensional representation of the largest to smallest sorted list should be close to the low dimensional representation of the smallest to largest sorted list. This is because changing the solution only requires flipping the direction of the comparison operator. Such a low dimensional representation, conditional on the actions and subprocesses available, may be represented by a compression of the successor representation matrix. To use the crude prediction model, the executive homunculus would have to be able to suggest a solution for a task and evaluate the solution through the crude prediction model. Then any errors could be corrected appropriately as the crude prediction model would provide a more directed error gradient since it is conditioned on the other potential subprocesses or actions that could have been taken.
Implementations
There are 2 potential extremes for how an executive homunculus may be implemented. At one extreme, the executive homunculus would only have discrete actions it could take, moving vectors discretely from the posterior cortex through the subprocesses to the eventual output. In this model, the executive homunculus would essentially be writing a primitive form of assembly code in order to solve problems. Any problem involving writing code suffers from the combinatorial explosion of the search space, so in order to make sure that such a discrete model works well, it will be critical to set up an appropriate learning curriculum. The hope is that such a model would be able to learn how to select discrete actions in an incremental way building up to more complex assembly programs. However, we are wary that any problem of this kind suffers from major learning issues because of the sparsity of the rewards it receives. That is, when solving complex tasks, a model that writes code would only receive a reward for the correct output. While this may not be as sparse for simple problems at the beginning of the curriculum, it is not as clear that there is a smooth transition from simple problems to hard problems. For instance, it is not clear that simply because a model may have learned how to execute a for loop and to use temporary registers to store information, it would be able to identify the correct recursive structure in a graph traversal problem. Though, given the hierarchical nature of the solution, it may not take as long for the model to experiment with every combination of the curriculum trained procedures, as compared to a model that had to be trained to solve the task from scratch.
The other extreme for how an executive homunculus may be implemented is one where the model is entirely differentiable. In such a model the action space is differentiable, potentially inspired by the attentional components like the DNC. The advantage of using such a model would be that the errors in the task could be backpropagated through the executive homunculus. In this way, the executive homunculus could smoothly adjust the attentional components of its read-write heads in order to find the most appropriate path for the vectors to take through the system. This is an appealing solution because the combinatorial explosion of possible programs is replaced with a smooth attentional code that can be trained using classical supervised learning. Since supervised learning is known to be more stable than reinforcement learning, this is an extremely appealing solution. One of the drawbacks of this model is that such a model would be incredibly difficult to debug. Since everything is differentiable it is not clear how to coerce this model to use the submodules appropriately, or how to get the model to use more complex recurrent structures.
In between these extremes is an executive homunculus implementation that is able to combine the differentiable and discrete action space models. Such a combination would benefit from both stable training and interpretability/debuggability. Such a model could potentially use a smooth differentiable action space with the coarse prediction model on a low dimensional version of the task to identify an appropriate algorithm, and then produce discrete actions for the actual implementation. In order for this to work, the information learned by solving the low dimensional version of the problem using the differentiable model would have to be transferred to the model responsible for the production of the discrete action.
One potential solution for how this information could be communicated and encoded is inspired by the idea of finding isomorphisms between problems. In other words, the ability to abstract the details of the problem to find other abstractions that are similar. For instance, when trying to solve a Rubik's cube one may find that the state action space for a Rubik's cube is similar to a subgroup of a symmetric group. So, in order to solve the Rubik's cube, we may attempt to use algorithms known to work on other symmetric group problems. Another example would be when attempting to solve the towers of Hanoi problem. On inspection, it is clear that this problem decomposes into similar subproblems, and therefore the state and action space is isomorphic to many recursive structures like fractals. This type of relationship is mapped in the neocortex of the brain through the bidirectional linkages between different ideas that share similarities. These bidirectional linkages are the substrate of semantics. Knowing something is being able to relate it to other things we know. We have found word vectors to be powerful instances of semantic representation in NLP. However, we have yet to find semantic representations for other more abstract concepts.
One idea for how to use this inspiration in our executive homunculus may be to represent every operator as a vector. Then, perhaps the semantics of the operator would be encoded in the components of the vector. So for instance the operator vectors for addition:subtraction::multiplication:division. Therefore, when the executive homunculus is searching for an appropriate operator, it may query for the operator through a vector that can be compared to the semantic representations for each operator. For instance, if the executive homunculus is searching for the division operator, it may query for the operator using the vector multiplication + (subtraction - addition). This also has some relationship to Hopfield networks and transformer networks since both use similar key-value query vectors to find semantically appropriate tokens. To train these encodings we would use an operator embeddings network. We can encode linear operators using matrices, and we can compare how similar linear functions are by comparing the eigenvalues of these matrices. Similarly, if we would use an operator embeddings model to encode a low dimensional, eigenvectoresque, representation of each operator, we could use it as a basis to learn the semantic encodings of the operators. Then when we are faced with a new problem we have not seen, the network can query for the low dimensional representation of an operator that is isomorphic to the task. That is, it would query for the operator that seems most appropriate to the current task. So the executive homunculus would use a transformer like architecture to interface with the operator embeddings model, which is responsible for encoding operators into vectors. Then based on these vectors, the executive homunculus would be able to explore the space of operators by looking for isomorphic operators that resonate with the problem action state space. Furthermore, the subspace that these vectors are embedded in may not be multidimensional Euclidean space. This is because there are higher-level operators that act on the basic subprocesses that do not behave linearly. For instance, composition, recursion, currying, map, reduce, etc. are not linear operators. More specifically, we would need to at least support the composition operator as composition may be considered the building block for all the other higher-level operators. A natural space for encoding subprocesses combined using composition would be a hyperbolic space. Since hyperbolic space naturally supports tree and graph encodings, such a space seems a particularly good fit for encoding subprocesses that can be composed into graph-like structures like an abstract syntax tree. By using this semantic representation for operators and combining it with a successor representation for the state, as proposed in the crude prediction model section above, the executive homunculus would be able to query for the most appropriate operators given the task state.
Conclusion
In conclusion, there are two key components of the executive homunculus we have discussed here. The first is the memory management mechanism. Any implementation that is expected to solve non-bandit tasks should have some ability to remember past states and actions. In order to have this memory management system without incorporating developer bias, we consider the ideas of recurrence from RNN, LSTM, and DNC networks, and attention from transformer and DNC networks. The second component we discussed is the algorithmic search problem where the executive homunculus is expected to efficiently search through the combinatorial explosion of potential subprocess amalgamations in order to find one that suitably solves the task. While the general fully connected and recurrent networks used in the literature can theoretically learn the optimal solution, they may take extremely long to converge to it. Instead, we consider the idea of using a coarse prediction model that is capable of generalizing the role of the subprocesses using low dimensional compressions of the input and output vectors. We also consider a transformer-based executive model that leverages semantic representations of operators through key-value queries to find the appropriate, isomorphic operators for the current task state.
TLD: Have you read Kumaran and McClelland [74] paper on REMERGE (Recurrency and Episodic Memory Results in Generalization) in which they explain how the use of orthogonalized codes in the hippocampus support generalization as long as "there is recurrence rather than unidirectional flow within the hippocampal circuit or, more widely, between the hippocampus and neocortex", and propose that "recurrent similarity computation, a process that facilitates the discovery of higher-order relationships between a set of related experiences, expands the scope of classical exemplar-based models of memory and allows the hippocampus to support generalization through interactions that unfold within a dynamically created memory space." REMERGE is also cited as inspiration in the Banino et al [14] introducing MEMO. Your repeated emphasis on the importance of dealing with the underlying combinatorics and the idea of using a transformer-based executive model reminded me of MEMO – there are probably other tricks we can borrow from the MEMO implementation
32 Dehaene [27] describes Donald Hebb's original notion of a cell assembly as follows:
Whenever we become aware of an unexpected piece of information, the brain suddenly seems to burst into a large-scale activity pattern. My colleagues and I have called this property "global ignition." Hebb explained, in very intuitive terms, how a network of neurons that excite one another can quickly fall into a global pattern of synchronized activity—much as an audience, after the first few handclaps, suddenly bursts into broad applause. Like the enthusiastic spectators who stand up after a concert and contagiously spread the applause, the large pyramidal neurons in the upper layers of cortex broadcast their excitation to a large audience of receiving neurons. Global ignition, my colleagues and I have suggested, occurs when this broadcast excitation exceeds a threshold and becomes self-reinforcing: some neurons excite others that, in turn, return the excitation. The net result is an explosion of activity: the neurons that are strongly interconnected burst into a self-sustained state of high-level activity, a reverberating "cell assembly," as Hebb called it.
33 Merel et al [83] use motion-capture data to learn actions, at, by stringing together micro movements to reproduce movement trajectories that approximately track the kinematic position of the body in the MOCAP data. They use a coding space, zt, to represent these movements thereby enabling interpolation among them. Summarizing the correspondence between Merel et al and the present work, motor primitives (actions) map to program primitives, micro movements map to register transfers and the coding space maps to signature space. (SOURCE)
34 In developing the ECS, I'm looking for inspiration in a better understanding of the relationship between working memory and more distributed and dynamic models of binding and routing information in the cortex such as Baar's global workspace theory [11] and its extensions including Changeux and Dehaene's global neuronal workspace model [77]. I'm also borrowing ideas from computer systems and natural language processing; in particular, the idea that in declaring a variable the operating system allocates a location in memory and in performing operations on the value stored in that location the OS selects a register in the ALU depending on the type of that value and operation to be performed. I don't want the ECS having to select and allocate registers. I want the ECS to create representations of computations involving the neural analogue of variables that are essentially typed and the RMS or some intermediate layer between the ECS and RMS to take care of all the details. Our natural language ability has to depend on some variant of this service.
35 The system is first trained using motion capture data of humans performing movements. The motion capture data are time series of configurations of the body and joints. The details of the construction of the system are not critical, but, to give some insight, for each motion capture snippet, a neural network is trained by RL to produce actions, at, such that the resulting movement trajectory approximately tracks the kinematic position of the body in the original reference motion. Then, these movement controllers are combined or "distilled" into one large model that can track any of the movements given a description of the near future path of the body. [See Box 1 "Reusable motor skills for hierarchical control of bodies" in Merel et al [83]]
36 In thinking more about this and continuing with the analogy to conventional computing hardware and software:
The program counter (PC), called the instruction pointer in Intel x86, is processor register that indicates where a computer is in its program sequence. Usually, the PC is incremented after fetching an instruction, and holds the memory address ("points to") the next instruction that would be executed. Processors usually fetch instructions sequentially from memory, but control transfer instructions change the sequence by placing a new value in the PC. These include branches (sometimes called jumps), subroutine calls, and returns. A transfer that is conditional on the truth of some assertion lets the computer follow a different sequence under different conditions. A branch provides that the next instruction is fetched from elsewhere in memory. A subroutine call not only branches but saves the preceding contents of the PC somewhere. A return retrieves the saved contents of the PC and places it back in the PC, resuming sequential execution with the instruction following the subroutine call. (SOURCE)
37 Overall architecture of the PBWM model. Sensory inputs are mapped to motor outputs via posterior cortical ("hidden") layers, as in a standard neural network model. The PFC contextualizes this mapping by representing relevant prior information and goals. The basal ganglia (BG) update the PFC representations via dynamic gating, and the PVLV system drives dopaminergic (DA) modulation of the BG so it can learn when to update. [See Figure 5 in OReilly and Frank [98]]
38 In the mathematical theory of stochastic processes, variable-order Markov (VOM) models are an important class of models that extend the well known Markov chain models. In contrast to the Markov chain models, where each random variable in a sequence with a Markov property depends on a fixed number of random variables, in VOM models this number of conditioning random variables may vary based on the specific observed realization. This realization sequence is often called the context; therefore the VOM models are also called context trees. The flexibility in the number of conditioning random variables turns out to be of real advantage for many applications, such as statistical analysis, classification and prediction. (SOURCE)
39 Here are the bibliography references including abstracts for the two Koechlin et al paper described in the text:
@article{KoechlinetalPNAS-00,
journal = {Proceedings of the National Academy of Sciences},
author = {Koechlin, Etienne and Corrado, Gregory and Pietrini, Pietro and Grafman, Jordan},
title = {Dissociating the role of the medial and lateral anterior prefrontal cortex in human planning},
volume = 97,
issue = 13,
year = 2000,
pages = {7651-7656},
abstract = {The anterior prefrontal cortex is known to subserve higher cognitive functions such as task management and planning. Less is known, however, about the functional specialization of this cortical region in humans. Using functional MRI, we report a double dissociation: the medial anterior prefrontal cortex, in association with the ventral striatum, was engaged preferentially when subjects executed tasks in sequences that were expected, whereas the polar prefrontal cortex, in association with the dorsolateral striatum, was involved preferentially when subjects performed tasks in sequences that were contingent on unpredictable events. These results parallel the functional segregation previously described between the medial and lateral premotor cortex underlying planned and contingent motor control and extend this division to the anterior prefrontal cortex, when task management and planning are required. Thus, our findings support the assumption that common frontal organizational principles underlie motor and higher executive functions in humans.},
}
@article{KoechlinetalSCIENCE-03,
author = {Etienne Koechlin and Chryst\`{e}le Ody and Fr\'{e}d\'{e}rique Kouneiher},
title = {The architecture of cognitive control in the human prefrontal cortex},
journal = {Science},
volume = 302,
year = 2003,
pages = {1181-1185},
abstract = {The prefrontal cortex (PFC) subserves cognitive control: the ability to coordinate thoughts or actions in relation with internal goals. Its functional architecture, however, remains poorly understood. Using brain imaging in humans, we showed that the lateral PFC is organized as a cascade of executive processes from premotor to anterior PFC regions that control behavior according to stimuli, the present perceptual context, and the temporal episode in which stimuli occur, respectively. The results support an unified modular model of cognitive control that describes the overall functional organization of the human lateral PFC and has basic methodological and theoretical implications.},
}
40 Relying on a non-differentiable memory-management system for working memory is another example of our reducing sample complexity by providing prosthetic assistive technology to finesse problems that are difficult for humans and yet their mastery does not contribute beyond what a prosthetic has to offer, in much the same way that a digital calculator accelerates learning more advanced math skills that would otherwise have to be taught later in the curriculum or not at all.
41 Here is the text from Box 1 in Merel et al [83] entitled "Reusable motor skills for hierarchical control of bodies":
End-to-end RL with a "flat" controller initially explores the space of possible behaviors through uncoordinated, unstructured movements of each joint independently. For a complicated, humanoid body, intelligent behavior in this space is a needle in a haystack, making the search for task solutions a difficult problem. To promote a diversity of behavior as well as the exploration and discovery of new ones, the neural probabilistic motor primitives (NPMP) architecture has been introduced [84], which expresses a set of robust, human-like motor behaviors as a basis for further task learning. The system is first trained using motion capture data of humans performing movements. The motion capture data are time series of configurations of the body and joints. The details of the construction of the system are not critical, but, to give some insight, for each motion capture snippet, a neural network is trained by RL to produce actions, at, such that the resulting movement trajectory approximately tracks the kinematic position of the body in the original reference motion.Then, these movement controllers are combined or "distilled" into one large model that can track any of the movements given a description of the near future path of the body, x*t. A coding space, zt, in the system comes to represent each of these movements and allows interpolation among them. Downstream of the code is a motor policy, which, when cued with zt and proprioceptive information st, is able to generate patterns of human-like movement autonomously. Thus, exploration of the space of human-like movements becomes possible by varying the input zt to the motor policy. To this low-level motor system, a high-level controller can be attached to solve complicated tasks in virtual environments. The high- level controller has full visual input and is provided task information, ot. It learns by RL to produce actions of the same size as the coding space, which modulate the movements carried out by the low-level policy. The NPMP's modular, hierarchical design has made it possible to solve complicated problems otherwise of great difficulty for flat RL.
42 The principles for hierarchical control summarized in Table 1 of [83] are also worth taking the time to understand and think about how they might apply in our case. The principle of modular objectives summarized as "specific subsystems may be trained to optimize specific objectives, distinct from the global task objective" seems particularly relevant to the strategies we've been talking about:
Modular objectives. Many examples of neural networks applied to control problems use "end-to-end" optimization; that is, there is a single task objective, and the entirety of the architecture maximizes this singular objective. However, the broad alternative is that control systems have some functional separation of roles by subsystem, and different modules benefit from being trained by distinct modular objectives. A specific, practical, and popular approach trains a controller to solve a task while also training a set of internal representations to predict future sensory data. This approach to learning internal state representa- tions can improve experience efficiency by leveraging dense self- supervised objectives to train perceptual and memory modules, whereas task reward can still provide learning signals for the controller. This approach is "heterarchical" insofar as different objective functions, consisting of a predictive objective as well as a policy improvement objective, are imposed in parallel on different parts of the overall network architecture.Another classic approach involves the overall system specifying subordinate objectives for modular subsystems, while maintaining the priority of a high-level objective. Paradigmatically for control problems, a high-level controller can communicate a goal to a low-level controller, which serves both as instruction to modulate low-level behavior and also as a reference for learning. Such an approach amounts to a divide- and-conquer strategy, and has been implemented via reinforcement learning. For example, in locomotion control, a high-level controller may decide to move in a certain direction, provide a signal to the low-level controller as instruction, and this signal also serves as a dense teaching signal that the low-level controller learns from as it assesses how well it stays on the instructed course. In such schemes, the low-level controller is trained to satisfy its received instruction, whereas the high-level controller intelligently programs these objectives to solve a more global task. Most work on this idea has used fixed forms of the cost function for the low-level controller, but other work has explored how to learn more abstract goal spaces.
43 Somehow we have to communicate the goal of the training exercise to the system during training without allowing it to depend on the training cues during test time. One way of doing this is to create a training set by simulating what the system is supposed to do and then using simulated prior stated out of context in order to induce the system to do the right thing. By "out of context" I mean that we can use any step in the previously recorded simulation to create a short training example.
45 Here "load" implies: transfer contents from the (source) w1 register to the (operator) w2 input register, and "read" implies: transfer contents from the corresponding (result) w2 output register to the (sink) w1 register.
46 For reasons that will become clear later, in the model developed in this document, primitives implementing functions that would normally take two or more arguments are effectively curried so that, for example, a function that would normally take three arguments in most programming languages would be converted into three functions each of which takes one argument: w = f(x,y,z) becomes h = g(x), k = h(y), w = k(z). All three of the primitives mentioned as examples in the text – AND, OR and EQUAL, can take two or more arguments.
In mathematics and computer science, currying is the technique of converting a function that takes multiple arguments into a sequence of functions that each take a single argument. Currying is useful in both practical and theoretical settings. In functional programming languages, and many others, it provides a way of automatically managing how arguments are passed to functions and exceptions. In theoretical computer science, it provides a way to study functions with multiple arguments in simpler theoretical models which provide only one argument. It was introduced by Gottlob Frege, developed by Moses Schönfinkel, and further developed by Haskell Curry.(SOURCE)
47 According to Johnson [63], there are four main concepts associated with the memory process of chunking: chunk, memory code, decode, and recode. The chunk, as mentioned prior, is a sequence of to-be-remembered information that can be composed of adjacent terms. These item or information sets are to be stored in the same memory code. The process of recoding is where one learns the code for a chunk, and decoding is when the code is translated into the information that it represents.
In cognitive psychology, chunking is a process by which individual pieces of an information set are broken down and then grouped together in a meaningful whole. The chunks by which the information is grouped is meant to improve short-term retention of the material, thus bypassing the limited capacity of working memory. A chunk is a collection of basic familiar units that have been grouped together and stored in a person's memory. These chunks are able to be retrieved more easily due to their coherent familiarity. It is believed that individuals create higher order cognitive representations of the items within the chunk. The items are more easily remembered as a group than as the individual items themselves. These chunks can be highly subjective because they rely on an individuals perceptions and past experiences, that are able to be linked to the information set. The size of the chunks generally range anywhere from two to six items, but often differ based on language and culture. (SOURCE)
48 Figure 17 in the introductory course notes for CS379C describes how we might represent programs as abstract syntax trees and partition DNC memory, as in a conventional von Neumann architecture, into program memory and a LIFO execution (call) stack to support recursion and reentrant procedure invocations, e.g., including call frames for return addresses, local variable values and related parameters. The DNC controller manages the program counter and LIFO call stack to simulate the execution of programs stored in program memory. Program statements are represented as embedding vectors and the system learns to evaluate these representations in order to generate intermediate results that are also embeddings. The following graphic illustrates how this sort of model might be incorporated into a larger architecture including a model of executive control designed to develop and debug software:
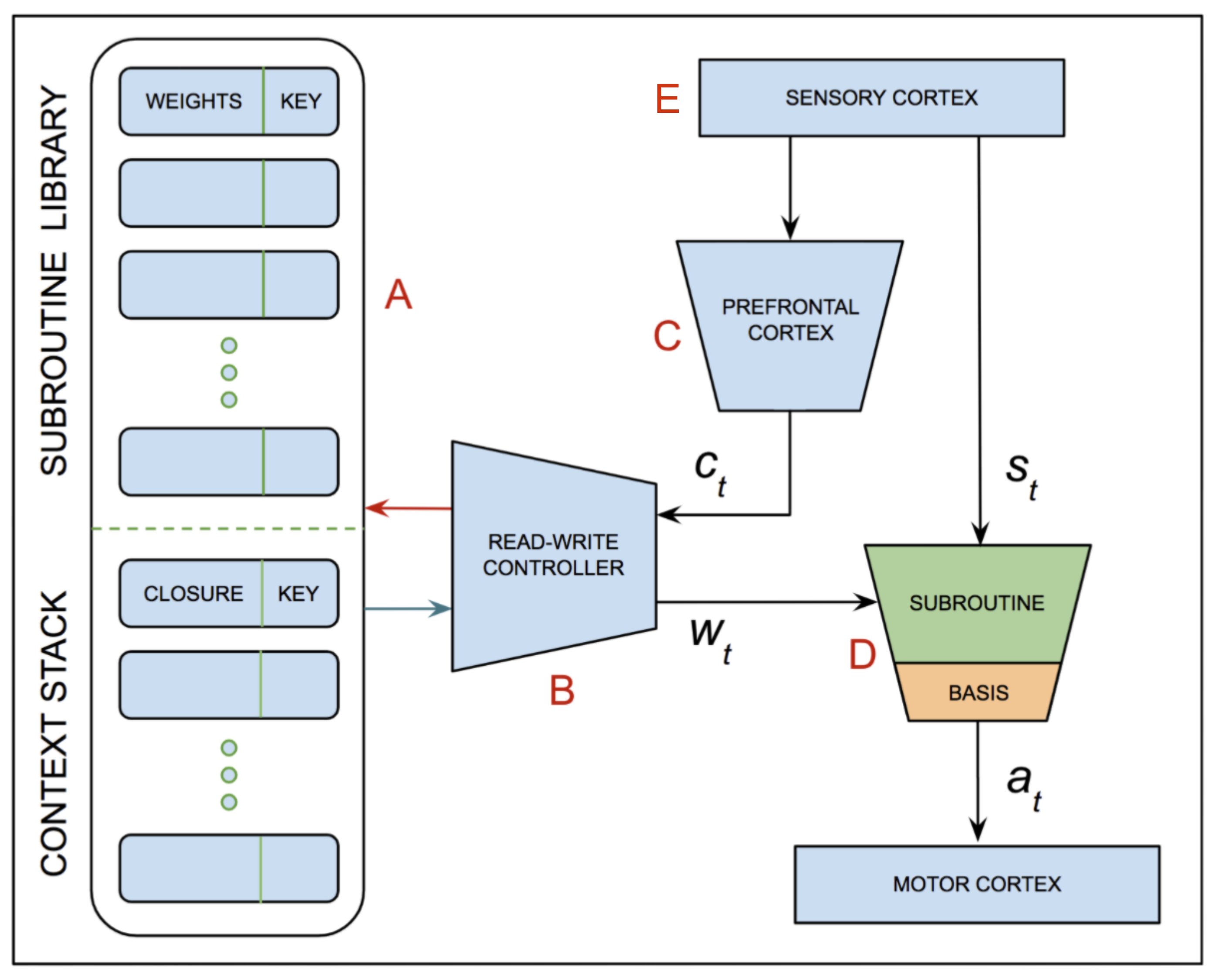
49 Anders Ericsson and Walter Kintsch [39] have introduced the notion of "long-term working memory", which they define as a set of "retrieval structures" in long-term memory that enable seamless access to the information relevant for everyday tasks. In this way, parts of long-term memory effectively function as working memory. See the reference to acquired memory skills in the excerpt below referring to the sort of effortful variable binding and maintenance mentioned earlier in the text and required to master the SIR task:
To account for the large demands on working memory during text comprehension and expert performance, the traditional models of working memory involving temporary storage must be extended to include working memory based on storage in long-term memory. In the proposed theoretical framework cognitive processes are viewed as a sequence of stable states representing end products of processing. In skilled activities, acquired memory skills allow these end products to be stored in long-term memory and kept directly accessible by means of retrieval cues in short-term memory, as proposed by skilled memory theory. These theoretical claims are supported by a review of evidence on memory in text comprehension and expert performance in such domains as mental calculation, medical diagnosis, and chess. (SOURCE)
50 Baddeley and Hitch's [13] model of working memory is similar in some respects to the the DNC controlled switchboard model proposed in earlier posts. Michael specifically mentioned the phonological loop which deals with spoken and written language and is divided into the phonological store holding information in a speech-based form and a recurrent articulatory process that enables us to repeat verbal information in a loop:
The original model of Baddeley & Hitch was composed of three main components: the central executive which acts as a supervisory system and controls the flow of information from and to its slave systems: the phonological loop and the visuo-spatial sketchpad. The phonological loop stores verbal content, whereas the visuo-spatial sketchpad caters to visuo-spatial data. Both the slave systems only function as short-term storage centers. [...] The third slave system was designated as episodic buffer. It is considered a limited-capacity system that provides temporary storage of information by conjoining information from the subsidiary systems, and long-term memory, into a single episodic representation. SOURCE
 . .
|
51 Here is an example of modulating policy hierarchies using bit-vector identifiers for individual policies in order to avoid catastrophic interference and facilitate transfer learning:
@article{PashevichetalCoRR-18,
author = {Alexander Pashevich and Danijar Hafner and James Davidson and Rahul Sukthankar and Cordelia Schmid},
title = {Modulated Policy Hierarchies},
journal = {CoRR},
volume = {arXiv:1812.00025},
year = {2018},
abstract = {Solving tasks with sparse rewards is a main challenge in reinforcement learning. While hierarchical controllers are an intuitive approach to this problem, current methods often require manual reward shaping, alternating training phases, or manually defined sub tasks. We introduce modulated policy hierarchies (MPH), that can learn end-to-end to solve tasks from sparse rewards. To achieve this, we study different modulation signals and exploration for hierarchical controllers. Specifically, we find that communicating via bit-vectors is more efficient than selecting one out of multiple skills, as it enables mixing between them. To facilitate exploration, MPH uses its different time scales for temporally extended intrinsic motivation at each level of the hierarchy. We evaluate MPH on the robotics tasks of pushing and sparse block stacking, where it outperforms recent baselines.}
}