Running Experiments
Running Experiments
All experiments are launched via run_benchmark.py. Results are saved to experiments/<task>/<provider>/<model>_<approach>_topk<k>.jsonl.
System Illustration
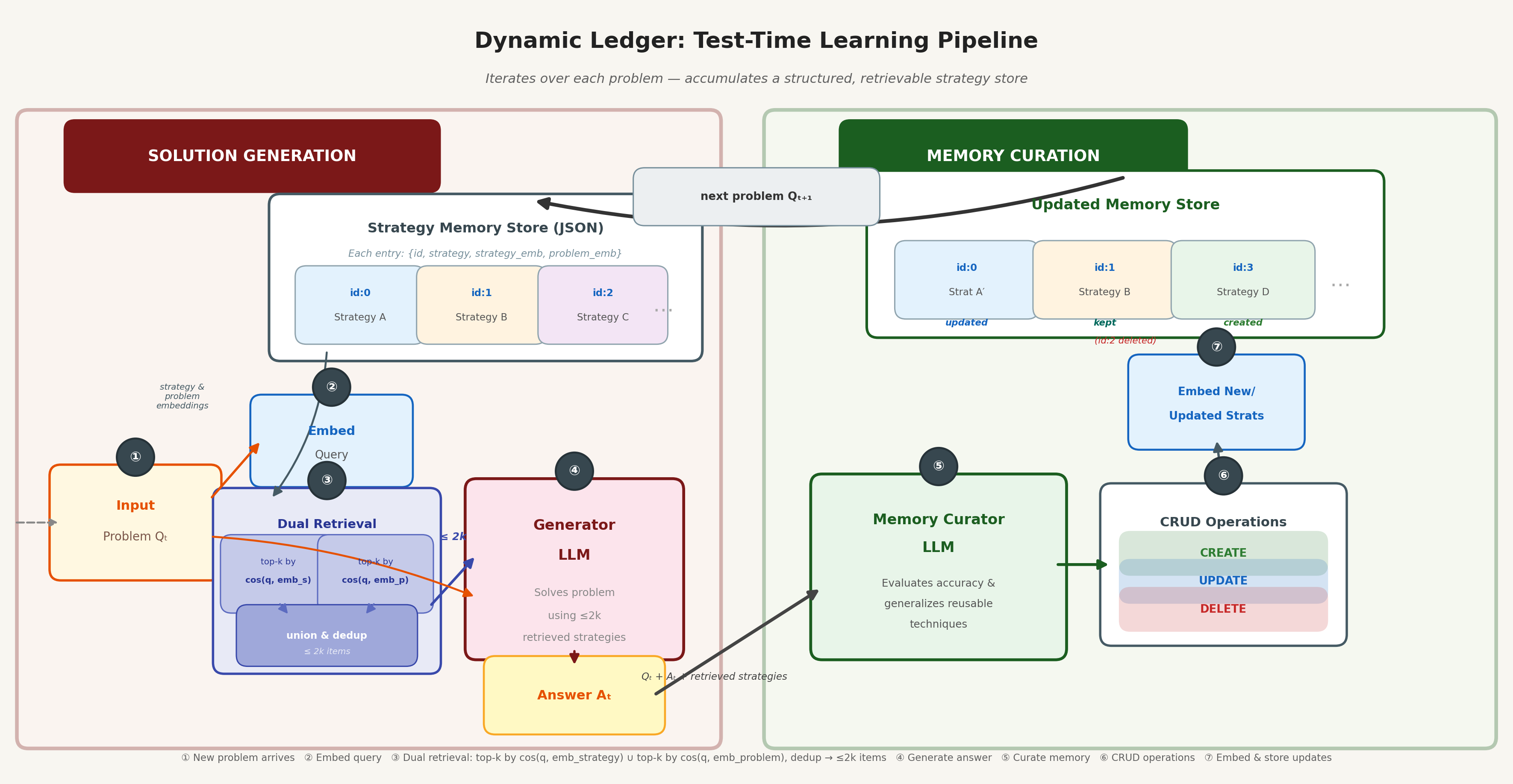
Approaches
All supported approaches and their descriptions:
| Approach | --approach_name | Description |
|---|---|---|
| Baseline | default | No cheatsheet; single-pass generation |
| Empty Cheatsheet | EmptyCheatsheet | Empty cheatsheet passed to the generator prompt |
| DC-Cumulative | DynamicCheatsheet_Cumulative | Append-only flat text cheatsheet (original DC) |
| DC-Retrieval Synthesis | DynamicCheatsheet_RetrievalSynthesis | Retrieve past examples, synthesize a query-specific cheatsheet |
| Dynamic Retrieval | Dynamic_Retrieval | Retrieve top-k past Q&A pairs, no curation step |
| Full History Appending | FullHistoryAppending | Full conversation history appended as context |
| Strategic Chunk Retrieval | DynamicCheatsheet_StrategicChunkRetrieval | Retrieve top-k strategy chunks; curator refines only those chunks |
| Dynamic Ledger | DynamicCheatsheet_DynamicLedger | Structured JSON store with per-entry CRUD updates and dual-embedding retrieval |
Parameters
Full reference for all run_benchmark.py arguments:
| Parameter | Default | Description |
|---|---|---|
--task | GameOf24 | Benchmark task name (see supported benchmarks below) |
--approach_name | DynamicCheatsheet_Cumulative | DC variant to use (see approaches table above) |
--model_name | openai/gpt-4o-mini | LLM to use (format: provider/model) |
--generator_prompt_path | prompts/generator_prompt.txt | Path to the generator system prompt |
--cheatsheet_prompt_path | None | Path to the curator/cheatsheet prompt. Auto-selected for Dynamic Ledger if not provided |
--retrieve_top_k | 3 | Number of strategy chunks to retrieve (used by retrieval-based approaches) |
--prob | None | Probability threshold for retrieval — if set, uses softmax(similarity) to select entries whose cumulative probability exceeds this threshold (e.g. 0.8) instead of top-k |
--max_tokens | 2048 | Maximum tokens for generator output |
--temperature | 0.0 | Sampling temperature |
--max_num_rounds | 1 | Number of generation rounds per problem |
--execute_python_code | True | Whether to execute Python code blocks in model output |
--initialize_cheatsheet_path | None | Path to a pre-built cheatsheet/ledger to start from |
--max_n_samples | -1 | Cap on examples to process; -1 for the full dataset |
--no_shuffle | False | Disable dataset shuffling (default: shuffle with seed 10) |
--save_directory | experiments | Root directory for saving results |
--additional_flag_for_save_path | "" | Extra tag appended to the output filename |
Supported Benchmarks
--task value | Description | Size |
|---|---|---|
AIME_2020_2024 | AIME 2020–2024 competition math | 133 |
AIME_2024 | AIME 2024 only | 30 |
AIME_2025 | AIME 2025 only | 30 |
IneqMath | IneqMath dev split (inequality proofs) | 100 |
IneqMath_all | IneqMath train + dev merged | 1,352 |
MathEquationBalancer | Chemical equation balancing | 250 |
DataSIR | Full sensitive information recognition dataset | 1,647,501 |
DataSIR400 | DataSIR 400-problem subset used in our evaluation | 400 |
GPQA_Diamond | Graduate-level science QA | varies |
MMLU_Pro_Physics | MMLU-Pro Physics subset | 1,299 |
MMLU_Pro_Engineering | MMLU-Pro Engineering subset | 969 |
GameOf24 | Game of 24 | varies |
Example Commands
Baseline (No Cheatsheet)
python3 run_benchmark.py \
--task IneqMath_all \
--approach_name default \
--model_name openai/gpt-4o \
--max_n_samples 600Dynamic Ledger
python3 run_benchmark.py \
--task IneqMath_all \
--approach_name DynamicCheatsheet_DynamicLedger \
--model_name openai/gpt-4o \
--generator_prompt_path prompts/generator_prompt_dynamic_ledger.txt \
--cheatsheet_prompt_path prompts/curator_prompt_dynamic_ledger.txt \
--retrieve_top_k 3 \
--max_n_samples 600Strategic Chunk Retrieval
python3 run_benchmark.py \
--task IneqMath_all \
--approach_name DynamicCheatsheet_StrategicChunkRetrieval \
--model_name openai/gpt-4o \
--cheatsheet_prompt_path prompts/curator_prompt_for_strategic_chunk_retrieval.txt \
--retrieve_top_k 3 \
--max_n_samples 600Strategic Chunk Retrieval (Probability Threshold)
python3 run_benchmark.py \
--task AIME_2020_2024 \
--approach_name DynamicCheatsheet_StrategicChunkRetrieval \
--model_name openai/gpt-4o \
--cheatsheet_prompt_path prompts/curator_prompt_for_strategic_chunk_retrieval.txt \
--prob 0.8 \
--max_n_samples 600DC-Cumulative (Original)
python3 run_benchmark.py \
--task IneqMath_all \
--approach_name DynamicCheatsheet_Cumulative \
--model_name openai/gpt-4o \
--max_n_samples 600DC-Retrieval Synthesis
python3 run_benchmark.py \
--task IneqMath_all \
--approach_name DynamicCheatsheet_RetrievalSynthesis \
--model_name openai/gpt-4o \
--retrieve_top_k 3 \
--max_n_samples 600Dynamic Retrieval
python3 run_benchmark.py \
--task AIME_2020_2024 \
--approach_name Dynamic_Retrieval \
--model_name openai/gpt-4o \
--retrieve_top_k 3 \
--max_n_samples 600Full History Appending
python3 run_benchmark.py \
--task DataSIR400 \
--approach_name FullHistoryAppending \
--model_name openai/gpt-5-2025-08-07 \
--max_n_samples 400DataSIR Benchmark
The full DataSIR dataset contains 1,647,501 examples (~460 MB JSON). A compressed version data/DataSIR.json.gz (43 MB) is included in the repo. On the first run with --task DataSIR, run_benchmark.py automatically decompresses and builds the Arrow dataset. The DataSIR400 subset (400 problems) is the evaluation set used in our paper.
python3 run_benchmark.py \
--task DataSIR400 \
--approach_name DynamicCheatsheet_DynamicLedger \
--model_name openai/gpt-5-2025-08-07 \
--retrieve_top_k 3 \
--max_n_samples 400Rebuilding IneqMath Dataset
python3 prepare_ineqmath_all.pyAuto-Resume
If a partial run exists at the expected output path, run_benchmark.py automatically resumes from where it left off. It validates that key parameters (model, task, approach, temperature, etc.) are consistent with the previous run before continuing.
Plotting Results
Two scripts are provided for generating figures from experiment results.
Summary Bar Charts (summarize.py)
Generates accuracy bar charts comparing all methods for a given benchmark:
python3 summarize.py --datasetname <task_name>Options:
| Flag | Description |
|---|---|
--datasetname | Dataset subdirectory under results/ (required) |
--openai-only | Only include OpenAI models (gpt-*, o1-*, o3-*) |
--split-models | Generate a separate figure for each model |
Reads results from results/<task_name>/ and saves to figures/<task_name>_summary.png.
Accuracy Curves & Memory Cost (plot_process.py)
Generates cumulative accuracy curves and memory storage cost plots over the problem sequence:
python3 plot_process.py --datasetname <task_name>| Flag | Description |
|---|---|
--datasetname | Dataset subdirectory under results/ (required) |
Saves two figures:
figures/<task_name>_accuracy_curve.png— cumulative accuracy over samples seenfigures/<task_name>_memory_cost.png— cheatsheet/ledger size (KB) over questions asked (only for methods with non-empty memory stores)