Final Report
Dynamic Ledger: Retrieval-Augmented Structured Memory for Test-Time Learning
Stanford CS224N Custom Project · PDF
Jerry Gu, Shurui Liu, Sabrina Yen-Ko — Stanford University
Mentored by Mirac Suzgun
Abstract
While modern language models excel at many complex tasks, they lack a persistent, adaptable memory to learn new problem-solving strategies during test-time. We introduce two extensions to the original Dynamic Cheatsheet framework (Suzgun et al.): Strategic Chunk Retrieval (SCR) and Dynamic Ledger (DL). SCR replaces the monolithic cheatsheet with a structured, chunk-level memory store where each entry is an independently retrievable strategy unit, combating strategy dilution and irrelevant-context contamination that arise when the cheatsheet is scaled. DL converts this memory store into a structured database with CRUD operations and dual-retrieval on both the strategy and originating problem embedding. We evaluate both extensions on GPT-4o (and GPT-5) across 4 benchmarks — AIME 2020–2024, MathEquationBalancer, IneqMath, and DataSIR — and find that both DL and SCR with top-k=3 selection consistently improve over all baselines, with the largest gains on math-intensive tasks where strategy reuse is most beneficial. Finally, a sensitivity analysis confirms that reasoning performance degrades significantly under strategy dilution, empirically validating the necessity of our selective curation approach.
Introduction
Large language models (LLMs) have demonstrated impressive reasoning capabilities across mathematics, science, and programming benchmarks, yet they remain fundamentally stateless at inference time: every new problem is solved from scratch, discarding hard-won insights from prior queries. This contrasts sharply with human problem-solving, where accumulated experience and learned heuristics dramatically accelerate performance on unfamiliar but structurally related problems.
The Dynamic Cheatsheet (DC) framework addresses this gap by endowing black-box LLMs with a persistent, self-curated memory that grows during inference. A generator solves each current problem using the cheatsheet, and a curator updates it from the experience. Two main variants exist: DC-Cu (cumulative), which appends all experience sequentially, and DC-RS (retrieval synthesis), which retrieves similar past problems and synthesizes a query-specific cheatsheet before generation. Both substantially outperform stateless baselines on mathematical and scientific reasoning tasks.
Despite these gains, DC has two notable limitations. First, the cheatsheet is maintained as a monolithic text artifact: the curator must reconcile all stored strategies in each single pass, which can dilute task-specific strategies and bury relevant knowledge under irrelevant content as the cheatsheet grows — an instance of the "lost in the middle" effect. Second, retrieval in DC-RS is quality-agnostic: incorrect past solutions are treated identically to correct ones during retrieval, allowing confidently wrong examples to mislead the generator.
We propose two targeted extensions:
- Strategic Chunk Retrieval replaces the monolithic cheatsheet with a structured, chunk-level memory store of self-contained strategy units, retrieved by content similarity and updated selectively — leaving unrelated strategies untouched.
- Dynamic Ledger reframes this store as a lightweight database supporting explicit CRUD operations and dual-embedding retrieval over both strategy text and source-problem embeddings, recovering relevant entries that strategy-only retrieval misses.
We additionally explore Confidence-Weighted Retrieval, which re-ranks retrieved examples by an ensemble-based trust score, filtering low-confidence results.
Approach
Baseline: Dynamic Cheatsheet with Retrieval
Our work builds on the DC framework. We extend DC-RS with Confidence-Weighted Retrieval and DC-Cu with Strategic Chunk Retrieval, and evaluate against the baselines DC-∅ (no cheatsheet), DC-Cu, and DC-RS on GPT-4o.
For the n-th question, DC-RS retrieves the top-k most similar past Q&A pairs by cosine similarity on embeddings, then constructs a cheatsheet from the retrieved input–output pairs via a separate curator LLM call.
Confidence-Weighted Retrieval
A core limitation of similarity-only retrieval is that incorrect solutions are treated identically to correct ones. We explore a confidence-weighted re-ranking scheme that augments retrieval with a trust score derived without ground-truth labels.
We sample N additional independent responses at varying temperatures {0.7, 0.8, 0.9} after generating the primary answer. The trust score is the agreement ratio among extracted answers. High agreement across temperatures indicates a stable, reliable response. We replace similarity-only ranking with a weighted combination of cosine similarity and trust score, excluding any example with trust score < 0.5 from the candidate pool.
Strategic Chunk Retrieval
We propose Strategic Chunk Retrieval, a memory architecture that replaces the monolithic cheatsheet with a structured, chunk-level memory store and retrieves items based on their full strategy content rather than only their source question.
Each entry in the store is a single <memory_item>: a self-contained strategy, code snippet, or insight. Every item carries an embedding of the strategy text itself and a usage counter. Given a new input, we score every memory item using a blended score combining cosine similarity (α=0.85) with a logarithmic usage bonus (1−α). The curator receives only the retrieved chunks, not the full store, and produces updated <memory_item> blocks. Non-retrieved items remain untouched.
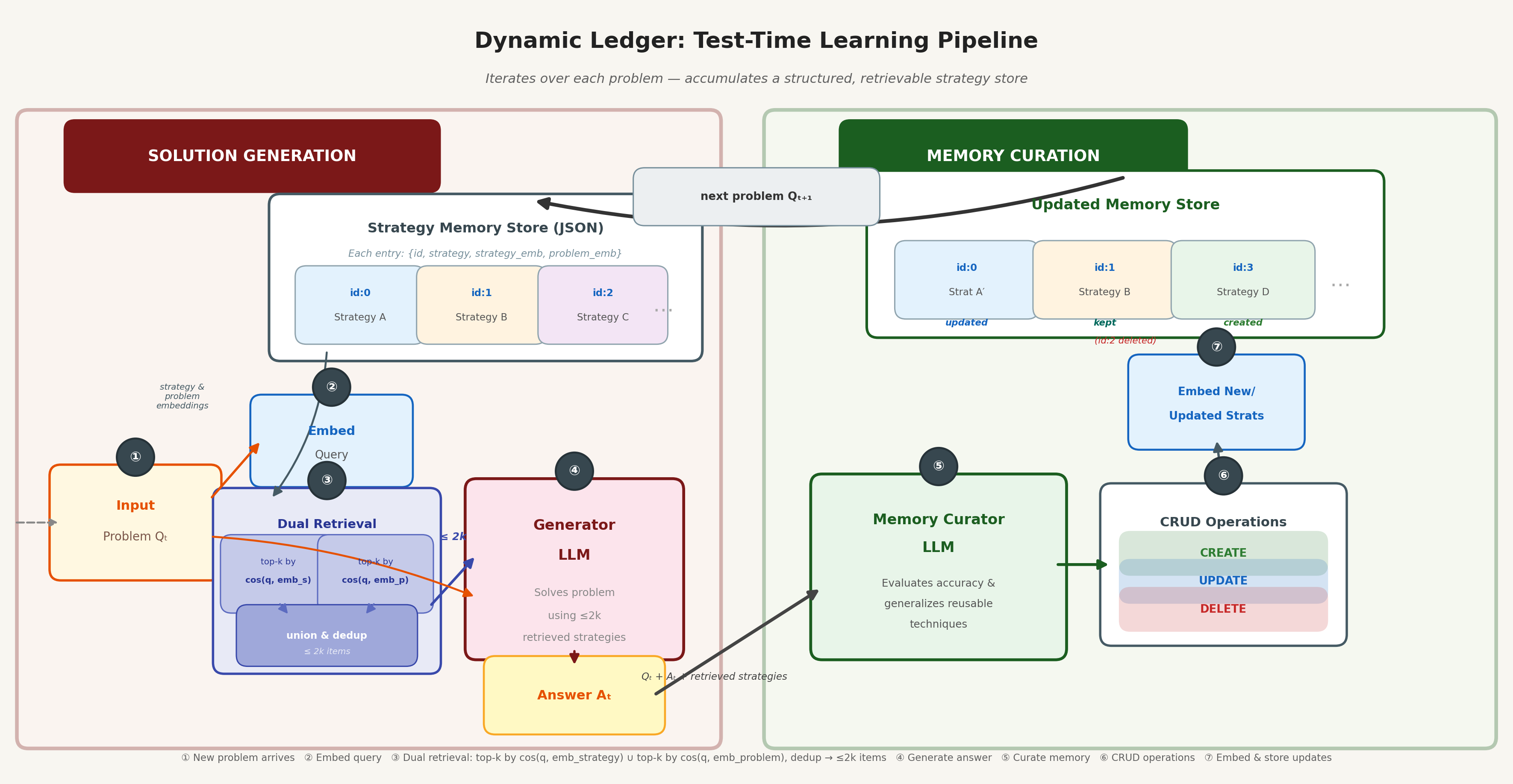
Dynamic Ledger
Strategic Chunk Retrieval has two remaining limitations: its document-centric curation model rewrites retrieved items as a batch, and retrieval only matches on strategy content. Dynamic Ledger addresses both by reframing the cheatsheet as a lightweight database with explicit CRUD operations and dual-embedding retrieval.
Each entry carries a unique identifier, strategy text, an example of the originating problem, a strategy embedding, and a source-problem embedding. Dual-embedding retrieval operates along both axes independently — retrieving by problem similarity and strategy similarity — then returns the deduplicated union, yielding at most 2k items. The curator emits a structured JSON array of atomic Create, Update, and Delete operations, giving fine-grained, auditable control over each record.
Experiments
Benchmarks
We evaluate on four benchmarks spanning different reasoning modalities:
- AIME 2020–2024 (133 problems): AMC/AIME competition math problems requiring a single integer answer.
- IneqMath (100 problems): An inequality-proof benchmark requiring formal mathematical reasoning.
- MathEquationBalancer (250 problems): Chemical equation balancing tasks with exact numerical coefficient answers.
- DataSIR (1,647,501 problems total; 400-problem subset
DataSIR400used in evaluation): Sensitive information recognition testing pattern-matching and structured data analysis.
Experimental Details
All primary experiments use GPT-4o as both the generator and curator, with temperature 0.0 and a maximum of 4,096 output tokens. DataSIR is evaluated on GPT-5. Embeddings are pre-computed using OpenAI's text-embedding-3-small (d=1,536). We use top-k=3 retrieval for all retrieval-based methods.
Results
| Method | AIME (133, 4o) | IneqMath (100, 4o) | MathEqBal (250, 4o) | DataSIR400 (400, 5) |
|---|---|---|---|---|
| Baseline / Default | 9.8% | 48.0% | 47.2% | 87.0% |
| EmptyCheatsheet | 24.1% | — | 83.2% | — |
| DC-Cu | 18.0% | 47.0% | 94.4% | 84.0% |
| FullHistoryAppend | — | — | — | 88.0% |
| Dynamic Retrieval | 24.1% | — | 94.4% | — |
| DC-RS | 24.8% | 47.0% | 94.0% | 87.0% |
| DC-SCR (ours) | 28.2% | 53.0% | 100.0% | 75.0% |
| DC-SCR p=0.8 (ours) | 20.6% | 49.0% | — | — |
| DC-DL (ours) | 30.8% | 58.0% | 100.0% | 91.0% |
Dynamic Ledger consistently achieves the highest accuracy, with the largest gains on math-intensive tasks where strategy reuse is most beneficial.
Analysis
When Does Structured Memory Help?
Structured memory provides the largest gains on tasks with high strategy transferability: AIME (competition math with recurring techniques), IneqMath (inequality proofs with reusable bounding strategies), and MathEquationBalancer (systematic coefficient-solving procedures). On these tasks, DC-DL improves over the best baseline by 6.0–10.0 pp.
Conversely, on DataSIR, gains are more modest (+4.0 pp over Default), and DC-SCR actually degrades performance. On MMLU-Pro Engineering and Physics — knowledge-recall benchmarks where problems are largely independent — our methods do not outperform DC baselines, confirming that Dynamic Ledger is most effective when the task distribution contains recurring, transferable problem-solving patterns.
Impact of Strategy Dilution
Three lines of evidence support the importance of selective curation:
-
Top-k versus probability threshold: The 7.6 pp gap on AIME and 4.0 pp gap on IneqMath between top-k (k=3) and the probability-threshold variant (p=0.8) shows that indiscriminate retrieval actively harms reasoning.
-
Monolithic versus selective curation: DC-Cu starts strong but gradually converges toward the Default as curation noise accumulates, while DC-DL maintains its advantage throughout the sequence.
-
Oracle-memory sensitivity analysis: Injecting n=50 distractors alongside a gold strategy degrades accuracy by 29.8%, establishing a concrete empirical upper bound on distractor tolerance.
Conclusion
We introduced Strategic Chunk Retrieval and Dynamic Ledger, two extensions to the Dynamic Cheatsheet framework that replace monolithic memory with structured, chunk-level stores and selective curation. Dynamic Ledger further incorporates dual-embedding retrieval and explicit CRUD operations for fine-grained memory management.
Across four benchmarks, Dynamic Ledger consistently achieves the best accuracy: +6.0 pp on AIME 2020–2024 and +10.0 pp on IneqMath over the strongest baselines, and perfect accuracy on MathEquationBalancer. These improvements stem from two complementary mechanisms: (1) selective curation that limits information loss, preventing strategy dilution as the store grows; and (2) dual-embedding retrieval that surfaces relevant strategies even when the current problem and stored entry share no surface-level similarity.
A clear boundary condition emerges from our MMLU-Pro evaluation: on knowledge-recall tasks where problems test factual memory rather than transferable strategies, the overhead of strategy extraction outweighs its benefits. Automatically detecting low-transferability regimes at inference time and falling back to a lighter retrieval mode remains an important open direction.
Confidence-Weighted Retrieval did not independently improve over DC baselines, likely because its trust signal is most valuable when the retrieved pool already contains high-quality candidates. However, it is architecturally orthogonal to both SCR and Dynamic Ledger, making integration as a re-ranking layer a natural next step.
In future work, we will use stronger embedding models or train an RL model to embed memories based on strategic similarities, and improve memory storage efficiency.
Team Contributions
All authors contributed equally; names in alphabetical order.
Jerry Gu led the implementation of novel cheatsheet approaches (Strategic Chunk Retrieval and Dynamic Ledger) and the project's fundraising efforts. Additionally contributed to experiments, result analysis, dataset adaptation, and writing the final report.
Shurui Liu led the execution of experiments, result analysis, codebase management, website development, and writing of the final report. Also led the formalization of DC using probability and information theory, and adaptation of the IneqMath and DataSIR datasets, while contributing to the Dynamic Ledger implementation and confidence score investigations.
Sabrina Yen-Ko led the ablation and sensitivity analysis, qualitative result analysis, and the implementation of confidence scores using ensembling methods. Also contributed to conducting experiments, analyzing results, and writing the final report.
Acknowledgment: The authors gratefully acknowledge the generous support of Y Combinator, OpenAI, and xAI. This research was made possible by $2,500 in OpenAI credits provided through the YC AI Stack and $2,500 in Grok API credits via xAI's YC Students Program.