Results
Experimental Results
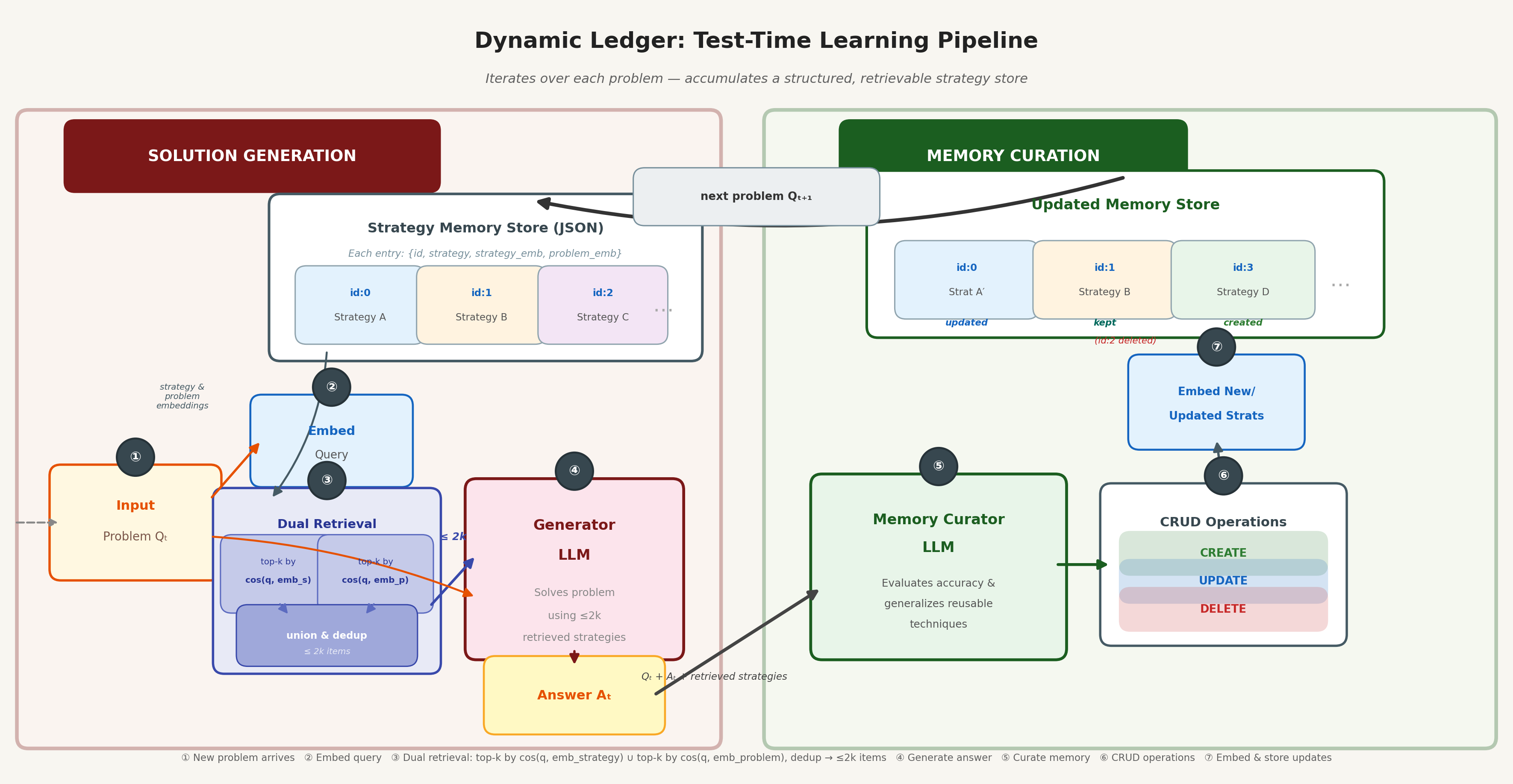
System Illustration
Main Results
We evaluate on four benchmarks spanning different reasoning modalities. The first three benchmarks use GPT-4o; DataSIR uses GPT-5. Dynamic Ledger (DC-DL) achieves the highest accuracy on all four tasks.
| Method | AIME (133, 4o) | IneqMath (100, 4o) | MathEqBal (250, 4o) | DataSIR400 (400, 5) |
|---|---|---|---|---|
| Baseline / Default | 9.8% | 48.0% | 47.2% | 87.0% |
| EmptyCheatsheet | 24.1% | — | 83.2% | — |
| DC-Cu | 18.0% | 47.0% | 94.4% | 84.0% |
| FullHistoryAppend | — | — | — | 88.0% |
| Dynamic Retrieval | 24.1% | — | 94.4% | — |
| DC-RS | 24.8% | 47.0% | 94.0% | 87.0% |
| DC-SCR (ours) | 28.2% | 53.0% | 100.0% | 75.0% |
| DC-SCR p=0.8 (ours) | 20.6% | 49.0% | — | — |
| DC-DL (ours) | 30.8% | 58.0% | 100.0% | 91.0% |
Benchmark Summaries
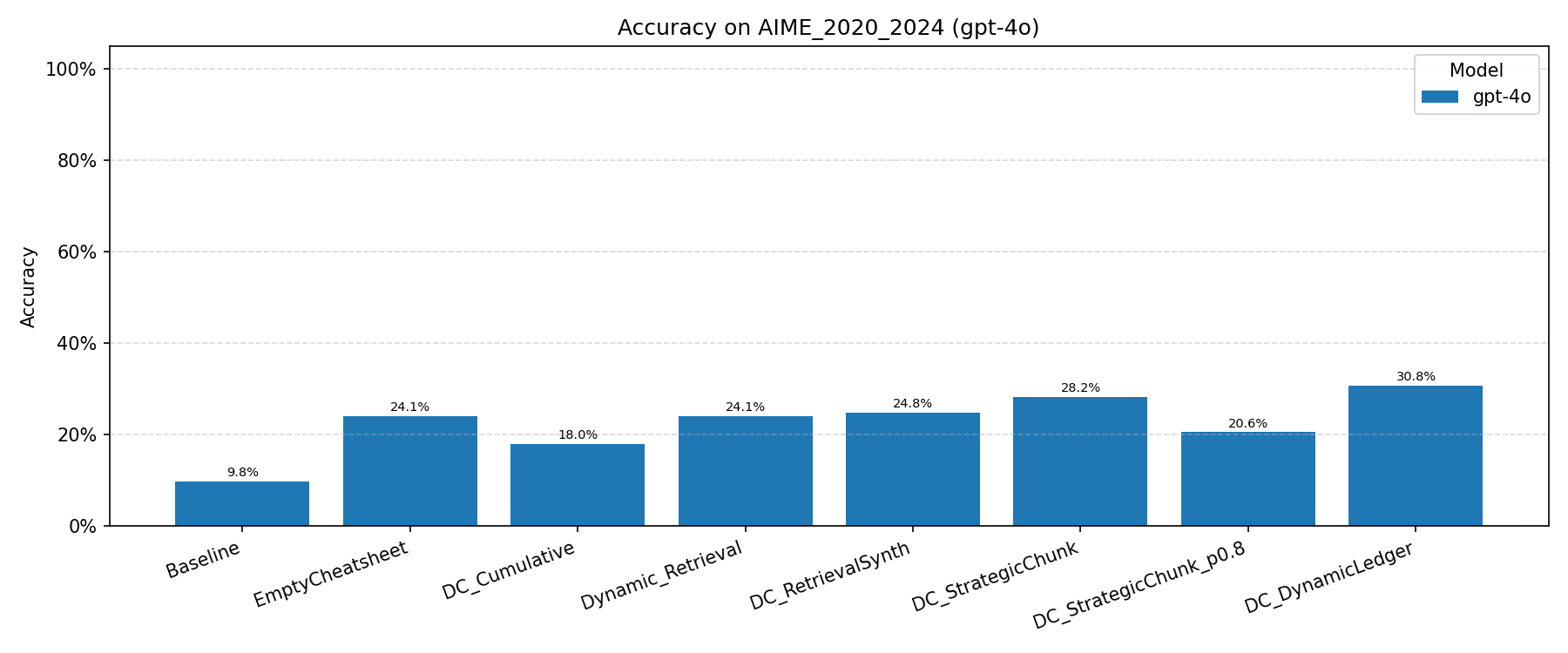
AIME 2020–2024 (GPT-4o)
DC-DL achieves 30.8%, a 3.1× improvement over the stateless Baseline (9.8%) and a 6.0 pp gain over DC-RS (24.8%). DC-SCR (28.2%) also surpasses all baselines. The probability-threshold variant DC-SCR p=0.8 (20.6%) underperforms the top-k variant, suggesting that adaptive cardinality introduces too many marginally relevant chunks.
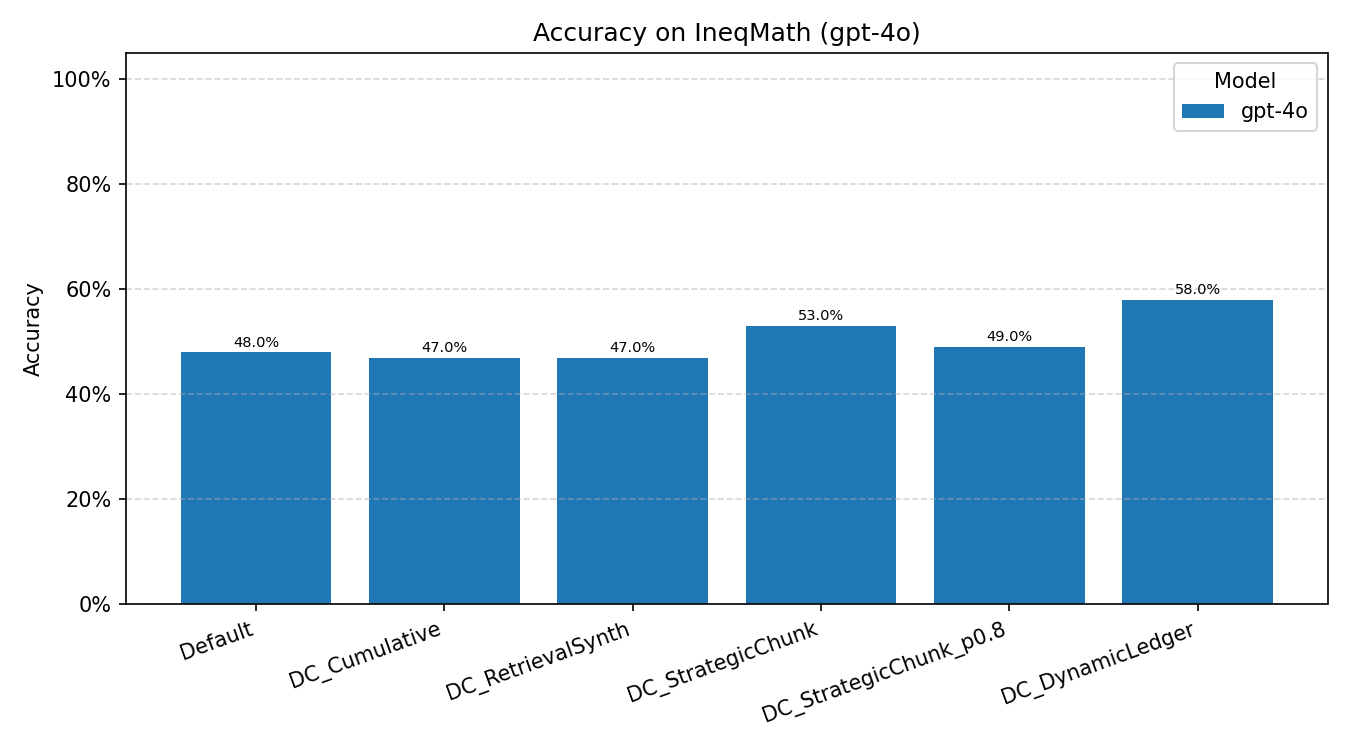
IneqMath (GPT-4o)
DC-DL leads at 58.0%, a 10 pp gain over the Default baseline (48.0%). DC-Cu and DC-RS both underperform the Default (47.0% each), indicating that monolithic curation offers no benefit on inequality proof tasks. The strong performance of chunk-based methods suggests that fine-grained strategy retrieval is particularly advantageous when problems require diverse, specialized proof techniques.
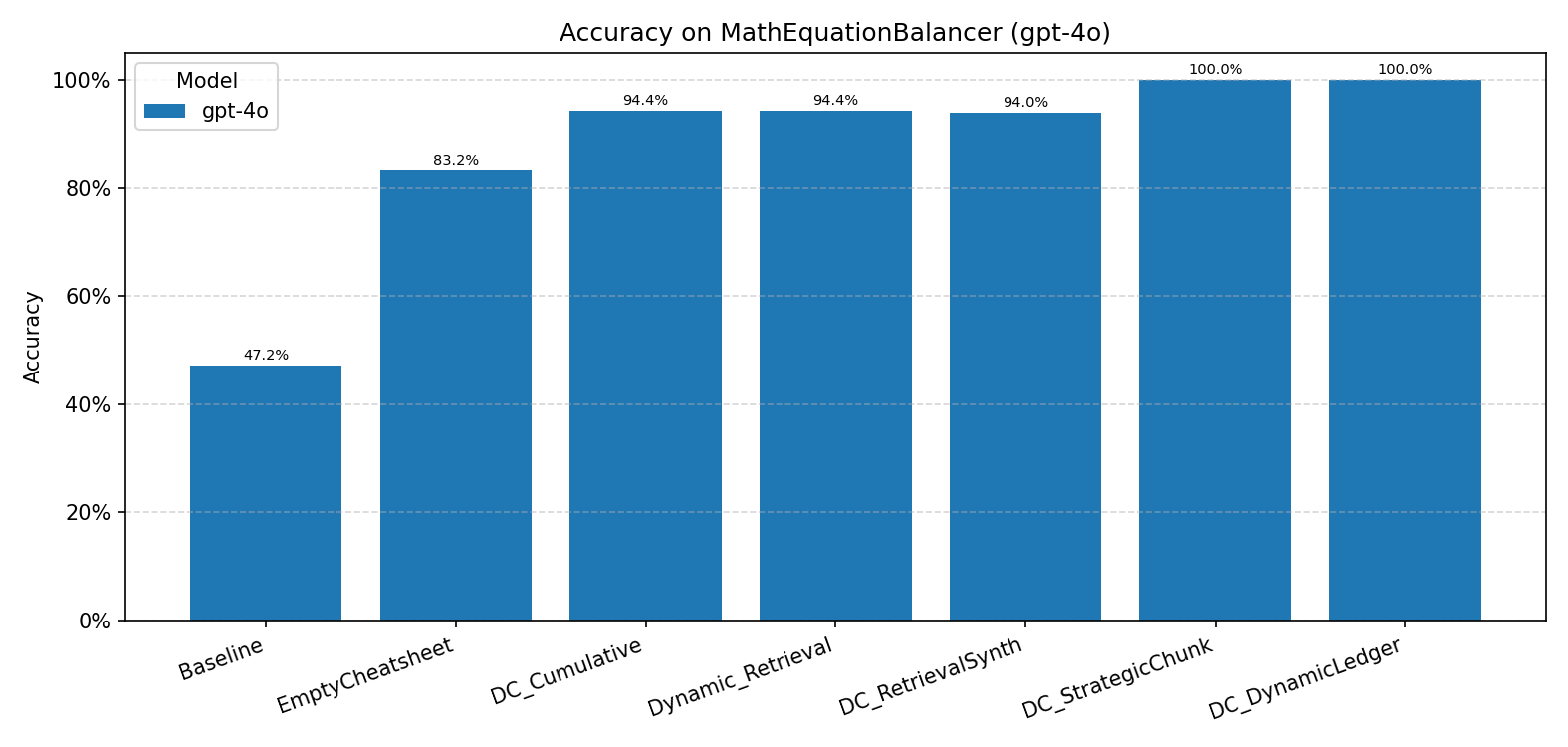
MathEquationBalancer (GPT-4o)
Both DC-SCR and DC-DL achieve perfect accuracy (100.0%), a dramatic improvement over the 47.2% Baseline. The large jump from Baseline to EmptyCheatsheet (83.2%) indicates that even a minimal structured prompt substantially helps. Prior DC variants plateau around 94%, unable to close the remaining gap.
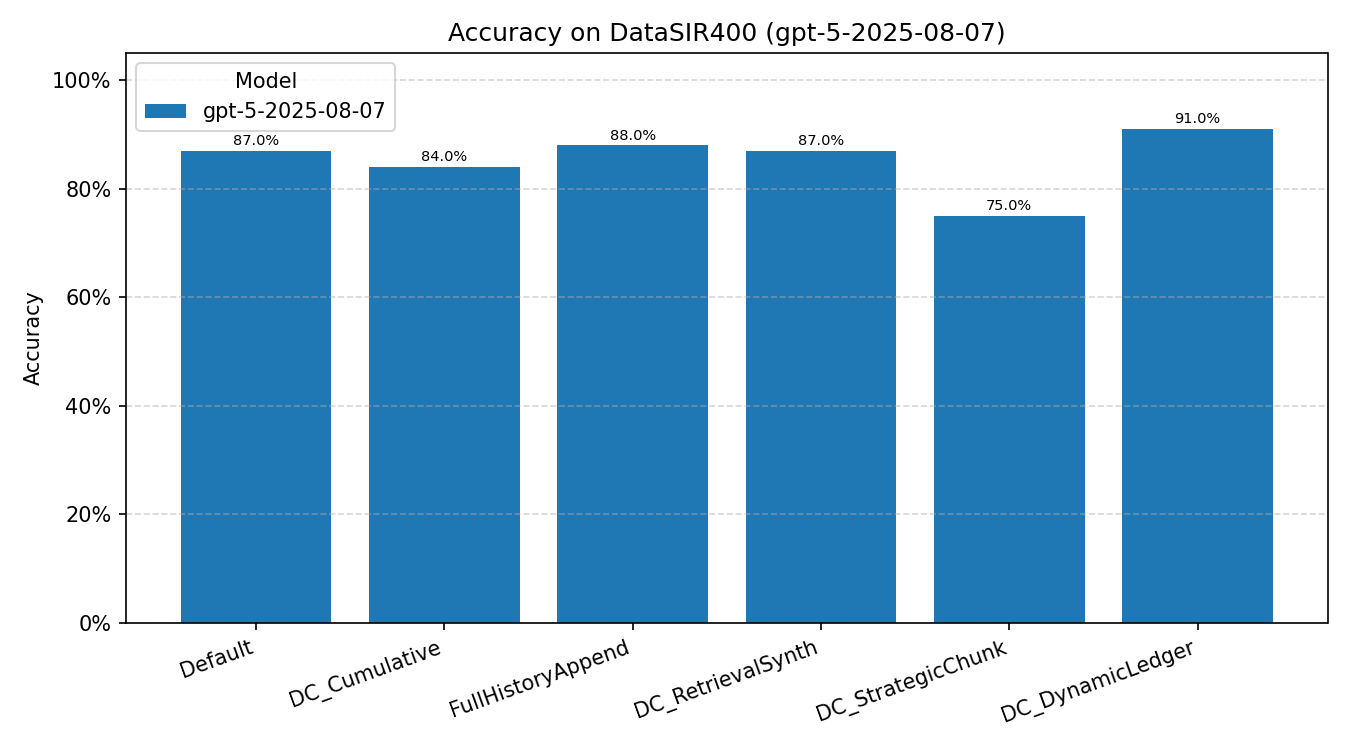
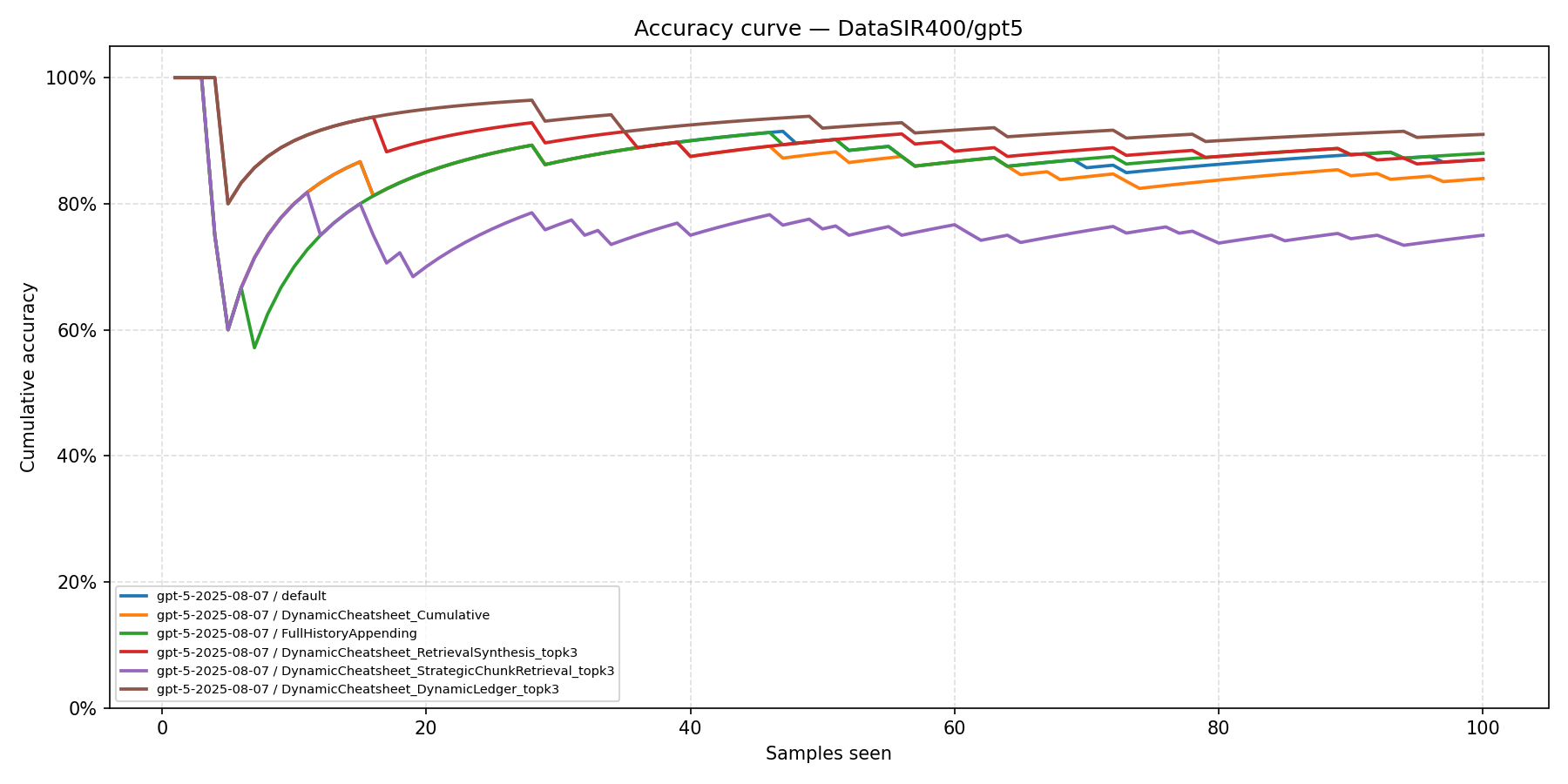
DataSIR (GPT-5)
DC-DL achieves 91.0%, outperforming all methods. However, DC-SCR drops to 75.0%, well below the Default (87.0%). This reversal highlights the importance of dual-embedding retrieval: when strategy text alone does not capture structural similarity between problems, the problem-embedding channel in DC-DL compensates.
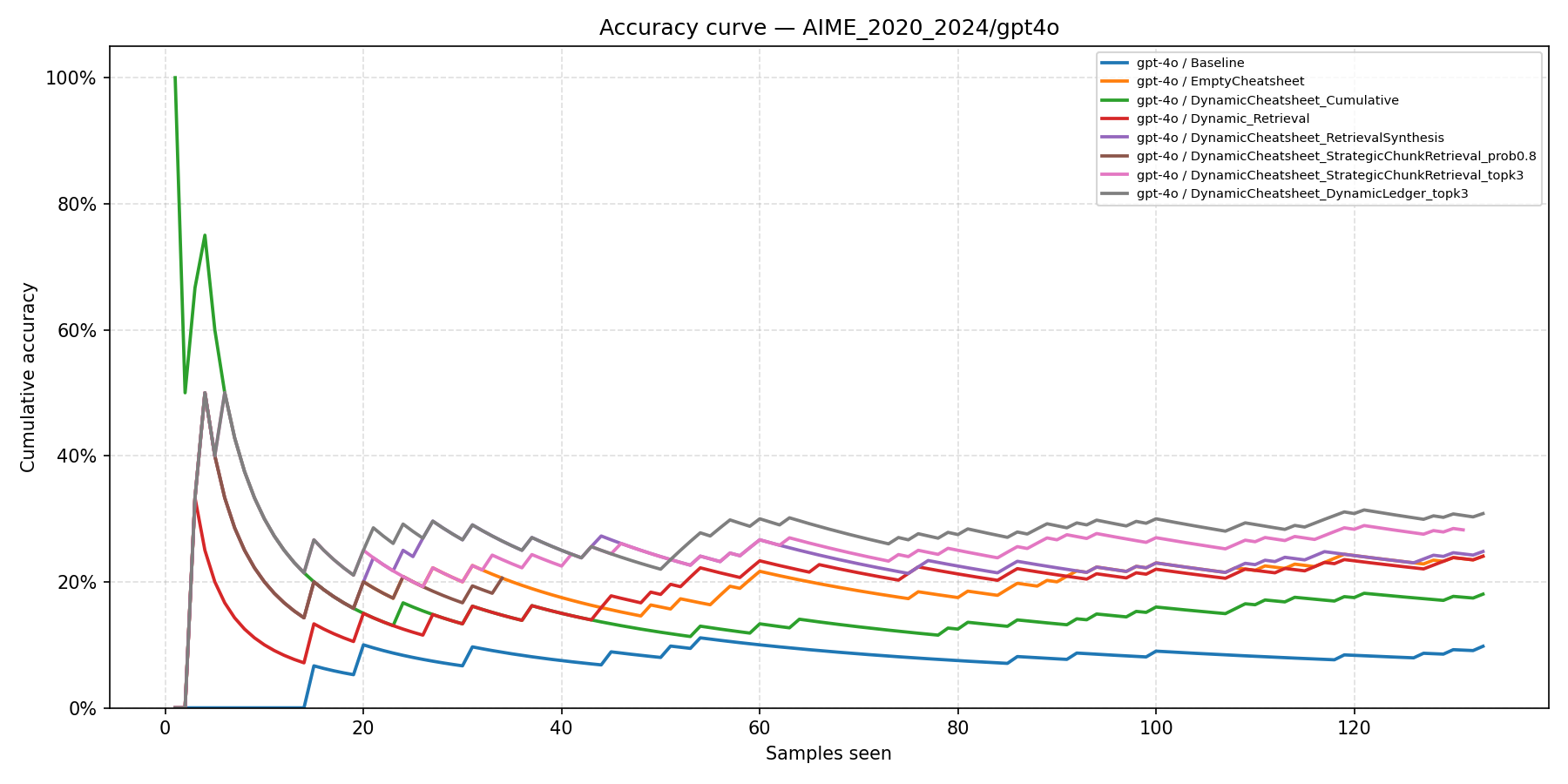
Cumulative Learning Curves
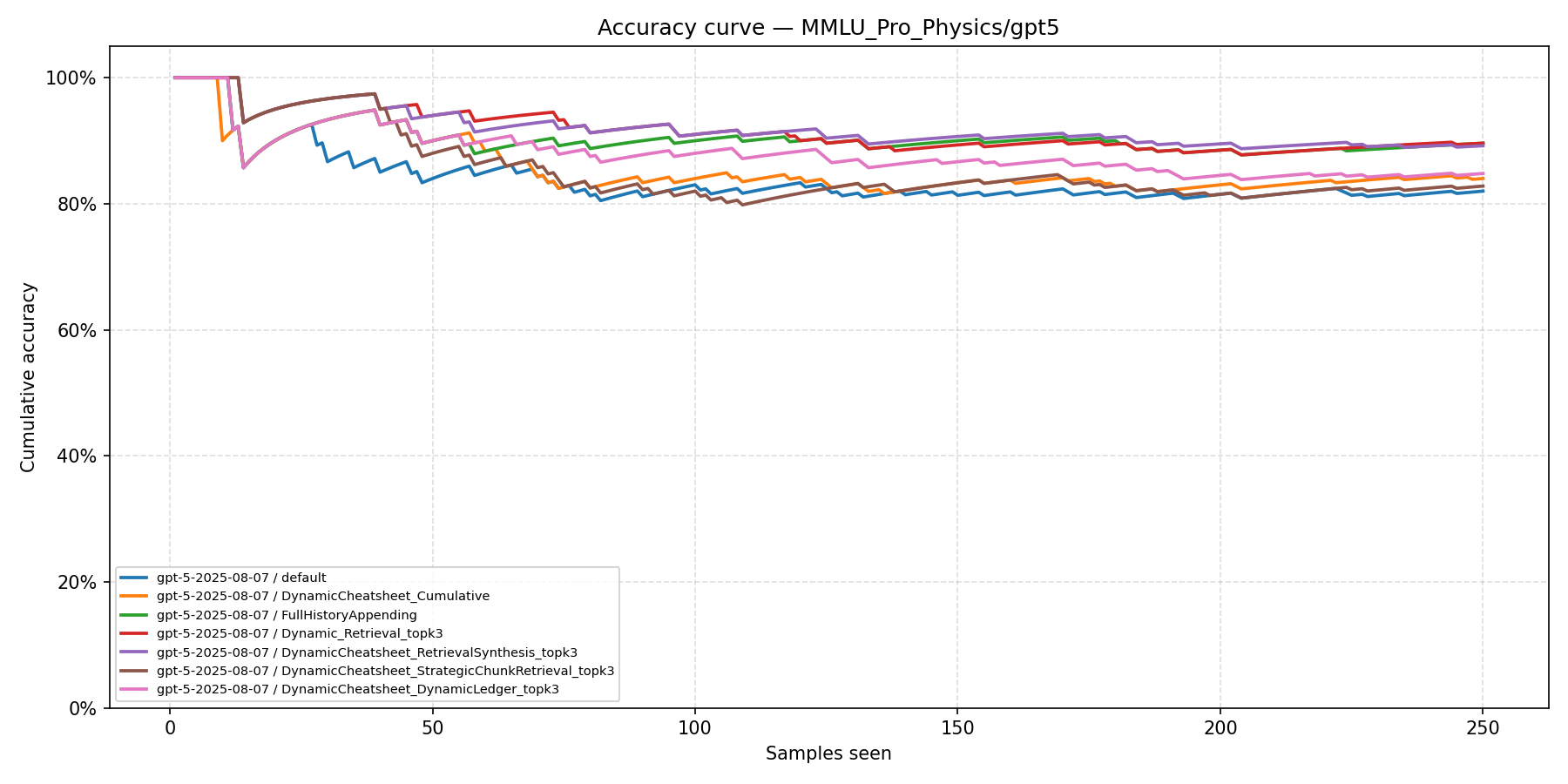
These plots show cumulative accuracy as a function of problems seen, revealing the test-time learning dynamics of each method. DC-DL consistently maintains the highest cumulative accuracy after an initial learning phase.
AIME 2020–2024
The Baseline flatlines near 10% while DC-DL and DC-SCR separate from DC baselines around problem 40 and maintain a widening gap.
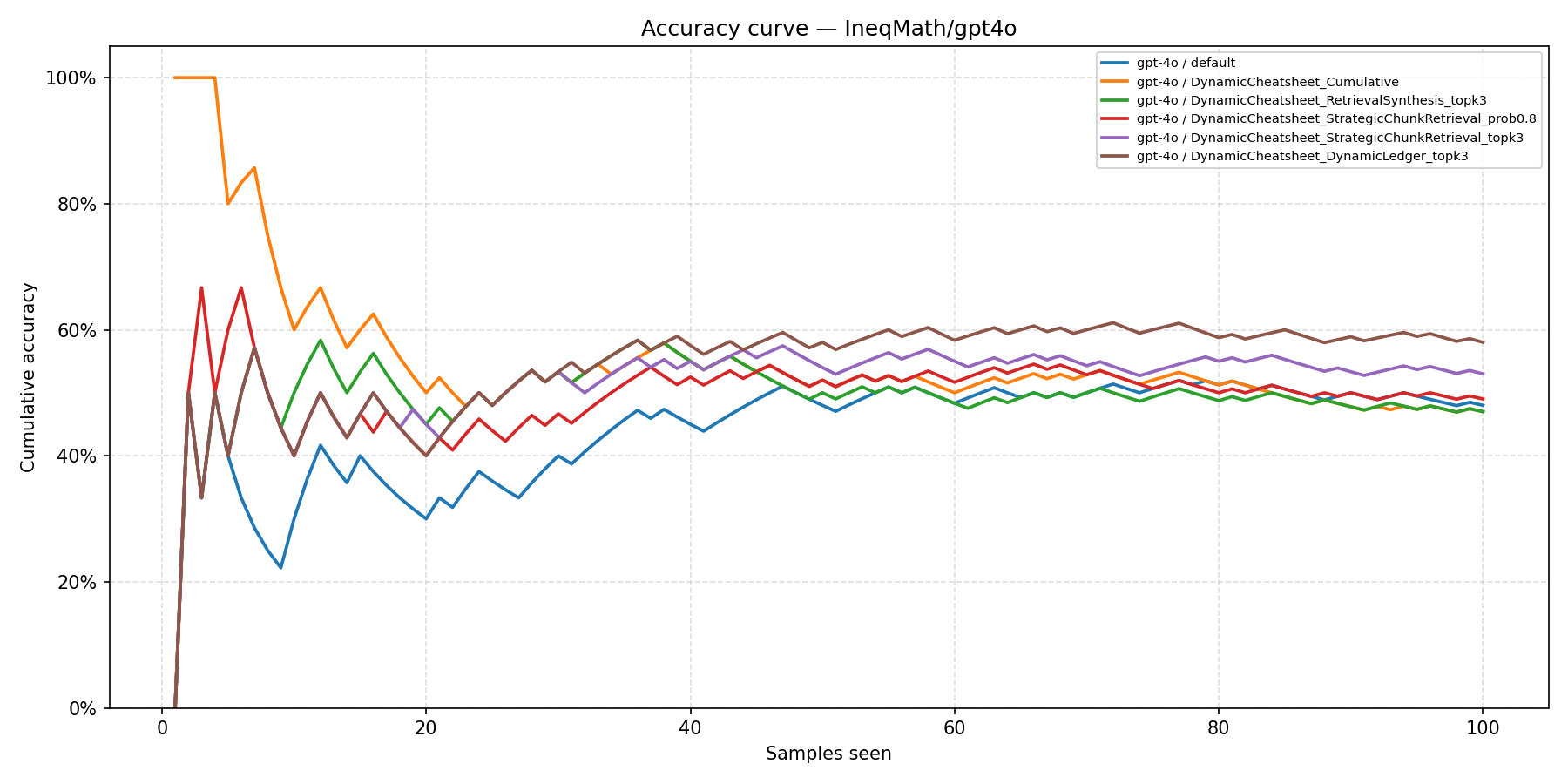
IneqMath
DC-Cu starts strong but gradually converges toward the Default as curation noise accumulates, while DC-DL maintains its advantage throughout the sequence.
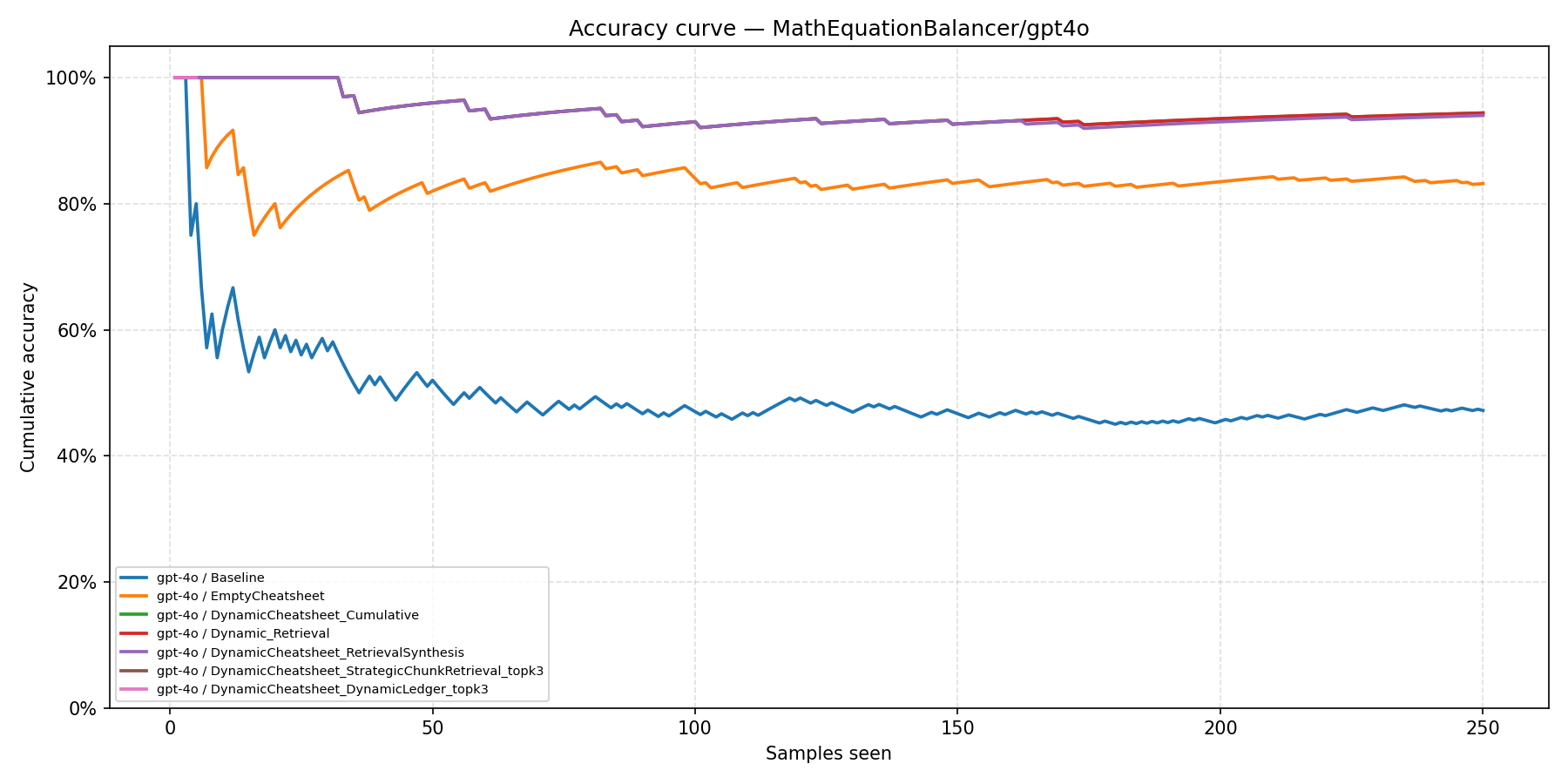
MathEquationBalancer
DC-SCR and DC-DL reach near-perfect accuracy within the first 20 problems, while DC-Cu and DC-RS plateau near ~94% and the Baseline stalls at ~47%.
DataSIR
DC-SCR remains below all methods throughout, while DC-DL climbs to the top by problem 30, confirming that dual-embedding retrieval is decisive when strategy text alone is a poor retrieval signal.
Sensitivity Analysis: Strategy Dilution
To isolate the impact of contextual interference, we conduct a controlled sensitivity analysis on AIME 2021–2025 using an oracle retrieval protocol: the generator is provided with exactly one "gold" memory item (the correct strategy), plus a varying number of distractor strategies from unrelated problems.
| Configuration | Distractors (n) | Accuracy (%) | Relative Decay |
|---|---|---|---|
| Oracle Strategy | 0 | 22.5% | — |
| Low Distraction | 10 | 19.2% | −14.7% |
| High Distraction | 50 | 15.8% | −29.8% |
Accuracy exhibits consistent decay as distractors increase, establishing a concrete empirical upper bound on distractor tolerance and validating the necessity of selective curation.
Limitation Analysis: MMLU-Pro
To probe the limits of our approach, we evaluate on two MMLU-Pro subsets — Engineering and Physics — each containing 250 multiple-choice questions drawn from graduate-level professional exams. Unlike AIME or IneqMath, these questions primarily test domain knowledge and factual recall rather than transferable problem-solving strategies.
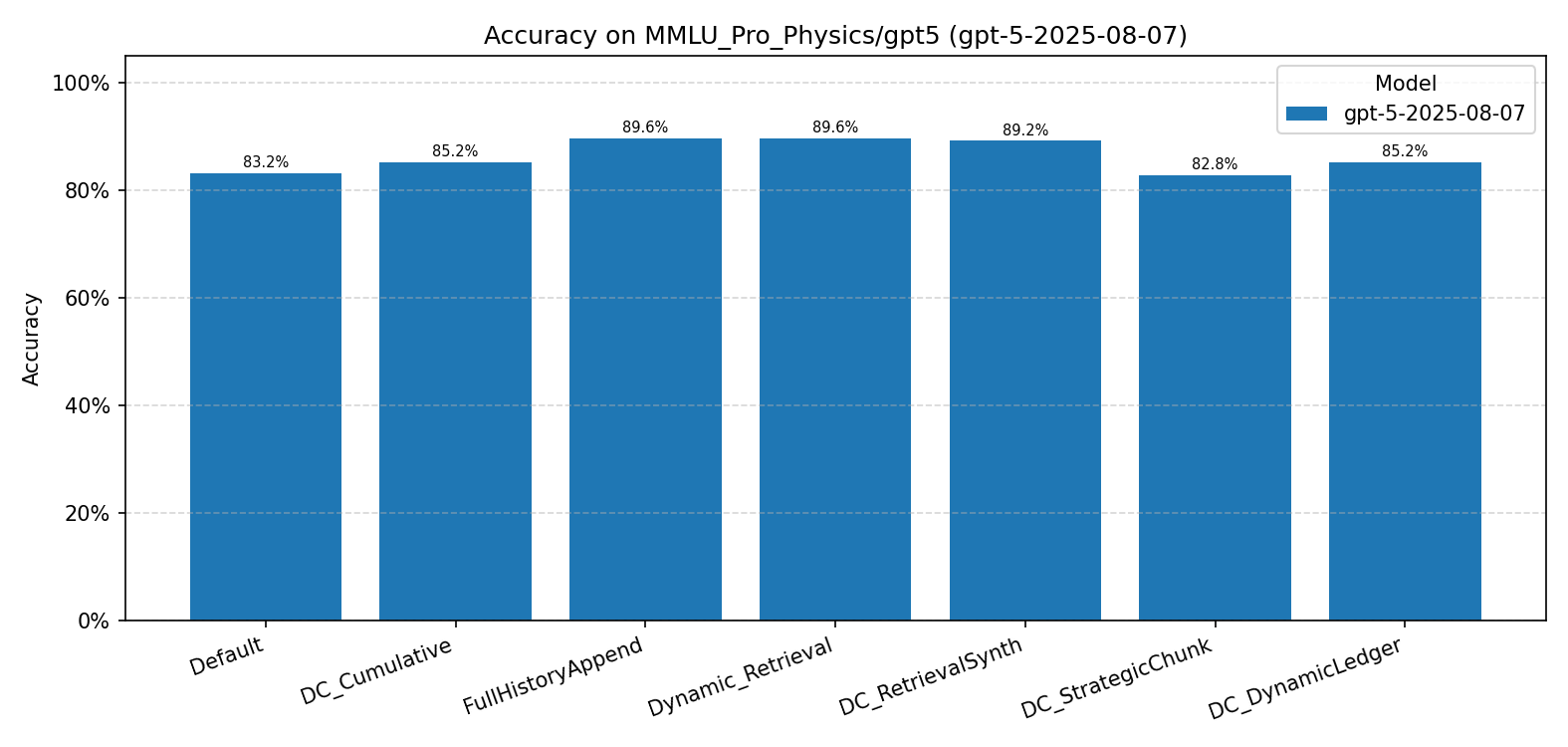
| Method | Eng. (GPT-4o) | Eng. (GPT-5) | Phys. (GPT-4o) | Phys. (GPT-5) |
|---|---|---|---|---|
| Default / Baseline | 53.6% | 64.8% | 76.0% | 83.2% |
| EmptyCheatsheet | 52.8% | — | 75.2% | — |
| DC-Cu | 46.1% | 63.6% | 76.0% | 85.2% |
| FullHistoryAppend | — | 72.0% | — | 89.6% |
| Dynamic Retrieval | 48.8% | 72.0% | — | 89.6% |
| DC-RS | 51.6% | 72.4% | 75.6% | 89.2% |
| DC-SCR (ours) | 53.6% | 66.8% | 73.2%† | 82.8%† |
| DC-DL (ours) | 51.6% | 67.2% | 72.0%† | 85.2% |
† Below the Default baseline.
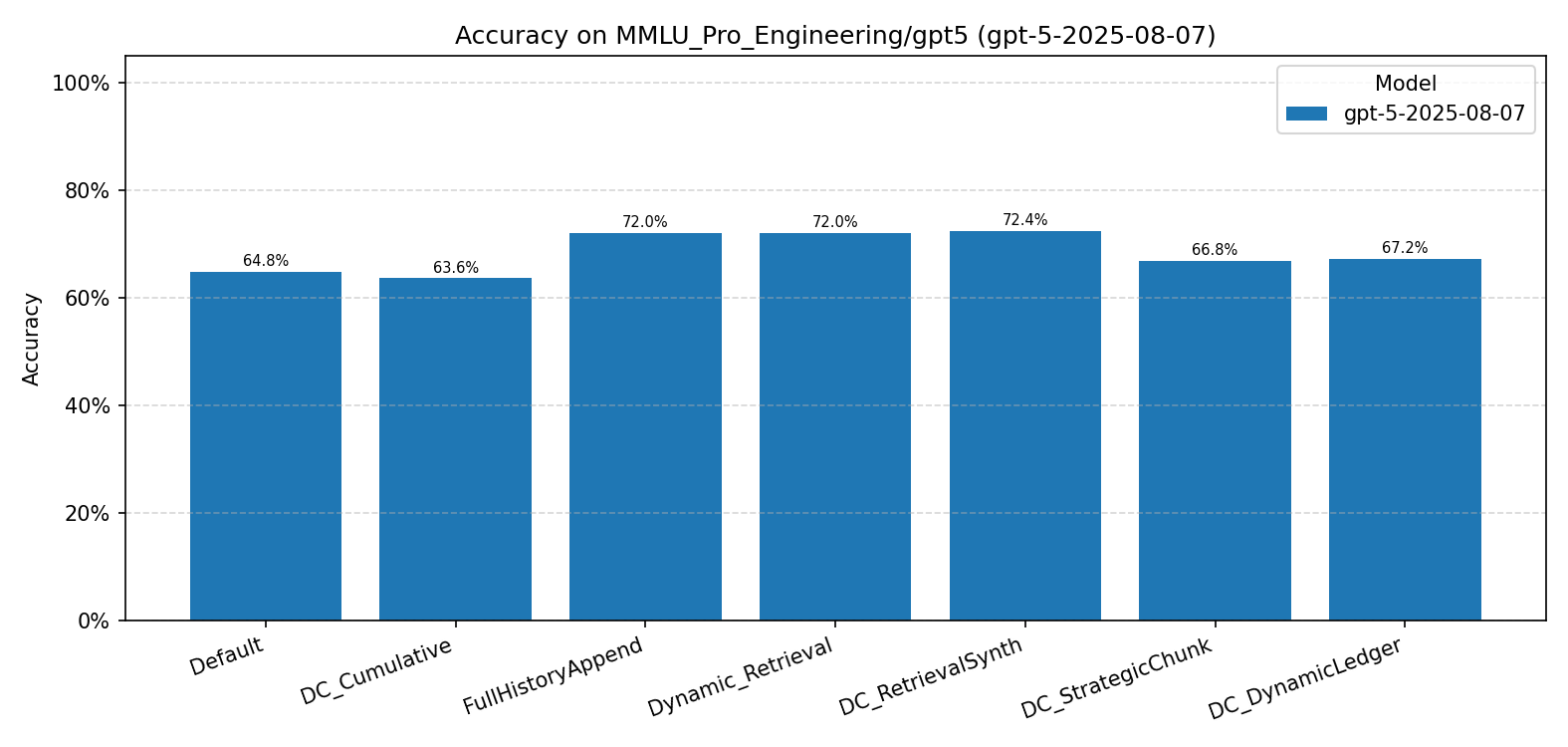
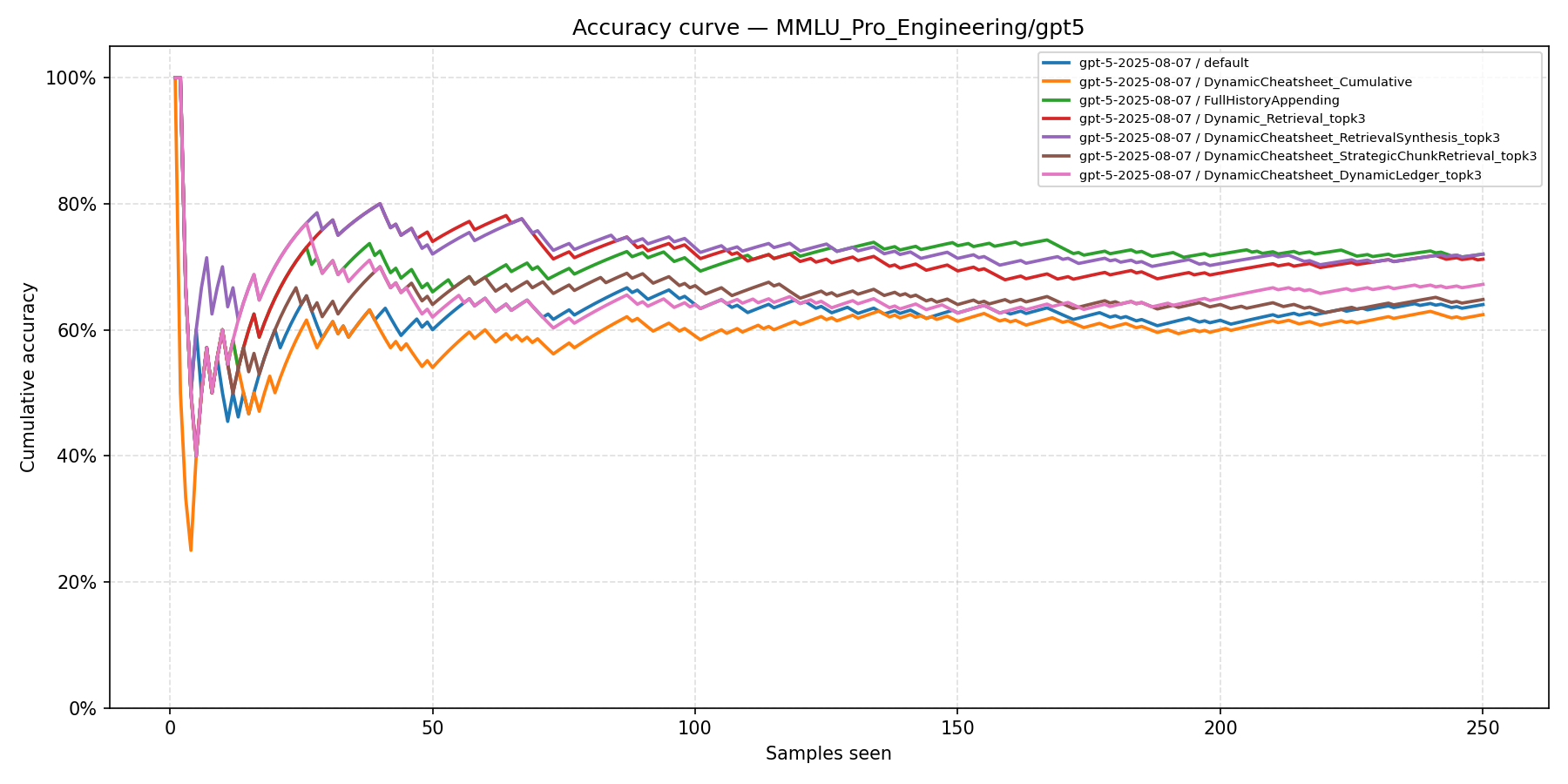
MMLU-Pro Engineering (GPT-5)
MMLU-Pro Physics (GPT-5)
Key Takeaways
- Our methods do not outperform DC baselines on knowledge-recall tasks. DC-RS reaches 72.4% on GPT-5 Engineering while DC-DL achieves only 67.2%.
- Simple retrieval methods dominate. FullHistoryAppend and Dynamic Retrieval (72.0% / 89.6% on GPT-5) outperform all structured-memory methods, suggesting that raw past examples help more than distilled strategies on factual tasks.
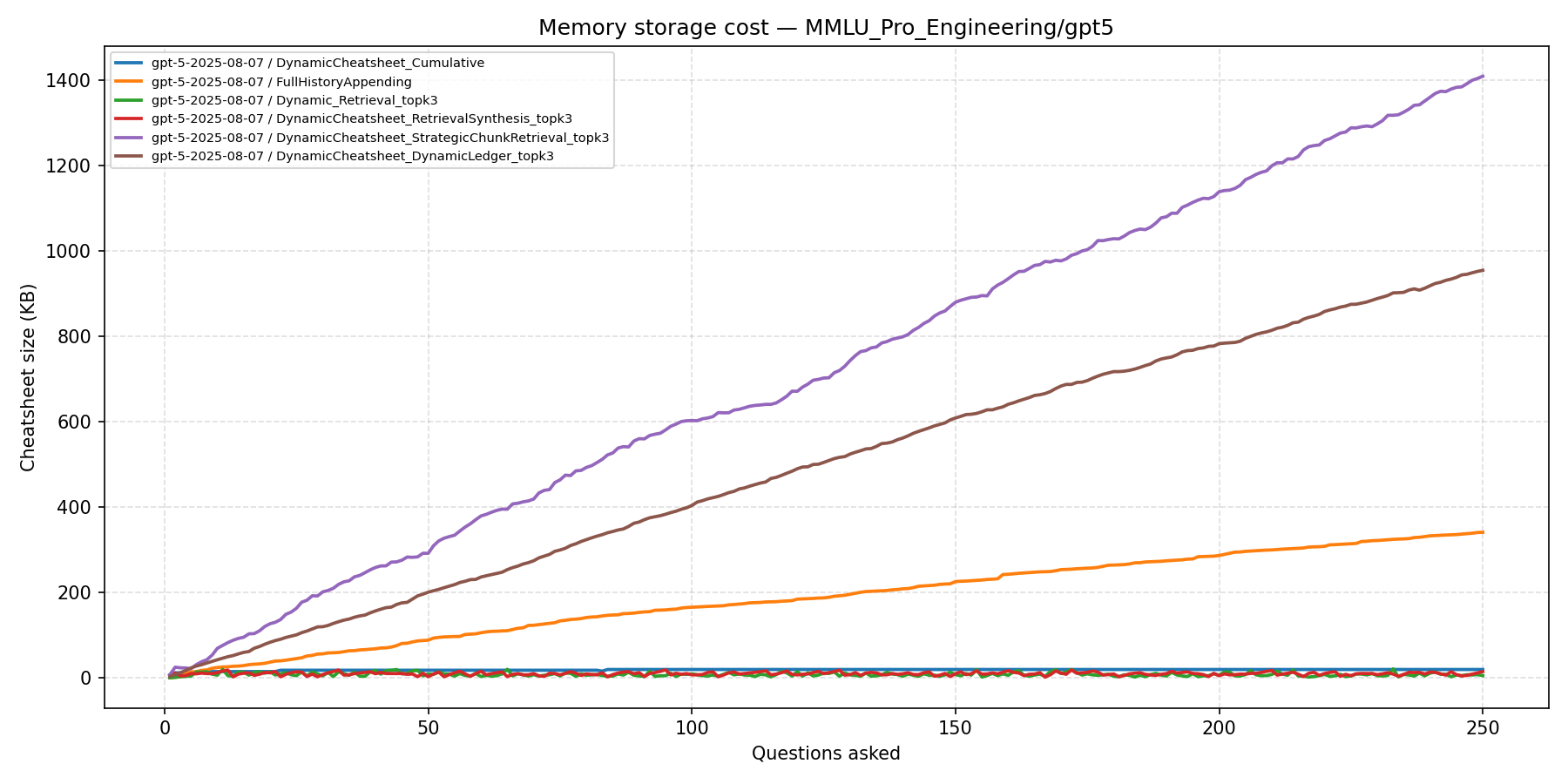
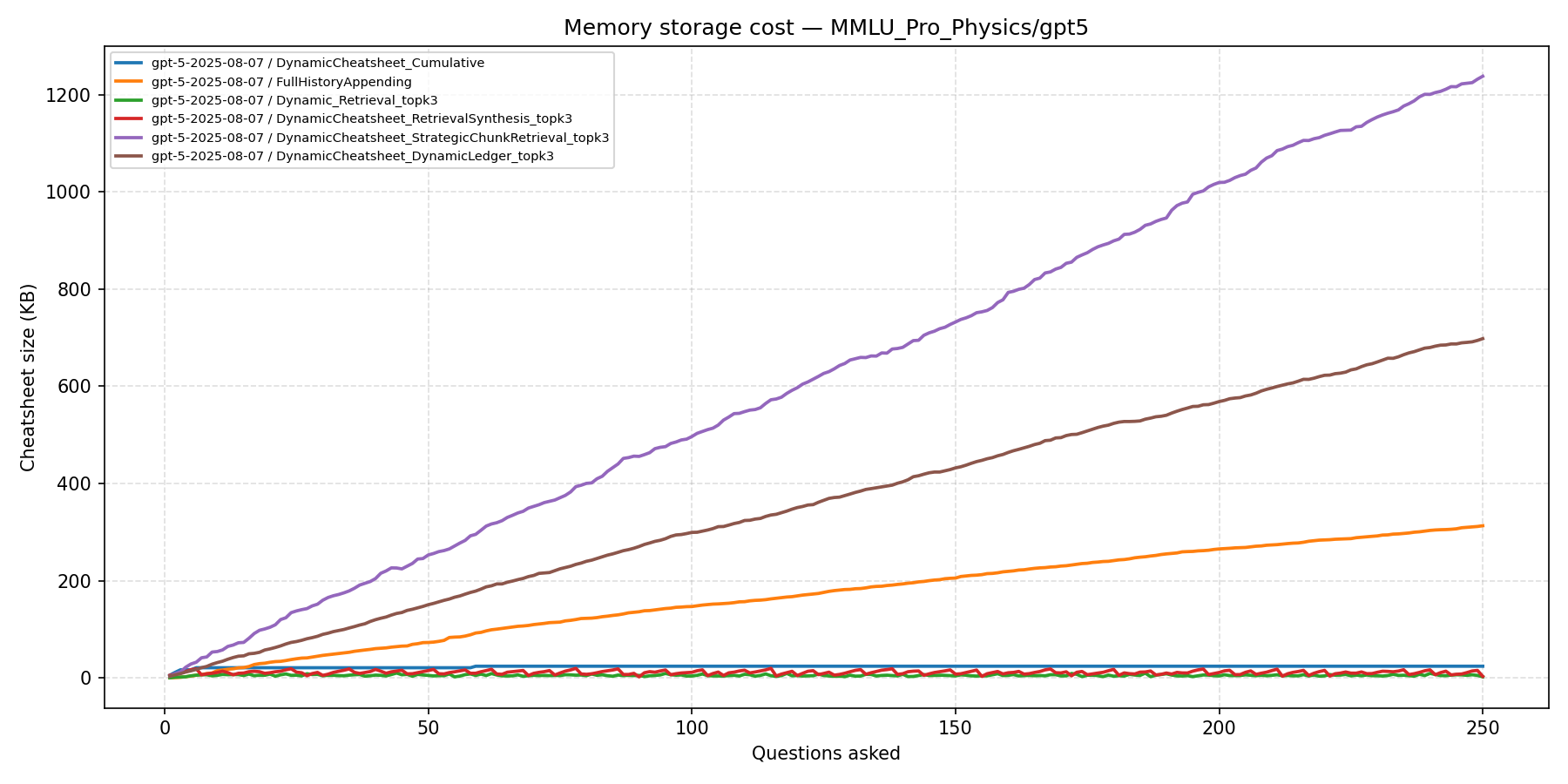
- Memory overhead without accuracy gains. DC-SCR accumulates over 1,200 KB of memory and DC-DL over 700 KB, while DC baselines remain below 50 KB — all for no accuracy benefit.
These results confirm that Dynamic Ledger is most effective when the task distribution contains recurring, transferable problem-solving patterns. Adapting the framework to knowledge-centric tasks remains an open direction.