Quiz 3: Solutions
March 16th, 2021
Below is a historgram of the results.
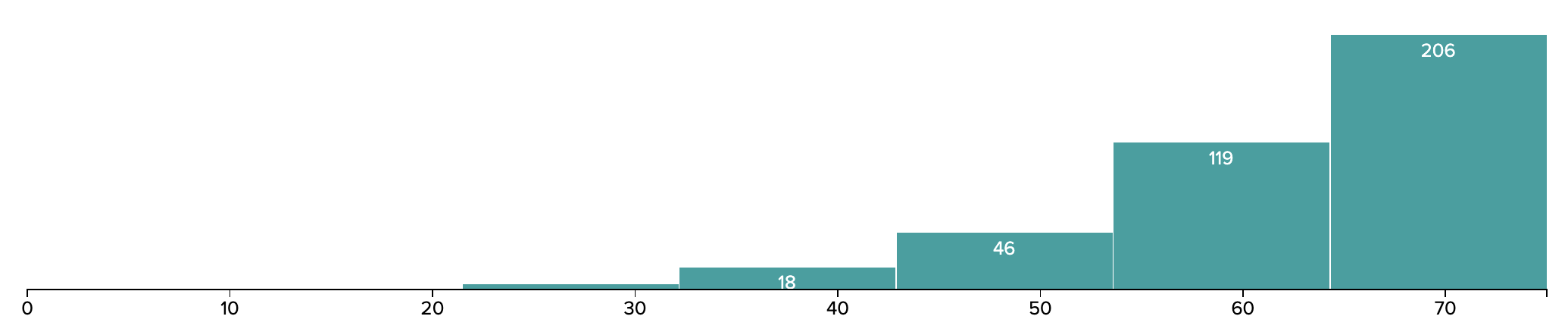 Key Statistics
Key Statistics
- Median: 65.0
- Mean: 63
- Maximum: 75
You can find your answers on Gradescope. Let Juliette know if you do not have access to Gradescope.
Regrade Requests We try to grade as consistently as possible, but we are human and we might make mistakes. If you feel like one of your problems was misgraded, please file a regrade request on Gradescope before Friday March 19th at 7:00pm. Note that this is the only way to have your regrade request considered; in particular, asking your section leader to take a quick look to see whether a problem was misgraded isn't a way of short circuiting this process. We want you to have the credit you deserve, but filing a formal request helps us make sure that your request goes to the right person.
Can I get extra help?
Yes! Come to Nick or Juliette's office hours, post on Ed, and come to LaIR.
How can I check my answers?
With this document you can check your answer. For each problem we include
- Several common solutions
- Comments which explain the solutions
- The major concepts that the problem covers
- Which readings and which lecture videos relate to the problem
I wasn’t able to solve many of the problems on the diagnostic. Should I panic?
Absolutely not! It is normal to find these problems hard. If you didn’t do as well as you
would have liked you have a two step procedure. Step 1: make sure you know the
underlying concepts (for example, using the i variable in a for loop). Then if you know
the concepts but you weren’t able to come up with solutions in time the simple solution is
practice and review! Many people incorrectly think that they are not good at this. False!
We all can code. You just need more experience.
My answer is different from the provided solution. Is my answer wrong?
Not necessarily. You will learn a lot by looking at the difference between the teaching
team solution and your work. Your answer might be great. There are many solutions.
Can I discuss my solution on ed?
Yes! You are free to share your solutions
1. One-liners (20 points)
Do not need to write a def for these questions. For each part, write a 1-line expression to compute the indicated value with: map() or sorted() or min() or max() or a comprehension. You do not need to call list() for these.
# a. Given a list of numbers. # Call map() to produce a result where each # number is multiplied by -1. (or equivalently write a comprehension) >>> nums = [3, 0, -2, 5] # yields [-3, 0, 2, -5] # your expression:map(lambda x: x*(-1), nums)or[num*(-1) for num in nums]# b. Given a list of (x, y) "point" tuples where x and y are int values. # Call map() to produce a result where each (x, y) is replaced # by the sum of x and y. (or equivalently write a comprehension) >>> points = [(1, 2), (4, 4), (1, 3)] # yields [3, 8, 4] # your expression:map(lambda pt: pt[0]+pt[1], points)or[pt[0]+pt[1] for pt in points]# c. Given a list of (city-name, zip-code, current-temperature) tuples, like this >>> cities = [('modesto', 95351, 92), ('palo alto', 94301, 80), ...] # Call sorted() to produce a list of these tuples sorted in decreasing # order by temperature. # your expression:sorted(cities, key=lambda city: city[2], reverse=True)# d. Given a non-empty list of (flower-name, scent-score, color-score) tuples # like the following, scores are in the range 1 .. 10 >>> flowers = [('rose', 4, 8), ('orchid', 7, 2), ... ] # Call max() or min() to return the flower tuple with the highest scent score. # your expression:max(flowers, key=lambda flower: flower[1])
2. Dict (25 points)
We have a social network, and every user is identified by an id string like '@sal'. We have a "recent" dict which tracks which users across the whole system have sent a message recently. For each user who has sent a message within the last hour, there will be an entry in the recent dict with that user as the key and their most recent recipient as the value. For example with the following dict, we see that '@sal' sent a message to '@alice'.
recent = {
'@sal': '@alice',
'@miguel': '@sophie',
...
}
Write code for the send_score() function below - given two users, a and b, and the recent dict, return a "sending" score as follows: if a sent a message to b, the score is 5. If a sent a message to some user, "x", and x sent a message to b, the score is 1. Otherwise the score is 0.
def send_score(recent, a, b):
if a in recent:
sent = recent[a]
if sent == b:
return 5
if sent in recent:
if recent[sent] == b:
return 1
return 0
3. Dict-File (30 points)
Suppose it is the year 2040, and the most important thing in the world is celebrities, each identified by a handle like '@alice'. Celebrities post on the hot new social network PipPop. Each PipPop channel has a name like '#watsup' or '#meh'.
Given a text file with the following format: each line in the file represents one post by a celebrity to 1 or more channels. The first word on the line is a celebrity name like '@alice', followed by 1 or more PipPop channel names, like this:
@alice^#meh^#wut
The line is divided into parts by '^'. The celebrity and channel names may contain punctuation, but will not contain '^'.
We'll say a "posts" dict has a key for each channel, and its value is a nested list of the celebrities that posted to that channel. The list of celebrities should not have duplicates in it; a celebrity should be in the list at most once.
{
...
'#meh': ['@juliette', '@arun', '@nick'],
'#texas': ['@miguel', '@rose'],
...
}
Write code to read through the file described above, building and returning the posts dict. The boilerplate code to read the files lines is provided, and you can change that code if you wish.
def read_posts(filename):
posts = {}
with open(filename) as f:
for line in f:
# could do .strip(), not marking off
words = line.split('^')
celeb = words[0]
for chan in words[1:]:
if chan not in posts:
posts[chan] = []
inner = posts[chan]
inner.append(celeb)
return posts