Assignment 6: MiniBrowser 2
Based on an assignment by Ashley Taylor and Keith Schwarz
Due: Friday, November 16, 11AM
May be done in pairs
In this assignment, you'll use various types of trees to implement several new features in the MiniBrowser program from assignment 5. Specifically, your job is to implement the following features:
- Displaying text: The text is laid out in individual lines on a graphical canvas. We have a scrollbar that should allow a user to move up or down a page, changing which lines are displayed. You'll implement a BST-backed class to determine which lines should be displayed that is more efficient than your previous Vector implementation.
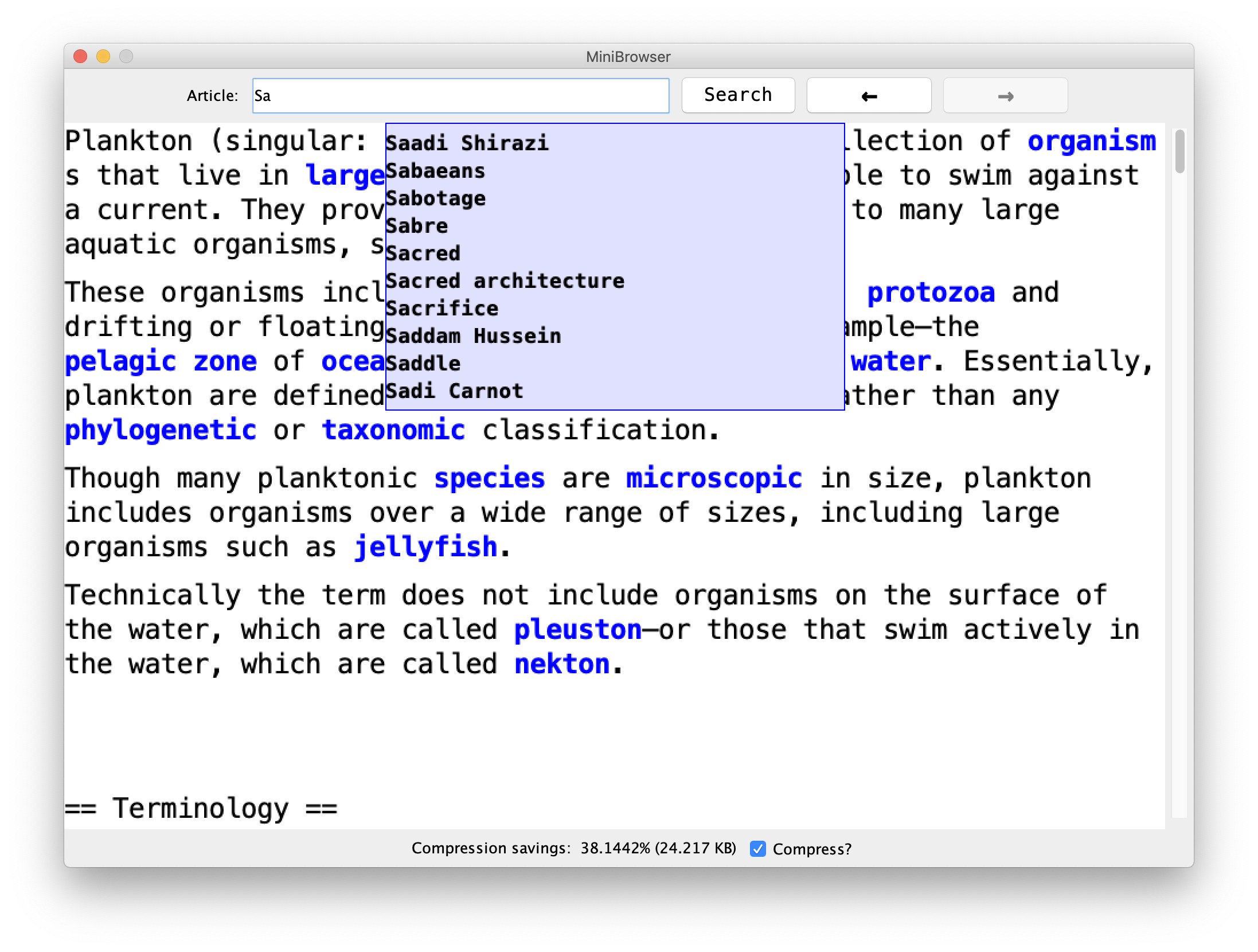
- Autocomplete: you'll implement autocomplete suggestions for what the user might be searching for; these suggestions are displayed as they type. You will use a trie in your implementation.
- Compression: you'll implement the Huffman compression algorithm to allow any type of data to be efficiently compressed into a smaller size, and uncompressed back to the original size. This is used to save space in the browser's cache. You'll use a binary tree in your implementation.
Note that even though this assignment implements additional features into the program from assignment 5, it does not require any of your assignment 5 code. In other words, while you are welcome to combine your implementations from assignments 5 and 6 if you would like, it does not rely on your previous implementations of LineManager, History or Cache.
In order to test your implementation, you are welcome to run the full program (and you will need an internet connection to do so). We, however, suggest that you test each component individually using the provided unit test classes and test program for each part of the assignment. You will need to add several tests to be confident that your implementation is correct.
Important Files and Links
Turn in only the following files:
- LineManager.cpp and LineManager.h, the C++ code for determining which lines of text to display; LineManagerTests.cpp to test your implementation
- Autocomplete.cpp and Autocomplete.h, the C++ code for the autocomplete logic; AutocompleteTests.cpp to test your implementation
- encoding.cpp, the C++ code for the Huffman algorithm; EncodingTests.cpp to test your implementation
- debugging.txt, a file detailing a bug you encountered in this assignment and how you approached debugging it
Development Strategy and Hints
- Draw pictures: When manipulating trees, it is often helpful to draw pictures of the tree before, during, and after each of the operations you perform on it. Manipulating trees can be tricky, but if you have a picture in front of you as you're coding, it can make your job substantially easier.
- Tree states: When processing a tree, you should consider different tree states and transitions between them in your code as you add and remove elements. You should also think about the effect of adding a node at the root, in the middle, and at a leaf of a tree.
- Test your code thoroughly! We'll be running a battery of automated tests on your code; make sure to test various different inputs and edge cases to ensure it works correctly. One tip to help test your data structures is writing
printmethods for your data structures that print out a text representation of the data. That way, you can call your print function to help you debug, just as you would print out an ADT when stuck on previous assignments. The debugger will also almost certainly come in handy, as you can explicitly see the values of pointers. - Implement the parts in order: The parts are designed to be in order of increasing difficulty. The Huffman algorithm in particular is much more challenging than the other parts of the assignment.
Style
As in other assignments, you should follow our Style Guide for information about expected coding style. You are also expected to follow all of the general style constraints emphasized in the previous assignment specs, such as the ones about good problem decomposition, parameters, using proper C++ idioms, and commenting. The following are additional points of emphasis and style constraints specific to this problem:
Commenting: Add descriptive comments to your .h and .cpp files. Both files should have top-of-file header comments that summarize what your program does, and how. One file should have header comments atop each member function (either the .h or .cpp; your choice). The .cpp file should have internal comments describing the details of each function's implementation.
Redundancy: avoid repeated logic as much as possible. Your classes will be graded on whether you make good choices about what members it should have, and other factors such as which are public vs. private, and const-correctness, and so on. We also expect you to remove redundancy within a single class. For instance, if one implementation has a common operation, make a private helper function and call it multiple times in that file.
Tree Usage: Part of your grade will come from appropriately utilizing trees and recursive algorithms to traverse them. Any functions that traverse a tree from top to bottom should implement that traversal recursively. If a particular function must traverse a tree multiple times, it is okay to write a loop that initiates each traversal, as long as the traversal itself is recursive. We will check this particular constraint strictly; no exceptions!
Make member functions const as appropriate.
Some of the member functions you will write do not modify the state of the instance they are being called on.
For all such functions, mark them as const at the end of their headers in the .h and .cpp files in your code.
For example, if a member named foo doesn't modify the instance, you should change its header to:
class MyClass {
...
void functionName() const;
};
You should implement all required member functions exactly as specified, and should not make any changes to the function parameters, name, return type, etc.
Avoiding memory leaks: This item is listed under Style even though it is technically a functional requirement, because memory leakage is not usually visible while a program is running. To ensure that your code does not leak memory, you must delete all of the new objects that you allocate internally. One note is that the Huffman nodes you will allocate when building encoding trees are passed back to the caller, so it is that caller's responsibility to call your freeTree function to clean up the memory. But if you create a Huffman tree yourself to help you implement another function, you must free that entire tree yourself.
Pair Programming
You may optionally work on this assignment as a pair programming assignment. If you would like to work in a pair on this assignment, you may, under the following conditions:
- Both partners must be in the same section (time and location).
- At no time should partners be coding alone. To be clear: all coding must be done together, on a single computer. One partner should type, and the other should watch over that partner's shoulder. Each partner should take turns at the keyboard.
- When you go to the LaIR or office hours for help on your assignment, both students must be present in the pair to receive help. Only one partner should sign up for help in the LaIR Queue at a time.
- Pair programming is less about sharing the workload and more about sharing ideas and working together. During the IG for the assignment, if a Section Leader does not think both partners contributed equally and worked together, the SL may forbid pair programming on a future assignment.
- Pairs who "split the assignment" where one partner does part of the assignment alone, and the other partner does another part of the assignment alone, will be in violation of the Honor Code.
Unit Testing
For each of the three parts mentioned previously, we have included a unit testing file containing some starting tests. These files are LineManagerTests.cpp, AutocompleteTests.cpp and EncodingTests.cpp. You can run these unit tests by running MiniBrowser and selecting the "Tests" option on the launch popup.
For each part of this assignment, you should add at least 3 more unit tests to help you test your implementation.
For LineManager, you should add new tests that are distinct from the tests you added on assignment 5. You can test by simply creating Line objects with just a lowY and highY; you don't need to worry about creating the text that would be associated with a Line in a webpage. Additionally, check out LineManagerNode.h; we have provided some functions that can help test for memory leaks!
For Huffman tests, we recommend using istringstream, ostringstream, istringbitstream and ostringbitstream so that you can test without writing to or reading from files. The bitstream classes are Stanford library classes - see here for more information. Also see some of the provided unit tests for examples. Additionally, check out huffmannode.h; we have provided some functions that can help test for memory leaks!
Make sure that your unit tests test as small, isolated components of your code as possible. Make sure to give each test a detailed name, and comment above it explaining what it is testing.
Also remember to turn in debugging.txt, explaining a bug you encountered, how you identified it, and how you fixed it. You can find this file in the res/ folder of the starter project.
Displaying Text
In this part of the assignment, you'll implement a class called LineManager that stores all the lines for the current webpage, and provides information about which lines should be displayed onscreen. Unlike your previous implementation from assignment 5, it is implemented using a binary search tree of Lines. You'll have to create a binary search tree given a sorted Vector of Line pointers, and utilize that binary search tree as needed. The only member variable (a.k.a. instance variable; private variable; field) you are allowed to have in your implementation is a pointer to the root of your binary search tree. Do not use any other collections or data structures in any part of your code, or have any other private instance variables.
You will need to use Line objects, which represent a single line of text (spanning the entire width of the page). Below is an image of MiniBrowser, with each line outlined in red. The widths of all the lines are the same, and you can sort lines by y-coordinate, with the top line (one with the smallest y-coordinate) as the smallest. In the example below, the line "The Princess Bride is a 1973 fantasy romance novel by American" is the first Line in the webpage.
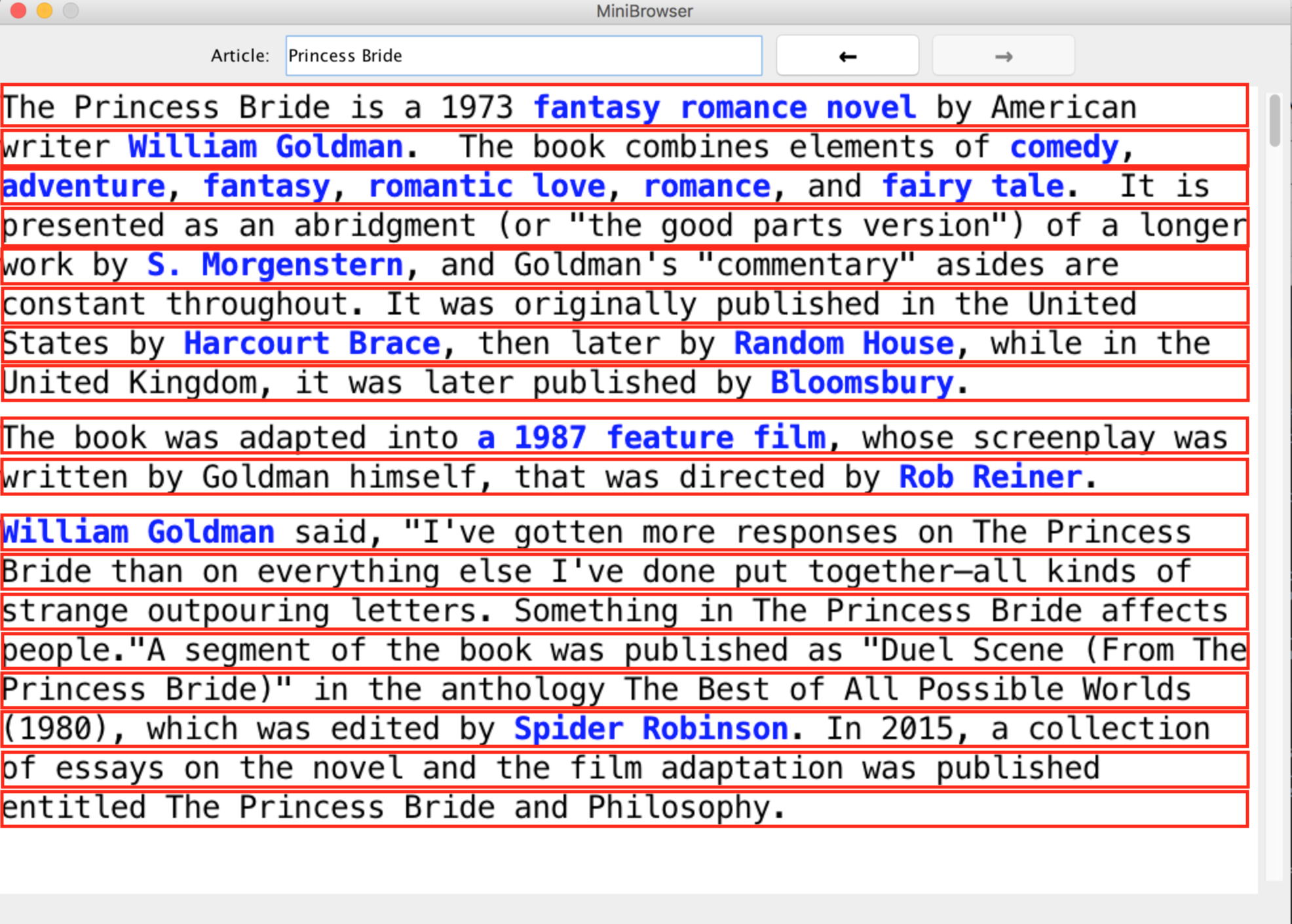
You will not need to manipulate or interact with the text; you can just treat the lines as rectangles (potentially with space between them) that together make up the webpage. No two Line objects will overlap.
The browser already handles splitting the entire webpage into lines. However, since the webpage (generally) is not visible all at once, not all of the lines need to be drawn; in fact, drawing all of the lines would make your browser run very slowly. The solution is an optimization to only draw those lines that will be visible, so your job is to write a function to determine which lines should be drawn. As the user scrolls up or down the page, the "visible range" of lines will change. Binary Search Trees are very effective at handling these "range queries," or returning all the elements within a range.
Browsers also need to handle user clicks, recognizing, for example, if the user is attempting to follow a hyperlink. You will implement a method that, given a y-coordinate, returns a pointer to the line at that location. Our starter code will then search that line for a link, allowing the user to travel to different pages. BSTs are also effective at searching for an element.
At this link, you will find a sample interactive webpage with 12 lines of text and a scrollbar on the right (inside the black box). The black box indicates what is actually visible on the computer, but as you drag the scrollbar (give it a try), the lines will scroll out of view. The browser could render (draw) all the lines of the webpage, but since only 4-5 are visible at a time, it can optimize and only draw those that are fully or partially on the screen. Below the screen, linesInRange's value will update with which lines are in the viewable range of the screen.
The red "x" on the screen represents a location where the user may click; the line at the location of the "x" is reflected next to lineAt at the bottom of the demo. Note that there may be space between the lines, so the element is sometimes nullptr.
A Line has the following fields and methods:
| Field/Method | Description |
|---|---|
| double lowY() | Returns the low end of the range occupied by this line. This value is inclusive. |
| double highY() | Returns the high end of the range occupied by this line. This value is inclusive. |
Since each line spans the width of a page, we only need to store information about its height and vertical placement, not its width or horizontal placement.
As each Line corresponds to a line of text, we can order Lines by their y-coordinate, meaning that the first Line is the line at the top of the screen.
To avoid having to store the text associated with a Line multiple times and to more easily be able to link a Line a user clicked on with the text, you will only be dealing with pointers to Lines. Thus, whenever you store or manipulate the Lines, you should do so using pointers. You should not create Lines in your implementation.
The sorts of operations the LineManager needs to perform are well-suited for a binary-search tree. Because we need to store a Line in each node, we have defined the LineManagerNode struct (defined in LineManagerNode.h) for you to build the BST with:
struct LineManagerNode {
Line* line;
LineManagerNode* left;
LineManagerNode* right;
};
Your job is to implement the following functions:
| Method | Description | Big O |
|---|---|---|
LineManager(const Vector<Line *> & lines) |
The constructor should create the binary search tree, where the elements are in order of their y-coordinates, from least to most. lines is a Vector of pointers to Lines sorted in reading order. If you were to implement normal BST add, the resulting tree would be very skewed, as every line has a larger y value than the one before it. To get the desired O(lg N) functionality for the functions below, you should carefully choose the root to ensure that the subtrees are balanced; this optimization should be applied to the root of every subtree to ensure that the final tree is balanced.
|
O(N) |
~LineManager() |
The destructor. You should be sure not to leak any memory. (Hint: did you allocate any memory in your implementation that needs to be deleted?) | O(N) |
contentHeight() const |
This function should return the vertical space that all the lines occupy (i.e. how tall the browser would need to be to be able to fit all the lines at once). You may assume that the first line is at y-coordinate 0. | O(logN) |
linesInRange(double lowY, double highY) const |
This function should return a Vector of pointers to all Lines that are partially or fully within the bounds of lowY to highY (inclusive). That is to say, linesInRange(60, 80) should include a Line with lowY of 45 and a highY of 65, a line with a lowY of 80 and highY of 100, as well as a line with a lowY of 20 and a highY of 85, but it would not include a line with a lowY of 20 and highY of 40. The Vector should be sorted from lowest to highest y value, just as the BST is. Implementation Hint: Think about how you would return a Vector of all the lines in order, then adjust your solution to only include those lines that are actually within the range, focusing first on lines wholly within the range, then adding lines that are only partially within the range. Finally, optimize your search so that you only traverse those subtrees with children that are potentially in the desired range.
|
O(log N + K), where K is the number of lines returned |
lineAt(double y) const |
This function should return a pointer to the Line that contains the given y-value. You can assume that there is at most one such line. If no line exists at that y-value, you should return nullptr.
|
O(logN) |
The members listed above represent your class's required behavior. But you may add other member functions to help you implement all of the appropriate behavior. Any other member functions you provide must be private. Remember that each member function of your class should have a clear, coherent purpose. You should provide private helper members for common repeated operations. Make a member function and/or parameter const if it does not perform modification of the object's state.
Autocomplete
No browser would be complete without autocomplete, the list below the search bar that dynamically suggests article titles as the user types.
Before tackling this part of the assignment, you should review the notes about tries from Friday's (11/9) lecture.
Our autocomplete will use the several thousand most common Wikipedia article titles (included in TopArticles.txt, which the starter code reads in and adds to the Autocomplete object using the public methods below). When the user begins typing a word, the autocomplete should suggest articles from that list that begin with the characters the user has already typed.
This trie is a little different from those we discussed in class as Wikipedia article titles are not comprised of only the letters a-z. As a result, you will need to design your own struct for each node of the Trie, keeping in mind that your trie will need to be able to support many different characters (including whitespace or even non-English characters). You'll need to devise a space-efficient solution that will work for any character value without any wasted space. For that reason, you should not use an array. One suggestion, however, is to use a string that is one character long instead of a char to store the single character - this is because some more rare characters may have strange values that make debugging more confusing. Keep in mind that this trie is case-sensitive, meaning "Princess Bride" is different from "princess bride".
You will implement the following methods.
| Method | Description |
|---|---|
Autocomplete() |
The constructor should create an empty trie. |
~Autocomplete() |
The destructor. You should be sure not to leak any memory. (Hint: did you allocate any memory in your implementation that needs to be deleted?) |
add(const string& word) |
Add the given title to the trie (recall that the trie is case-sensitive). If the title already exists in the trie, this method should do nothing. |
suggestionsFor(const string& prefix, int maxHits) const |
Returns a Set of suggested articles that all begin with the specified prefix. The Set should be no larger than maxHits, though it may be shorter (or even empty) if there are not enough matches to find. You should stop searching for matches after you've filled the Set, and you can decide which elements to choose in case there are more than maxHits matches. The prefix can be of any length or even empty. If no matches are found, you should return an empty Set.
|
Compression
In this part of the assignment, you will implement the Huffman coding algorithm to compress and uncompress data. We provide a mini program called "Shrink-It" that lets you test just the different parts of your encoding code, including compressing and uncompressing different types of data (we have provided sample files to use in the res/ folder). Once you complete your algorithm, you can also run the main browser program and check the "Compress?" box to have the built-in cache store compressed versions of webpages, instead of the uncompressed ones as you did in assignment 5. At the bottom, you'll be able to see an indicator of the space savings of the compressed cache. You should be able to see some pretty substantial (~30-40%) savings!
Huffman Sample Output
Problem Description:
Huffman encoding (Wikipedia) (Wolfram Mathworld) is an algorithm devised by David A. Huffman of MIT in 1952 for compressing text data to make a file occupy a smaller number of bytes. This relatively simple compression algorithm is powerful enough that variations of it are still used today in computer networks, fax machines, modems, HDTV, and other areas.
Normally text data is stored in a standard format of 8 bits per character using an encoding called ASCII that stores every character using a binary integer value from 0-255.
(ASCII encoding table)
The idea of Huffman encoding is to abandon the rigid 8-bits-per-character requirement and use different-length binary encodings for different characters.
The advantage of doing this is that if a character occurs frequently in the file, such as the common letter 'e', it could be given a shorter encoding (fewer bits), making the file smaller.
The tradeoff is that some characters may need to use encodings that are longer than 8 bits, but this is reserved for characters that occur infrequently, so the extra cost is worth it.
The table below compares ASCII values of various characters to possible Huffman encodings for some English text.
Frequent characters such as space and 'e' have short encodings, while rarer ones like 'z' have longer ones.
(* The Huffman encodings shown in the table below are hypothetical and would not always be the result of your program.)
| Character | ASCII value | ASCII (binary) | Huffman (binary) * |
|---|---|---|---|
' ' |
32 |
00100000 |
10 |
'a' |
97 |
01100001 |
0001 |
'b' |
98 |
01100010 |
0111010 |
'c' |
99 |
01100011 |
001100 |
'e' |
101 |
01100101 |
1100 |
'z' |
122 |
01111010 |
00100011010 |
In this program you will write code to encode and decode files using Huffman's algorithm, which relies on binary trees. We provide you with starter code for the user interaction and menus. The following is one sample partial log of execution of the provided main program. More logs are available above or through the Compare Output feature in your console window.
Welcome to CS 106B/X Shrink-It! ... B)uild enc.tree C)ompress VB) View binary E)ncode data U)ncompress VT) View text D)ecode data F)ree tree VS) View side-by-side Q)uit Your choice? c Input file name: large.txt Output file name (Enter for large.huf): large.huf Reading 9768 uncompressed bytes. Compressing ... Wrote 5921 compressed bytes.
Here is a supplementary handout on Huffman encoding and file compression if you are interested in more information after reading this spec.
Encoding a File:
To perform a Huffman encoding of a given text source file into a destination compressed file, you must first build a Huffman tree.
This operation is represented by the required function buildEncodingTree that you will implement.
A Huffman tree is a binary tree with a particular structure, where each node represents a character and its count of occurrences in the file.
The path of left (0) and right (1) links along the tree from its root to each leaf indicates the binary encoding of that character in your eventual compressed output.
There is a well-defined algorithm for converting a given input data set into a Huffman tree.
Suppose we have a file named example.txt whose contents are:
ab ab cab
In the original file, this text occupies 10 bytes (80 bits) of data. The 10th is a special "end-of-file" (EOF) byte, which we will represent using the special fake value of 256.
| byte | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| char | 'a' |
'b' |
' ' |
'a' |
'b' |
' ' |
'c' |
'a' |
'b' |
EOF |
| ASCII | 97 |
98 |
32 |
97 |
98 |
32 |
99 |
97 |
98 |
256 |
| binary | 01100001 |
01100010 |
00100000 |
01100001 |
01100010 |
00100000 |
01100011 |
01100001 |
01100010 |
N/A |
A possible Huffman tree for this input data is shown below. There is an algorithm to create a Huffman tree from a given input data, which we'll show later in this document. For now let's just look at the given tree and understand how it would be useful for compressing data.
+---+
| |
+---+
0 _____/ \_____ 1
/ \
+---+ +---+
| | | |
+---+ +---+
0 / \ 1 0 / \ 1
/ \ / \
+---+ +---+ +---+ +---+
|' '| | | |'a'| |'b'|
+---+ +---+ +---+ +---+
0 / \ 1
/ \
+---+ +---+
|'c'| |EOF|
+---+ +---+
If we traverse the tree and think of each left branch as a 0 and each right branch as a 1, we can traverse the tree to come up with binary encodings for every character in the file.
In this case, those encodings would be:
' ' = 00 'c' = 010 EOF = 011 'a' = 10 'b' = 11
We could then write out the binary encoded versions of these characters to compress the original input of ab ab cab (which is 10 bytes including EOF) into the following compressed version, which occupies only 22 bits (3 bytes):
1011001011000101011011
This particular example encoding takes advantage of the fact that not every ASCII character appears in the input file, but Huffman encoding can still effectively compress a file even if it uses a wider variety of characters.
Now that we've explored the Huffman tree structure and how it can be useful, let's talk about how to build a Huffman tree for a given input file's contents.
Building a Huffman Tree:
The task of building the Huffman tree for a given input file is represented by the following function that you must write in encoding.cpp. The nodes of your Huffman tree must be allocated on the heap so that they will remain in existence after your function returns. Your function must return a pointer to the node representing the root of the tree you have created. Your function must have the following signature:
HuffmanNode* buildEncodingTree(istream& input)
In this function you read input from a given input stream, which could be a file on disk, a string stream, or any other source of input. You may assume that the input file exists and can be read, though the file might be empty.
Suppose as in the previous example we have a file named example.txt whose contents are:
ab ab cab
To begin encoding this file into a Huffman tree, you should count the number of occurrences of each unique character.
You should also include a count of a single occurrence of the fake character PSEUDO_EOF, which is a global constant defined in the provided starter code; note that PSEUDO_EOF doesn't appear in the input file, and you have to manually fake as though it appears at the end of the file.
In the previous input, there are two spaces, three occurrences of 'a', three 'b', one 'c', and one pseudo EOF.
(An empty file should be considered to contain only 1 occurrence of PSEUDO_EOF and no other characters.)
You should store these counts into node structures, and put the node structures into a priority queue, with smaller counts having more urgent priority, so that characters with lower counts will come out of the queue sooner.
For example, the following might be the contents of the priority queue for the preceding input file.
The priority queue is somewhat arbitrary in how it breaks ties, such as 'c' being before EOF and 'a' being before 'b'.
front back +---------------------------------------------------+ | | | +-----+ +-----+ +-----+ +-----+ +-----+ | | | 'c' | | EOF | | ' ' | | 'a' | | 'b' | | | | 1 | | 1 | | 2 | | 3 | | 3 | | | +-----+ +-----+ +-----+ +-----+ +-----+ | | | +---------------------------------------------------+
The elements you put into the priority queue should be pointers to binary tree nodes, with each node storing a character and a count of its occurrences.
We provide you with a structure called HuffmanNode that represents a node in a Huffman encoding tree:
struct HuffmanNode {
int character; // character being represented by this node
int count; // number of occurrences of that character
HuffmanNode* zero; // 0 (left) subtree (null if empty)
HuffmanNode* one; // 1 (right) subtree (null if empty)
...
};
The character field is declared as type int, but you should think of it as if it were a char.
(Types char and int are largely interchangeable in C++, but using int here allows us to sometimes use character to store values outside the normal range of char for use as special flags.)
The character field of a node can take one of three types of values:
-
an actual
charASCII value from 0-255; -
the constant
PSEUDO_EOF(defined in bitstream.h in the Stanford library), which represents the pseudo-EOF value (the symbol, denoted by|in the supplemental Huffman handout, that marks the end of the encoding) that you will need to place at the end of an encoded stream (this happens to be the value 256); or -
the constant
NOT_A_CHAR(defined in bitstream.h in the Stanford library), which represents something that isn't actually a character. (This can be stored in branch nodes of the Huffman encoding tree that have children, because such nodes do not represent any one individual character.) (This happens to be the value 257.)
Your algorithm converts the priority queue of nodes into a Huffman tree as follows: You repeatedly remove the two node pointers A and B from the front of the queue (the two with the fewest occurrences) and create a new parent node C, whose children are A and B, and whose count of occurrences is the sum of A's and B's. The first node removed (A) becomes the left child, and the second (B) becomes the right. The new node is re-inserted into the queue in sorted order of occurrences. This process is repeated until the queue contains only one binary tree node with all the others as its children. This will be the root of our finished Huffman tree. (Note: Don't actually name your variables A, B, and C in your code. One-letter variable names are usually bad.)
The following diagram shows the algorithm in progress. Notice that the nodes with low frequencies end up far down in the tree, and nodes with high frequencies end up near the root of the tree. This structure can be used to create an efficient encoding in the next step.
front back +---------------------------------------------------+ | | | +-----+ +-----+ +-----+ +-----+ +-----+ | | | 'c' | | EOF | | ' ' | | 'a' | | 'b' | | | | 1 | | 1 | | 2 | | 3 | | 3 | | | +-----+ +-----+ +-----+ +-----+ +-----+ | | | +---------------------------------------------------+
front back +-----------------------------------------+ | | | +-----+ +-----+ +-----+ +-----+ | | | ' ' | | | | 'a' | | 'b' | | | | 2 | | 2 | | 3 | | 3 | | | +-----+ +-----+ +-----+ +-----+ | | / \ | +-------------/---\-----------------------+ / \ +-----+ +-----+ | 'c' | | EOF | | 1 | | 1 | +-----+ +-----+
front back +-------------------------------+ | | | +-----+ +-----+ +-----+ | | | 'a' | | 'b' | | | | | | 3 | | 3 | | 4 | | | +-----+ +-----+ +-----+ | | / \ | +-----------------------/---\---+ / \ +-----+ +-----+ | ' ' | | | | 2 | | 2 | +-----+ +-----+ / \ / \ +-----+ +-----+ | 'c' | | EOF | | 1 | | 1 | +-----+ +-----+
front back
+--------------------------------+
| |
| +-----+ +-----+ |
| | | | | |
| | 4 | | 6 | |
| +-----+ +-----+ |
| / \ / \ |
+---/---\----------------/---\---+
/ \ / \
+-----+ +-----+ +-----+ +-----+
| ' ' | | | | 'a' | | 'b' |
| 2 | | 2 | | 3 | | 3 |
+-----+ +-----+ +-----+ +-----+
/ \
/ \
+-----+ +-----+
| 'c' | | EOF |
| 1 | | 1 |
+-----+ +-----+
+---------------+
| |
| +-----+ |
| | | |
| | 10 | |
| +-----+ |
| / \ |
+---/-------\---+
/ \
+-----+ +-----+
| | | |
| 4 | | 6 |
+-----+ +-----+
/ \ / \
/ \ / \
+-----+ +-----+ +-----+ +-----+
| ' ' | | | | 'a' | | 'b' |
| 2 | | 2 | | 3 | | 3 |
+-----+ +-----+ +-----+ +-----+
/ \
/ \
+-----+ +-----+
| 'c' | | EOF |
| 1 | | 1 |
+-----+ +-----+
When building the encoding tree, use the PriorityQueue collection provided by the Stanford libraries, defined in library header priorityqueue.h.
This priority queue allows each element to be enqueued along with an associated numeric priority.
The priority queue then sorts elements by their priority, with the dequeue function always returning the element with the minimum priority number.
Consult the PriorityQueue documentation on the course website and lecture slides for more information about priority queues.
Compressing a File Using a Huffman Tree:
Once you have a Huffman tree, you can use it to compress a file. The step of encoding a file's data using a Huffman tree is represented by the following function that you must write:
void encodeData(istream& input, HuffmanNode* encodingTree, obitstream& output)
(The obitstream type is an output stream for writing bits and is described later in this document.)
The Huffman code for each character is derived from your binary tree by thinking of each left branch as a bit value of 0 and each right branch as a bit value of 1, as shown in the diagram below.
+-----+
| |
| 10 |
+-----+
/ \
0 / \ 1
+-----+ +-----+
| | | |
| 4 | | 6 |
+-----+ +-----+
/ \ / \
0 / \ 1 0 / \ 1
+-----+ +-----+ +-----+ +-----+
| ' ' | | | | 'a' | | 'b' |
| 2 | | 2 | | 3 | | 3 |
+-----+ +-----+ +-----+ +-----+
/ \
0 / \ 1
+-----+ +-----+
| 'c' | | EOF |
| 1 | | 1 |
+-----+ +-----+
The code for each character can be determined by traversing the tree.
To reach ' ' we go left twice from the root, so the code for ' ' is 00.
The code for 'c' is 010, the code for EOF is 011, the code for 'a' is 10 and the code for 'b' is 11.
Using these encodings, we can encode the file's text into a shorter binary representation.
The text ab ab cab would be encoded as:
1011001011000101011011
The following table details the char-to-binary translation in more detail.
The overall encoded contents of the file require 22 bits, or almost 3 bytes, compared to the original file of 10 bytes.
| char | 'a' |
'b' |
' ' |
'a' |
'b' |
' ' |
'c' |
'a' |
'b' |
EOF |
|---|---|---|---|---|---|---|---|---|---|---|
| binary | 10 |
11 |
00 |
10 |
11 |
00 |
010 |
10 |
11 |
011 |
Since the character encodings have different lengths, often the length of a Huffman-encoded file does not come out to an exact multiple of 8 bits. Files are stored as sequences of whole bytes, so in cases like this the remaining digits of the last bit are filled with 0s. You have no control over this; it is a rule of the operating system that every file must occupy whole bytes.
| byte | 1 | 2 | 3 |
|---|---|---|---|
| char | a b a |
b c a |
b EOF |
| binary | 10 11 00 10 |
11 00 010 1 |
0 11 011 00 |
It might worry you that the characters are stored without any delimiters between them, since their encodings can be different lengths and characters can cross byte boundaries, as with 'a' at the end of the second byte.
But this will not cause problems in decoding the file, because Huffman encodings by definition have a useful prefix property where no character's encoding can ever occur as the start of another's encoding.
In your function you will read one character at a time from a given input file, and use the provided Huffman tree to come up with a translation from each character to binary, then write the character's encoded binary bits to the given bit output bit stream.
After writing the file's contents, you should write a single occurrence of the binary encoding for PSEUDO_EOF into the output so that you'll be able to identify the end of the data when decompressing the file later.
You may assume that the parameters are valid: that the given Huffman tree is valid and contains information for every character that appears in the input file, that the input file stream is readable, and that the output stream is writable. The streams are already opened and ready to be read/written; you do not need to prompt the user or open/close the files yourself.
Decoding a File:
You can use a Huffman tree to decode text that was previously encoded with its binary patterns. The step of decoding the file's data from the compressed binary bits is represented by the following function that you must write:
void decodeData(ibitstream& input, HuffmanNode* encodingTree, ostream& output)
(The ibitstream type is an input stream for reading bits and is described later in this document.)
The decoding algorithm is to read each bit from the file, one at a time, and use these bits to recursively traverse the Huffman tree. Starting from the root, if the bit is a 0, you move left in the tree. If the bit is 1, you move right. You do this until you hit a leaf node. Leaf nodes represent characters, so once you reach a leaf, you output that character, and then your algorithm should return to the top of the tree. For example, suppose we are given the same encoding tree above, and we are asked to decode a file containing the following bits:
111001000100101001100000
Using the Huffman tree, we walk from the root until we find characters, then output them and go back to the root.
-
We read a 1 (right), then a 1 (right). We reach the leaf
'b'and output it. Return to the root.
111001000100101001100000 -
We read a 1 (right), then a 0 (left). We reach leaf
'a'and output it. Return to root.
111001000100101001100000 -
We read a 0 (left), then a 1 (right), then a 0 (left). We reach
'c'and output it.
111001000100101001100000 -
We read a 0 (left), then a 0 (left). We reach
' 'and output a space.
111001000100101001100000 -
We read a 1 (right), then a 0 (left). We reach
'a'and output it.
111001000100101001100000 -
We read a 0 (left), then a 1 (right), then a 0 (left). We reach
'c'and output it.
111001000100101001100000 -
We read a 1 (right), then a 0 (left). We reach
'a'and output it.
111001000100101001100000 -
We read a 0, 1, 1. This is our EOF encoding pattern, so we stop.
111001000100101001100000 -
The overall decoded text is
"bac aca". (Notice that we do not read or decode the final 00000 bits in the last byte because they come after the EOF marker.)
In this function you should do the opposite of encodeData; you read the input one bit at a time, and write the uncompressed contents one byte at a time.
You may assume that the streams are already opened and you do not need to prompt the user for file names, nor open/close the files yourself.
To manually verify that your implementations of encodeData and decodeData are working correctly, use our provided test code to compress strings of your choice into a sequence of 0s and 1s.
The rest of this document describes a header that you will add to compressed files, but in encodeData and decodeData, you should not write or read this header from the file.
Instead, just use the encoding tree you're given.
Worry about headers only in the compress / uncompress functions described later.
Proper Use of I/O Streams:
In parts of this program you will need to read and write individual bytes to files. In the past we have wanted to read input an entire line or word at a time. But in this program it is much better to read one single character (byte) at a time. So you should use the following in/output stream functions:
istream (input stream) member |
Description |
|---|---|
int get() |
Reads a single byte (8-bit character) from the input stream; returns -1 if the stream has reached the end of the file. |
ostream (output stream) member |
Description |
|---|---|
void put(int byte) |
Writes a single byte (8-bit character) to the output stream.
You can also pass a char value.
|
You might also find that you want to read an input stream, then "rewind" it back to the start and read it again.
To do this on an input stream variable named input, you can use the rewindStream function from "filelib.h"
(documentation):
rewindStream(input); // tells the stream to seek back to the beginning
Bit Input/Output Streams:
To read or write a compressed file, reading one byte at a time is still too much; you will want to read and write binary data one single bit (eighth of a byte) at a time, which is not directly supported by the default in/output streams.
Therefore the Stanford C++ library provides obitstream and ibitstream classes with writeBit and readBit members to make it easier.
These classes come from "bitstream.h"
(documentation):
ibitstream (bit input stream) member |
Description |
|---|---|
int readBit() |
Reads a single bit (0 or 1) from input; returns -1 if the stream has reached the end of the file. |
obitstream (bit output stream) member |
Description |
|---|---|
void writeBit(int bit) |
Writes a single bit (0 or 1) to the output stream. |
When reading from an bit input stream (ibitstream), you can detect the end of the file by either looking for a readBit result of -1, or by calling the fail() member function on the input stream after trying to read from it, which will return true if the last readBit call was unsuccessful due to reaching the end of the file.
Note that the bit in/output streams also provide the same members as the original ostream and istream classes from the C++ standard library, such as getline, <<, >>, etc.
But you usually don't want to use those, because they operate on an entire byte (8 bits) at a time, or more; whereas you want to process these streams one bit at a time.
Compress/Uncompress and Header:
The last step of this program is to glue all of your previous code together into two functions that do all of the work of compressing and uncompressing a file in a single call. An important concept used by these two functions is the notion of a file header that they will use to store data about the compression process.
void compress(istream& input, obitstream& output) void uncompress(ibitstream& input, ostream& output)
Let's discuss the compress function in more detail.
In this function you should compress the given input file into the given output file, combining all of the steps described previously.
You will take as parameters an input file that should be encoded and an output bit stream to which the compressed bits of that input file should be written.
You should read the input file one character at a time, building an encoding of its contents, and write a compressed version of that input file, including a header, to the specified output file.
This function should be built on top of the other encoding functions described earlier in this document and should call them as needed.
You may assume that the streams are both valid and read/writeable, but the input file might be empty. If the file is empty, your code will fail to read the header, so you should stop there and return without uncompressing the file. The streams are already opened and ready to be read/written; you do not need to prompt the user for filenames or open/close the files yourself. If your function allocates any dynamic memory on the heap, you must free it and not leak memory.
But there is an additional piece of work that your compress function needs to do, which is to write a header into the compressed file.
The reason you need a header is because in order to decode the compressed file later, we need a way to recreate its Huffman tree.
Without the encoding tree, you don't know the mappings from bit patterns to characters.
What if all we have is the compressed file?
How will we know how to decode it?
To address this issue, you must come up with a way of storing information about the Huffman encodings inside the compressed file itself. The encodings must be stored as a prefix of data at the start of the compressed file, which we will call the header of the file. The idea is that when opening our compressed file later, the first several bytes will store your encoding information, and then those bytes are immediately followed by the compressed binary bits that we compressed earlier. In spirit we want to write out the Huffman tree into the compressed file; but it isn't possible to write out the tree directly, so we must come up with a way to "flatten" the tree, or store information equivalent to the tree's contents, or store information that can be used to rebuild or recreate the tree's contents.
What should we store in our header? How do we represent the Huffman tree and its binary character encodings? This is up to you. You don't need to store the header as compressed binary data, and you don't have to write the encoding header bit-by-bit. It's fine to just write out normal ASCII characters if you like. Or if you want to come up with a more efficient compressed way of representing your header, that is fine, too.
If you're stumped about how to write out a reasonable header, you can just use the following suboptimal algorithm to write out a mapping of character counts as follows.
If you create a mapping of character counts from the original uncompressed file, you could regenerate the encoding tree from that, which would give you the information you need to uncompress the file.
For example, for our ab ab cab example, a mapping of characters to frequencies would be the following (the keys are shown by their ASCII integer values, such as 32 for ' ', and 97 for 'a', and 256 for EOF, because that is the way the map would look if you printed it out):
{32:2, 97:3, 98:3, 99:1, 256:1}
In C++, collections like maps can easily be read and written to/from streams using << and >> operators.
So all you need to do for your header is write your map using << into the bit output stream first before you start writing bits into the compressed file, and read that same map back in using >> later when you uncompress it.
For very small input files like our example, the header can end up being larger than the compressed file's data; it can even make it so that the compressed file is larger than the original uncompressed file was! Oops! But this is okay as long as the cost of the header is not so bad relative to the overall file size for a larger file.
Now let's discuss the uncompress function in more detail.
In this function you should do the opposite of compress; you should read the bits from the given input file one at a time, including your header packed inside the start of the file, to write the original contents of that file to the file specified by the output parameter.
You may assume that the streams are valid and read/writeable, but the input file might be empty.
The streams are already open and ready to be used; you do not need to prompt the user for filenames or open/close files.
If your function allocates any dynamic memory on the heap, you must free it and not leak memory.
Freeing Memory:
You must make sure that your algorithm does not leak memory. To help ensure this, you must write one more function that accepts a pointer to the root of a Huffman tree as a parameter and frees all of the heap-allocated memory associated with that tree:
void freeTree(HuffmanNode* node)
Your code must free the root node and all nodes in its subtrees. There should be no effect if the tree passed is null.
The idea is that your other functions should call freeTree as appropriate to clean up after themselves.
If any of your functions creates a Huffman tree but does not return it to the caller, then your function should also free the tree.
Development Strategy and Hints:
Do not use type char anywhere in your program.
Declare all character variables as type int.
This is needed for your program to function properly.
If you use char, non-text files (e.g. images) won't work.
When writing the bit patterns to the compressed file, note that you do not write the ASCII characters '0' and '1' (that wouldn't do much for compression!), instead the bits in the compressed form are written one-by-one using the readBit and writeBit member functions on the bitstream objects.
Similarly, when you are trying to read bits from a compressed file, don't use >> or byte-based methods like get or getline; use readBit instead.
The bits that are returned from readBit will be either 0 or 1, but not '0' or '1'.
Work step-by-step. Get each part of the encoding program working before starting on the next one. You can test each function individually using our provided client program, even if others are blank or incomplete. Consider breaking each required step into sub-steps as appropriate and testing each sub-step in isolation.
Start out with small test files (two characters, ten characters, one sentence) to practice on before you start trying to compress large books of text. What sort of files do you expect Huffman to be particularly effective at compressing? On what sort of files will it less effective? Are there files that grow instead of shrink when Huffman encoded? Consider creating sample files to test out your theories.
Your implementation should be robust enough to compress any kind of file: text, binary, image, or even one it has previously compressed. Your program probably won't be able to further squish an already compressed file (and in fact, it can get larger because of header overhead) but it should be possible to compress multiple iterations, uncompress the same number of iterations, and return to the original file.
Your program only has to uncompress files compressed by your program. You do not need to protect against user error such as trying to uncompress a file that isn't in the proper compressed format.
The operations that read and write bits are somewhat inefficient and working on a large file (100K and more) will take some time. Don't be concerned if the reading/writing phase is slow for very large files.
Note that Qt Creator puts the compressed binary files created by your code in your build_Xxxxxxx folder. They won't show up in the normal res/ resource folder of your project.
Frequently Asked Questions (FAQ):
-
Q: The spec says I am not supposed to modify the
.hfiles. But I want to use a helper function. Don't I need to modify the.hfile to add a function prototype declaration for my helpers? Can I still use helper functions even if I don't modify the.hfile? -
A: Do not modify the provided .h file.
Just declare your function prototypes in your .cpp file (near the top, above any code that tries to call those functions) and it'll work fine.
You can declare a function prototype anywhere: in a .cpp file, in a .h file, wherever you want.
The idea of putting them in a .h file is just a convention.
When you
#includea file, the compiler literally just copy/pastes the contents of that file into the current file. We have already done this on hw1, hw2, and others. - Q: In Part 1 of encoding, what is a "pseudo EOF"? How do I add a "pseudo EOF" to my encodings?
-
A:
PSEUDO_EOFis a global constant that is visible to your program. It is just anintconstant whose value happens to be256, so you can put it into your encoding process as a node with the count of 1.You also need to explicitly write out a single occurrence of
PSEUDO_EOF's binary encoding when you compress a file using theencodeDatafunction. Write out all of the necessary bits to encode the file's data, and then after that, write out the binary encoding forPSEUDO_EOFinto the file at the end. -
Q: What is the difference between a "pseudo EOF" and a "real" EOF?
What is the value of "real" EOF? Is it
-1? Because file input functions likeget()return-1when you reach the end of the file, so are they returning "real" EOF? -
There is a difference between
PSEUDO_EOFand the notion of a "real" EOF.PSEUDO_EOFis256, and it's a fake value that our program is using to signal the end of compressed data in a file. A real EOF is not-1. It is not a character or integer value at all; it is something decided internally by the operating system. The real file system knows where the end of a file is because there is master table of data about all the files on the disk, and that table stores every file's length in bytes. The OS doesn't insert any special character at the end of each file; it just knows that you have hit the end-of-file once you have read a certain number of bytes equal to that file's length. The input stream'sgetfunction just returns-1when you're done because that's how they chose to indicate to you that the file was ended, not because an actual -1 is on the hard disk. -
Q: What is
NOT_A_CHAR? When will I see it? What do I need to use it for? -
A:
NOT_A_CHAR, likePSEUDO_EOF, is a global constant that is visible to your program. It is just anint, so you can use it in places where a character is expected. The only placeNOT_A_CHARshould be used in this assignment is when you create aHuffmanNodethat has children, when you are combining nodes during Step 2 of the encoding process. The parent node has two subtrees under it and it doesn't directly represent any one character, so you storeNOT_A_CHARas thecharacterdata field of the parent node. That should be the only time you seeNOT_A_CHARand the only place you need to use it. You'll never see that value in an input or output file or anything like that. - Q: My Huffman tree doesn't get created correctly. How can I tell what's going on?
-
A: We suggest inserting print statements in the function that builds the tree.
The HuffmanNodes have a
<<operator, so you can print them out. There is also aprintSidewaysfunction provided that takes aHuffmanNode*and prints that entire tree sideways. - Q: The contents of my priority queue don't seem to be in sorted order. Why?
-
A: A
PriorityQueue's ordering is based on the priorities you pass in when you enqueue each element. Are you sure you are adding each node with the right priority? - Q: What should the priority queue's ordering be if the two nodes' frequencies are equal?
- A: If the counts are the same, just add them both with the same priority and let the priority queue decide how to relatively order those two items.
- Q: I don't understand the different kinds of input/output streams in the assignment. Which kind of stream is used in what situation? How do I create and initialize a stream? When do I open/close them?
-
A: Here's a rundown of the different types of streams:
-
An
istream(akaifstream) reads bytes from a file. You'd use this to read a normal file byte-by-byte so that you can compress its contents. -
An
ostream(akaofstream) writes bytes to a file. You'd use this to write to an uncompressed file byte-by-byte when you are decompressing. -
An
ibitstreamreads bits from a file. You'd use this to read a compressed file bit-by-bit when you are decompressing it. -
An
obitstreamwrites bits to a file. You'd use this to write to a compressed file bit-by-bit when you are compressing.
Here's a diagram summarizing the streams:
compress: +-----------------+ read bytes write bits +-----------------+ | normal file | istream YOUR obitstream | compressed file | | foo.txt | --------------> CODE ---------------> | foo.huf | +-----------------+ 'h', 'i', ... 010101010101 +-----------------+ ================================================================================= decompress: +-----------------+ read bits write bytes +-----------------+ | compressed file | ibitstream YOUR ostream | normal file | | foo.huf | --------------> CODE ---------------> | foo-out.txt | +-----------------+ 010101010101 'h', 'i', ... +-----------------+You never need to create or initialize a stream; the client code does that for you. You are passed a stream that is ready to use; you don't need to create it or open it or close it.
-
An
- Q: How can I tell what bits are getting written to my compressed file?
- A: The main testing program has a "binary file viewer" option to print out the bits of a binary file. Between that and print statements in your own code for debugging, you should be able to figure out what bits came from where.
- Q: What parts of the program need to worry about the "header"?
-
A: Only
compressanddecompress. The other functions, such asencodeDataanddecodeData, should not worry about headers at all and should not contain any code related to headers. -
Q: My individual functions for each step of the encoding process seem to work.
But my
compressfunction always produces an empty file or a very small file. Why? -
A: Maybe you are forgetting to "rewind" the input stream.
Your
compressfunction reads over the input stream data twice: once to count the characters so that you can build a Huffman tree, and a second time to actually compress it using your encodings. Between those two actions, you must rewind the input stream by writing code such as:rewindStream(input); // tells the stream to seek back to the beginning - Q: Why do I have some unexpected junk characters at the end of my output when decoding?
-
A: You need to look for the
PSEUDO_EOFas a marker to tell you when to stop reading. Make sure you insert aPSEUDO_EOFat the end of the output when you are encoding data. And make sure to check for PSEUDO_EOF when decoding later. - Q: My program works for most files, but when I try to decompress a big file like hamlet.txt, I get a crash. Why?
- A: It's possible that your algorithm is nesting too many recursive calls. Once you are done making one recursive walk down the tree, you should let the call stack unwind rather than making another recursive call to get back to the top of the tree.
- Q: My program works fine on text files, but it produces corrupt results for binary files like images (bmp, jpg) or sound files (mp3, wav). Why?
-
A: This most commonly occurs when you store bytes from a file as type
charrather than as typeint. Useint. Typecharworks fine for ASCII characters but not for extended byte values that commonly occur in binary files. - Q: My program runs really slowly on large files like hamlet.txt. How can I speed it up?
- A: It is expected that the code will take a little while to run on a large file. Our solution takes a few seconds to process Hamlet. Your program also might be slow because you're running it on a slow disk drive such as a USB thumb drive.
- Q: What should it do if the file to compress/decompress is empty?
- A: Your program should be able to handle this case. You'll write a header containing only the pseudo-EOF encoding, so the 0-byte file increases back up to around 7 bytes. When you decompress the file, it'll go back to being a 0-byte file. You may not even need to write any special code to handle the empty file case; it will "just work" if you follow the other algorithms properly.
-
Q: What is the default value for a
char? Whatcharvalue can I use to represent nothing, or the lack of a character? -
A: The default
charvalue is'\0', sometimes called the 'null character'. (Not the same asNULLornullptr, which is the null pointer.) But Huffman nodes that have children should storeNOT_A_CHAR, a constant declared by our support code. -
Q: When do I need to call my own
freeTreefunction? Do I ever need to call it myself? -
A: If you ever create an encoding tree yourself as a helper to assist you in solving some larger task, then you should free that tree so that you don't leak memory.
So for example, your
buildEncodingTreefunction should not free the tree because it is supposed to return that tree to the client, and presumably that client will later free it. But if you callbuildEncodingTreesomewhere in your code because you want to use an encoding tree to help you, then when you are done using it, you should immediately callfreeTreeon it.
Extra Features
Though your solution to this assignment must match all of the specifications mentioned previously, it is allowed and encouraged for you to add extra features to your program if you'd like to go beyond the basic assignment. Here are some suggestions:
- More intelligent page layout: Take a look at how we choose to divide lines. Can you find a better way to layout lines and assign line breaks?
- GUI enhancements or other Browser Features: Although we haven't taught GUI programming in this class, you could take a look at the starter code and add a feature to the MiniBrowser or spruce up the GUI.
- Make the Huffman encoding table more efficient: Our implementation of the encoding table at the start of each file is not at all efficient, and for small files can take up a lot of space. Try to see if you can find a better way of encoding the data. If you're feeling up for a challenge, try looking up succinct data structures and see if you can write out the encoding tree using one bit per node and one byte per character!
- Add support for encryption in addition to encoding: Without knowledge of the encoding table, it's impossible to decode compressed files. Update the encoding table code so that it prompts for a password or uses some other technique to make it hard for Bad People to uncompress the data.
- Implement a more advanced compression algorithm: Huffman encoding is a good compression algorithm, but there are much better alternatives in many cases. Try researching and implementing a more advanced algorithm, like LZW, in addition to Huffman coding.
- Gracefully handle bad input files for compressor: The normal version of the provided compression testing program doesn't work very well if you feed it bogus input, such as a file that wasn't created by your own algorithm. Make your code more robust by making it able to detect whether a file is valid or invalid and react accordingly. One possible way of doing this would be to insert special bits/bytes near the start of the file that indicate a header flag or checksum. You can test to see whether these bit patterns are present, and if not, you know the file is bogus.
- Autocorrect: Our implementation of Autocomplete assumed that the user spells the words correctly. Consider implementing a version that autocorrects as well as completes the query, handling some number of user mistakes. You could also try augmenting Autocomplete by keeping track of which queries are the most popular or which queries are likely to follow previous queries, adapting suggestions over time.
- Other: If you have your own creative idea for an extra feature, feel free to ask your SL and/or the instructor about it.
Indicating that you have done extra features: If you complete any extra features, then in the comment heading on the top of your program, please list all extra features that you worked on and where in the code they can be found (what functions, lines, etc. so that the grader can look at their code easily).
Submitting a program with extra features: Since we use automated testing for part of our grading process, it is important that you submit a program that conforms to the preceding spec, even if you want to do extra features. You should submit two versions of each modified program file: for example, a first one named LineManager.cpp without any extra features added (or with all necessary features disabled or commented out), and a second one named LineManager-extra.cpp with the extra features enabled. Please distinguish them by explaining which is which in the comment header. Our turnin system saves every submission you make, so if you make multiple submissions we will be able to view all of them; your previously submitted files will not be lost or overwritten.