Assignment 8: CS106XCell
Based on an assignment by Julie Zelenski and Marty Stepp.
Due: Friday, December 7, 6PM
May be done in pairs

In your last assignment, you will use topological sort and inheritance to build your own spreadsheet program. This assignment also gives you practice with working on a larger-scale project, and adding to an existing codebase. It is a chance to pull together your stellar C++ skills, use a variety of existing classes, design and implement a few new ones, and build an awesome piece of productivity software. It's a wonderful and sophisticated task that is a capstone to all you've done so far.
A significant part of this assignment is the task of looking at a large amount of provided starter code to understand that code and utilize it. We provide code to help with graphics, reading and parsing formulas and expressions, representing ranges of cells, and more. This provided code is useful and powerful, but it does require you to familiarize yourself with that code by reading this document carefully. This spec does not attempt to be an exhaustive guide to every aspect of the provided code, so you will also need to look at the provided files and read their code and comments to understand them further.
Important Files and Links
Note: If the behavior of our demo in any way conflicts with the information in this spec, you should favor the spec over the demo.
Turn in only the following files:
- CS106XCellModel.h/cpp, the C++ code for the class that stores all of the data for the program, such as cells, values, and dependencies; CS106XCellModelTests.cpp to test your implementation
- Expression.h/cpp, the C++ code defining various types of expressions that the user could input; ExpressionTests.cpp to test your implementation
- debugging.txt, a file detailing a bug you encountered in this assignment and how you approached debugging it
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Style
As in other assignments, you should follow our Style Guide for information about expected coding style. You are also expected to follow all of the general style constraints emphasized in the previous homework specs, such as the ones about good problem decomposition, parameters, using proper C++ idioms, and commenting. The following are additional points of emphasis and style constraints specific to this problem:
Graph Usage: Part of your grade will come from appropriately utilizing graphs and graph algorithms. You must represent all spreadsheet and cell data using a single BasicGraph object in CS106XCellModel. You should not declare any other collections as member variables in that class; all spreadsheet/cell data must be stored in the BasicGraph.
Variables: The only private member variable you are allowed to have in CS106XCellModel is your graph of spreadsheet data. You should not declare any other member variables, nor should you declare any static or 'global' variables. You may of course use other local variables as needed to implement each member function's behavior; for example, if you need a temporary collection such as a Set or Vector to help you implement setCell, you are allowed to declare one as a local variable.
Efficiency: We don't list any specific Big-Oh for your various spreadsheet and graph operations. But you should generally try to avoid unnecessary bulky computations, such as recalculating a cell's value when you don't need to do so. You also should try to avoid bulky graph operations that are unneeded, such as looping over every vertex in the graph when really you just want the neighbors of one vertex, for example.
Decomposition: make sure to write short, coherent methods that are easy to understand, and help reduce redundancy.
Memory Usage: Your code should have no memory leaks. Do not allocate dynamic memory (new) needlessly, and free the memory associated with any new objects you allocate internally once they are no longer being used.
You should implement all required member functions exactly as specified, and should not make any changes to the function parameters, name, return type, etc.
Pair Programming
You may optionally work on this assignment as a pair programming assignment. If you would like to work in a pair on this assignment, you may, under the following conditions:
- Both partners must be in the same section (time and location).
- At no time should partners be coding alone. To be clear: all coding must be done together, on a single computer. One partner should type, and the other should watch over that partner's shoulder. Each partner should take turns at the keyboard.
- When you go to the LaIR or office hours for help on your assignment, both students must be present in the pair to receive help. Only one partner should sign up for help in the LaIR Queue at a time.
- Pair programming is less about sharing the workload and more about sharing ideas and working together. During the IG for the assignment, if a Section Leader does not think both partners contributed equally and worked together, the SL may forbid pair programming on a future assignment.
- Pairs who "split the assignment" where one partner does part of the assignment alone, and the other partner does another part of the assignment alone, will be in violation of the Honor Code.
Overview
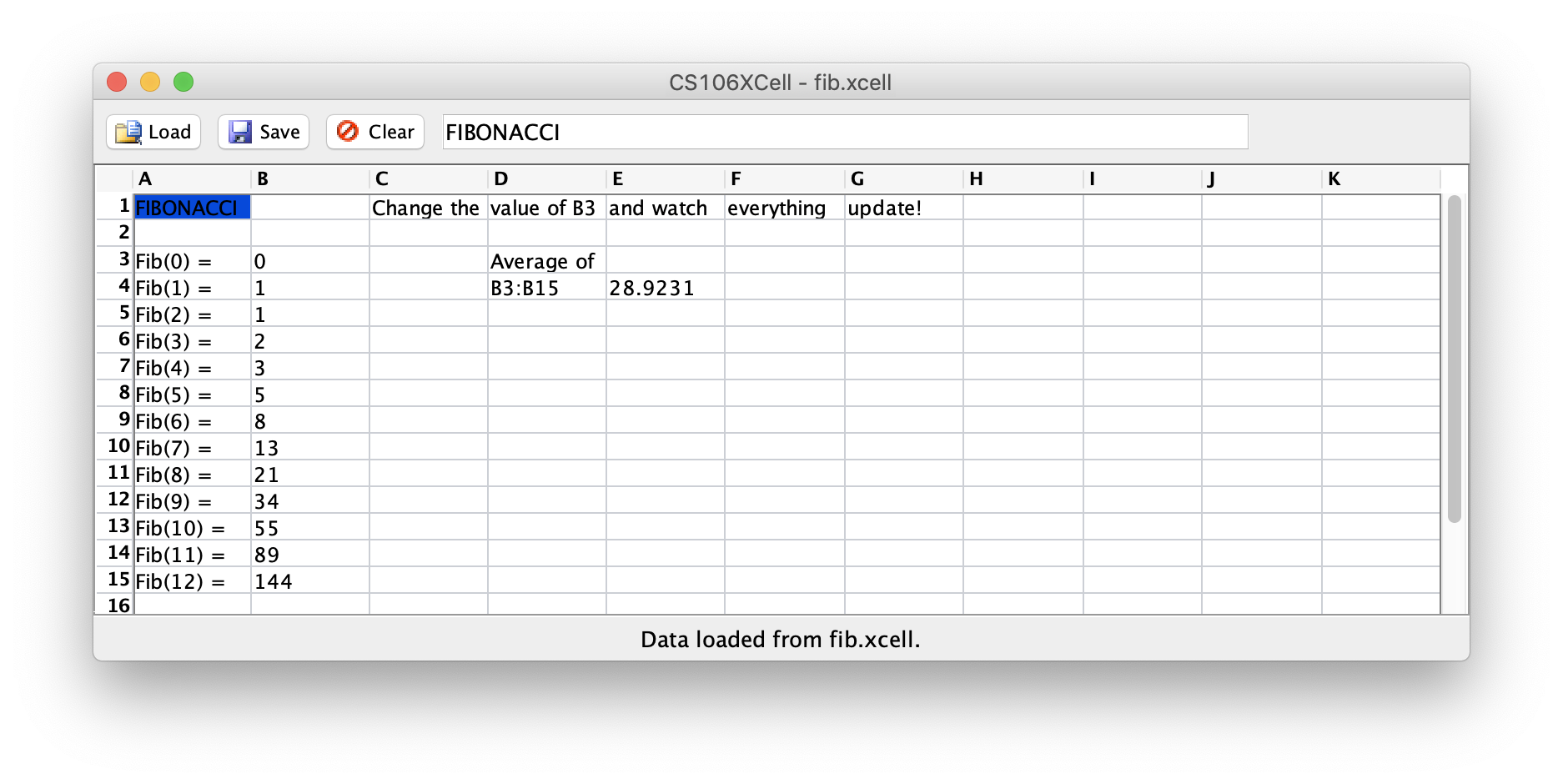
One of the most important commercial programs to emerge from the personal computer revolution was the electronic spreadsheet. The original VisiCalc system was a runaway success for Apple computers in the early 1980s, and many more advanced packages, such as Lotus 1-2-3 and Microsoft Excel, have extended that basic idea so that spreadsheet programs are now used as the basis for a wide range of commercial applications. At its core, a spreadsheet consists of a two-dimensional grid of cells, each indicated by a letter representing a column and a number representing a row. The screenshot below shows a basic budgeting spreadsheet in the CS106XCell program:
screenshot of CS106XCell program displaying budget.xcell
We are used to thinking of two-dimensional grids as having 0-based indexes starting from the top-left. But cell names in a spreadsheet use a letter-number naming system borrowed from Microsoft Excel, with the column written first as a letter, followed by the row written as a 1-based number. For example, the cell name C7 represents row 6 (the number 7 minus one) and column 2 (the letter C being two greater than A). The code in this project contains functions for converting between 0-based row/column indexes and Excel-style cell names.
In the spreadsheet, each cell contains a value, which can be one of the following types:
- a string, such as "Personal" in A6 or "Budgeted" in D1.
- a number, such as the amounts in column B or the budgets in column D. Note that these values can have decimal components and must be represented using type
double. - a formula based on other items in the spreadsheet. For example, cell E2 was set so that its value is calculated by subtracting the value in cell D2 from the value in cell B2. Similarly, cell B8 is the sum of the values in cells B2 through B6.
Also note that when the value of a cell is updated, all cells that depend on it are updated as well. For example, in the screenshot above, if B2 changes, then E2 must update as well (among other cells).
The spreadsheet program is internally structured using the Model/View/Controller (MVC) design pattern favored by modern GUI applications. The model manages the data being stored. A view displays a visual representation of the model. The controller provides the glue that manages both the view and the model and responds to user interactions, such as button presses. The benefit of MVC is that it divides the code into clean areas of responsibility, makes it possible to have multiple views/controllers on the same model, and design program components that are not special-cased to each other (for instance, in this implementation CS106XCellModel and CS106XCellView know nothing of each other). In this case, we supply the controller and the view. The model, CS106XCellModel, is left for you to implement, along with required additions to the Expression class that the model uses to represent expressions.
Here is a more detailed overview of the program structure:
- CS106XCellModel: This class manages the spreadsheet and cell data model, including tracking the contents of different cells and the dependencies between them. We provide a skeletal public interface, and you will provide the class implementation. You will modify this class.
- CS106XCellView: This class provides the graphical spreadsheet display. You should not modify this class.
- CS106XCellController: This class houses the main program, which is responsible for responding to user events and keeping the model and view in sync. You should not modify this class.
- CS106XCellUtil: This class provides useful utility functions to convert between cell names and their row/column indexes. You should not modify this class.
- CellRange: This class represents a set of cells between a start and end cell (e.g. B1:B5). This is useful for representing range formulas such as "=AVERAGE(B1:B6)". It can also validate the supported function names (such as AVERAGE, MEDIAN, etc.) in our program, and contains functions for the range formulas (
average,min, etc.) You will need this file to implement the Range type of expression. You should not modify this class. - Expression: This class represents a mathematical expression and is used to evaluate the values typed into cells. This class is mostly provided to you, but you must add a new type of expression (
RangeExp), and implement theevalmethod for each of the expression types which calculates its resulting value. You will modify this class. - ExpressionParser: This class provides a function that can convert text into an
Expression. You will need this file to convert between the text that the user enters and actual expressions that can be calculated. You should not modify this class. - CS106XCellModelTests/ExpressionTests: These files contain unit tests for the model and expressions, respectively. We provide a few tests to get you started, and you will add additional tests to verify your implementations. You will modify this class.
- TestDriver: This class provides the test harness for running your unit tests. You should not modify this class.
- Main: This file contains the
main()method that runs either the main spreadsheet program or the test harness, depending on the user's selection. You should not modify this class.
Unit Testing
For both the model and expression classes, we have included a unit testing file containing some starting tests. These files are CS106XCellModelTests.cpp and ExpressionTests.cpp. You can run these unit tests by running the main program and selecting the tests you want to run on the launch popup.
For the expression class, you should add at least 6 additional tests for the functionality that you implement. For the model class, you should add at least 6 additional tests for the functionality that you implement. Make sure that your unit tests test as small, isolated components of your code as possible. Make sure to give each test a detailed name, and comment above it explaining what it is testing.
Also remember to turn in debugging.txt, explaining a bug you encountered, how you identified it, and how you fixed it. You can find this file in the res/ folder of the starter project.
Range Expressions
Your first task is to read through the provided Expression class to understand its behavior, inheritance hierarchy, and implementation. Here is an overview of the public functionality for every Expression:
Expression member |
Description |
|---|---|
eval(cellValues)
|
Evaluates the given expression recursively and returns the calculated result as a |
getRawText()
|
Returns/sets the raw text that was used to parse this expression, such as |
getType()
|
Returns the type of this expression, which will be one of the following:
|
getValue()
|
Returns as a |
isFormula()
|
Returns |
toString()
|
Returns a text representation of the formula.
For example, for an identifier expression, returns the identifier such as |
Expression class hierarchyThe expression objects are organized into a binary tree such as the following one for the formula, "=A1/2+7.5*SUM(B3:B7)" . Notice that expressions have operator precedence, so that the + operation is at a higher level in the tree than the * and / operations. However, our provided parser takes care of this.
CompoundExp: operator="+"
|
+-- left=CompoundExp: operator="/"
| |
| +-- left=IdentifierExp: name="A1"
| |
| +-- right=DoubleExp: value=2.0
|
+-- right=CompoundExp: operator="*"
|
+-- left=DoubleExp: value=7.5
|
+-- right=RangeExp: function="SUM", range=B3:B7
"=A1/2+7.5*SUM(B3:B7)"
The expressions are thus represented as an inheritance hierarchy of classes that extend Expression to add various specific behavior for each kind of expression such as compound, text string, and so forth. For instance, the Compound Expression type provides getters for the left and right subexpressions. We won't document all the functions here, but you should familiarize yourself with the different functionality available for each expression type, and how it is implemented. This will come in handy for implementing the new Range Expression type, described below.
Some parts of your code on this assignment will need to use getType to figure out what type of expression you are using so that you can utilize the unique features of that expression:
Expression* exp = ...; // get a pointer to an expression object
if (exp->getType() == COMPOUND) {
const Expression* left = ((const CompoundExp *)expr)->getLeft();
const Expression* right = ((const CompoundExp *)expr)->getRight();
...
} else if (exp->getType() == RANGE) {
CellRange range = ((RangeExp *)expr)->getRange();
...
} else {
...
Note that for the left and right subexpressions, getLeft and getRight return const pointers to expressions (so that no-one modifies them). For this reason, you may have to cast using const, as shown above.
Implementing RangeExp
Once you familiarize yourself with the existing Expression hierarchy, you should add a new expression type, called RangeExp, to this existing hierarchy. We don't provide any boilerplate code for this class - you should create and add it to Expression.h/.cpp. This type represents functions applied to a range of cells - for example, "AVERAGE(A1:A5)" specifies that a cell should contain the calculations of the average value of cells A1, A2, A3, A4 and A5. Specifically, a range represents a set of cells between a start and end cell inclusively. Ranges are specified in START:END format indicating the start/end cells, inclusive, such as A1:A6 or B4:H4. A range can span just one row or column or enclose a two-dimensional rectangular block of cells. Thus, ranges like A1:A4, C5:C5, A4:D4, and B2:D6 are valid. One thing to note is that a valid range is required to be non-empty, which means the end cell must be at position greater than or equal to the row and column of the start cell.
Your class will need to provide implementations of existing Expression methods described above, and also add its own unique behavior. Here is the behavior you should implement:
- Constructor: a
RangeExpshould be able to be created by specifying the name of the function to apply (such as "AVERAGE", "MIN", etc.) as a string, and the range of cells over which to apply this function as aCellRangeobject. The function name and the cell range should be able to be provided in any case (upper, lower, mixed, etc.). - a
RangeExpis always a formula - the type of a
RangeExpisRANGE(a provided constant) - a
RangeExp'stoString()method should return a string representation of the expression in the format "FUNCTION(RANGE)" (e.g. "AVERAGE(B1:B6)"). - it should have a public method
getFunction()that returns the value of its function name, in all uppercase. - it should have a public method
getRange()that returns the value of its cell range - All other behavior should be identical to a regular
Expression
We leave the remainder of the class design, such as what private members it will have, up to you.
The CellRange class, which you will need to use in your implementation, contains the following public members:
CellRange member |
Description |
|---|---|
CellRange(startRow, startCol, endRow, endCol)
|
You can create a new range by specifying either the indices of the start/end row/column, or by specifying the names of the start and end cells (e.g. "A1"). You likely won't need to create any new ranges in your code, however, as the parser code handles this for you and just passes the ranges it creates to your Range Expression constructor. |
getStartCellName()
|
This member function returns the name of the starting or ending cell in the range, such as |
getStartRow()
|
This member function returns 0-based row or column of starting or ending cell in range,
such as row 4, column 2 for |
toString()
|
The |
getAllCellNames()
|
This function returns a set containing the names of all cells in this range. For example, if the range is B3:C5, this returns the set containing {"B3", "B4", "B5", "C3", "C4", "C5"}. |
CellRange::isKnownFunctionName(function)
|
This static function returns true if the given function name is one of the known names of range functions (e.g. "AVERAGE", "MIN", etc.). For example, |
CellRange classFinishing Up
Our ExpressionParser class (which you will use in later steps) already contains code to parse out Range Expressions that you can activate when you are done implementing the class behavior above. To do this, in Expression.h, change the line at the top #define RANGE_IMPLEMENTED false to #define RANGE_IMPLEMENTED true. Until you do this, the parser will treat range expressions as unknown expressions and throw an error. Note that you must implement the constructor exactly as specified above, with the first parameter being the function name (string), and the second parameter being the cell range (CellRange). You should not need to modify ExpressionParser.
Once you finish this part of the assignment, try writing tests in ExpressionTests.cpp to test your implementation. You should ensure your implementation is correct before moving on.
Expression Evaluation
Your next task is to implement the eval() method on each of the types of expressions, both the provided ones and your new RangeExp type. This method calculates the numeric value for the expression it is called on, stores it as its value (using setValue()) so that you can retrieve the value later using getValue() without recalculating it, and returns the calculated value. Note that setValue(value) is a private method in Expression (if you're interested, you are able to use it within eval because all Expression subclasses are friends of the base class, though you don't need to worry about this). You need to write the logic to walk the expression binary tree to calculate its resulting value. Note that this is an inherently recursive process, because expressions can contain other sub-expressions as children. In particular, compound expressions represent a binary operation such as "=A2+SUM(B1:B7)". In the case of this example, the left child would be an identifier expression representing A2 and the right child would be a range expression representing SUM(B1:B7).
Because expression evaluation may depend on the value of other cells in the spreadsheet, eval() takes one parameter, which is a map containing cell names (keys) and their calculated values (values) currently in the spreadsheet. The cell names will be in all uppercase, and if a cell is not included in the map it is assumed to have value 0. Note that formulas should be case insensitive. The string "a1" should be equivalent to "A1", and "=sum(a4:BcF17)" should be equivalent to "=SUM(A4:BCF17)".
The default implementation of eval for each included expression just returns 0.0 until you modify the code to properly evaluate the expression. Here is how to evaluate each type of expression:
| Expression type | How to evaluate (eval) |
|---|---|
DoubleExp
|
This is just the cell's numeric value itself. |
TextStringExp
|
This is |
IdentifierExp
|
This is the value of the cell to which the expression refers.
For example, if the identifier is "A3", you should find the value of cell A3.
If the identifier refers to an invalid cell, you should throw an error.
(Hint: the |
RangeExp
|
This is the result of applying the given kind of function to the given range of cells.
For example, if the cell's raw text is
The function names that you must support are
If the function name referred to is not known, you should throw an error.
(Hint: the |
CompoundExp
|
This is the result of applying the given binary mathematical operator to the given operands.
For example, if the cell's raw text is
The operators that you must support are
If an operator specified is not one of these, you should throw an error. (Hint: the |
Once you finish this part of the assignment, try writing tests in ExpressionTests.cpp to test your implementation. Remember to both return the calculated value and store it in the expression itself using setValue. You should ensure your implementation is correct before moving on.
The Model
Next up, we are going to implement CS106XCellModel, the class that stores information for each cell, including its expression and dependencies. It relies on the Expression classes you have implemented already to store the expressions, and graph algorithms to relate them. Note that you must store all cell data in this class using a single instance of the BasicGraph library collection class. You should not declare any other collections as member variables in your class; all spreadsheet/cell data must be stored in the BasicGraph. See further down the page for more information about the graph data structure.
In your graph, each vertex represents a cell that stores a value. (Cells whose values have not yet been set, or whose values are empty, need not be represented in the graph.) An edge from vertex A → B implies that the value of cell B depends on the value of cell A. For example, the following is a diagram of the appropriate graph state to represent the contents of provided input file simple.xcell. Note that the graph is not necessarily connected; vertexes A1 and B3 have no inbound or outbound edges.
A1 Testing A2 10 A3 =A2+1 B1 =A3*2 B2 =A2+A3+B1 B3 =1+2-3+4*5/6
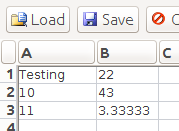
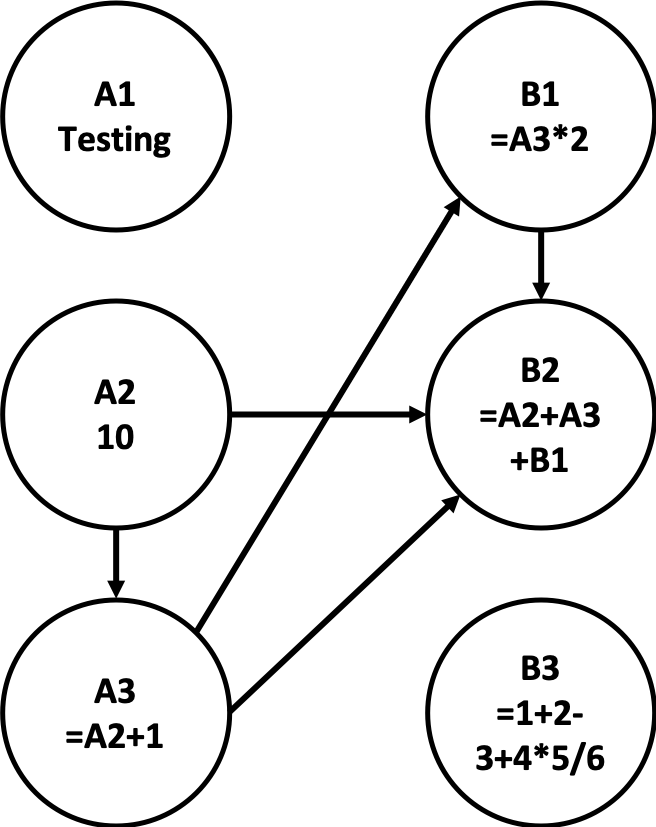
Your implementation must have the following public members listed in the table below. Of course you can and should add extra "helper" functions as needed to help you implement the behavior properly and to decompose it into readable chunks of code. Any member functions you add, along with all private member variables, must be declared private, and const as appropriate.
CS106XCellModel member |
Description |
|---|---|
CS106XCellModel()
|
In this constructor you should initialize a new empty model. |
~CS106XCellModel()
|
In this destructor you should free all dynamically allocated memory for your model. This includes any memory in your graph and cell data. |
clear()
|
In this member function you should wipe out any stored values and cell data in the spreadsheet.
After a call to The GUI calls this function when the Clear button is pressed. |
load(input)
|
In this member function you should read spreadsheet data from the given input stream ( This function is called by the GUI when the user clicks the Load button.
Assumptions:
You may assume that the input file exists, is readable, and is in the proper format described in this spec, with no blank lines or extraneous/invalid data.
You may not, however, assume that every formula in the cell is perfectly valid.
For example, a formula might refer to a non-existent cell or contain a circular reference.
If so, throw an Before you read the new data into your spreadsheet, you must free any dynamically allocated heap memory for any previous cells that were in the spreadsheet beforehand. Do not leak any memory from this function. |
save(output)
|
In this member function you should write your model's data to the given output stream ( This function is called by the GUI when the user clicks the Save button. Assumptions: You may assume that the stream passed is in a valid state for writing, that the file is writable, and that the disk has enough space to save the data in your spreadsheet. |
setCell(cellname, value)
|
In this member function you should set the cell with the given name to use the given string (which could be text, a number, or a formula) as its raw text value.
A cell name will be a string such as This function is called by the GUI whenever the user finishes typing a new value into the graphical view of the table, or when the user types a value into the top cell formula editor field and presses Enter. The graphical table already lets the user edit cells' values, but the instant the user is done editing, the value goes away.
You don't need to write the logic for parsing and evaluating formulas and expressions from scratch. Instead, you should use the provided string rawText = "=A1/2+7.5*SUM(B3:B7)"; Expression* exp = ExpressionParser::parseExpression(rawText); ...Note that this allocates memory on the heap using new, and you must free up this memory yourself when you are done with the expression later.
As part of updating a cell, you must also update the calculated values of any other cells containing formulas that depend on the value of that cell. See the later section on "Dependencies" for more. The following types of formula expressions contain the following kinds of dependencies:
Note that your spreadsheet's internal graph contains edges from vertex A → B when cell B's formula depends on cell A's value.
If the formula in a cell changes, you should update the inbound edges of that cell to reflect its new dependencies. (Note: the
Case sensitivity:
Your program should be able to properly set cell values case-insensitively, even if cell names or formulas are not in uppercase.
For example, the value
If either the cell name or value is invalid or malformed, you must throw an Note: This function is the most challenging one to implement. |
getExpressionForCell(cellname)
|
In this member function you should return a pointer to the expression stored in the provided cell. If this cell is invalid, or if it is empty, this method should return The GUI calls this function when displaying content for each cell. |
CS106XCellModel class (you must write these)
One important part of the model is that it must update the rest of the program whenever the contents of a cell change. The way the model can do this is by calling the notifyObservers(cellname) function and passing in as a parameter the (uppercased) name of the cell whose content updated. For example, if the model just updated the contents of cell A2, then you would want to do something like notifyObservers("A2");. This sends out an "alert" in the program that a cell's contents have changed. The controller will be listening for these alerts, and will re-display that cell in the view when it receives one. Make sure to take this extra step when you are clearing cells, updating cells, or updating dependent cells, or else nothing will display in the view.
Graph Data Structure
In this case, unlike with a regular BasicGraph that we have already seen, we also want to store cell data (the Expression object for that cell) inside each vertex of the graph. Associating data with each vertex will be useful when implementing various cell and spreadsheet algorithms. BasicGraph supports this; to store auxiliary data inside each Vertex, you should declare your graph in a different way than what we have seen in class.
// graph with a pointer to an Expression structure stored as data in each vertex
BasicGraphV<Expression*> cellGraph;
If you declare your graph this way, the vertex structure for each vertex in the graph is now called VertexV and will now require a template parameter of Expression* whenever it is used. Similarly, each edge in the graph is now called EdgeV and will also now require a template parameter of Expression* whenever it is used.
In return for the bulkier syntax, each vertex structure will contain a useful member variable of type Expression* named data, whose value is initially nullptr until you change it for a given vertex.
To access this member, you can write code such as the following:
// accessing a single vertex and its associated expression data
VertexV<Expression*>* v = cellGraph.getVertex("V47");
if (v->data != nullptr) {
...
}
Similarly, to access the neighbors of a given vertex, you would write the following:
// accessing all neighbors of a vertex
// (all other vertexes Vi such that there is an edge V47 -> Vi)
for (VertexV<Expression*>* neighbor : cellGraph.getNeighbors("V47")) {
Expression* exp = neighbor->data;
...
}
File Format
The files you must read into your spreadsheet store cell data in the following format. Each line contains the data for a single cell. A line contains a cell name such as "A4", a single space, and then the cell's raw text/formula. For example, the following is the text of input file simple.xcell:
A1 Testing A2 10 A3 =A2+1 B1 =A3*2 B2 =A2+A3+B1 B3 =1+2-3+4*5/6
If your program loaded this file, the spreadsheet would display the following data:

Your program should be able to properly load data from files case-insensitively, even if cell names or formulas are not in uppercase.
Note that if you try to open a spreadsheet such as simple.xcell or myspreadsheet.xcell, Qt Creator will display it in a "hex editor" that is meant for editing binary files. This is not an ideal view for looking at our spreadsheet files, which are stored as plain text. To view the file properly, you can either temporarily change the extension to .txt or use another text editing program such as Notepad, TextEdit, or Sublime Text, among others.
Due to various calculations, it may take a few seconds to load a file from disk; this is ok.
Dependencies
One of your greatest challenges is dealing with cell formulas and dependencies. The trickiness comes from the fact that changing a value in one cell may start a chain reaction of updates. A cell that refers to another cell in its formula is said to be dependent on that cell. If the value in a cell is changed, the cells that depend on it also must be updated. Dependencies can either be direct (where a cell has an explicit reference to another in its formula), or indirect (where a cell has a chain of references that eventually lead to that cell). Consider the following spreadsheet data, which comes from provided input file example1.xcell:
A1 42 B1 =A1*2 C1 =B1+5 D1 =C1/B1 E1 =SUM(C1:D1) F1 =G1+1 G1 7 H1 19
In this data, B1 directly depends on A1, C1 directly depends on B1, D1 directly depends on B1 and C1, and E1 directly depends on C1 and D1, and F1 directly depends on G1. Both C1 and D1 indirectly depend on A1 (through B1), and E1 indirectly depends on A1 and B1. You can visualize the dependencies as a directed graph, as shown below:
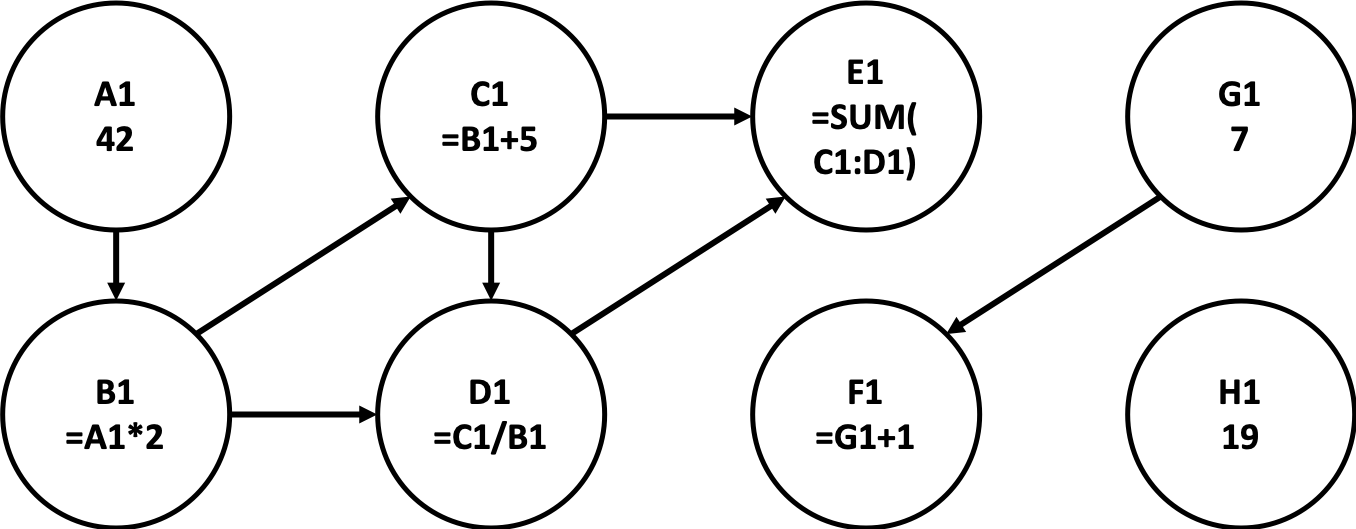
In this graph, the edges trace the direction of outgoing dependencies. The same edges in reverse show the incoming dependencies. For example, when A1 changes, it needs to propagate an update to B1 because the formula for B1 directly references A1. Indirect dependencies are those cells connected through a longer path. D1 indirectly depends on A1, since it relies on B1, which in turn relies on A1. This indirect dependency is represented as a path of edges from A1 to D1.
When the value of a cell is updated, you must update all cells that depend on it, either directly or indirectly. Looking at the outbound edges touching A1, you can see that changing the value in A1 will require four other cells to be updated. Changing F1, on the other hand, requires no changes to any other cells, since it has no cells that depend on it. The cell G1 also has nothing that depends on it, and it is not affected by changes to any other cells.
Traversing the dependent cells sounds suspiciously like depth or breadth-first traversal of the graph. However, a version like this might update some cells multiple times because there is more than one path between them (consider how D1 could be updated twice when traversing from A1). For that reason, you must use topological sort to efficiently order the cell updates so that each dependent cell is updated at most once, only after its dependents have been updated. Even with this topological ordering, however, you should be sure to still only re-calculate cells that need to be updated when a given cell changes.
Before assigning a new formula to a cell, you should ensure it will not create a cycle (also called a circular reference or circular dependency in this context). For example, what if the user tried to set A1 =A1? To calculate the value of A1, you need the value of A1, but you don't know what it is because you're still trying to calculate it! This kind of dependency is called a circular reference, and is bad news in a spreadsheet. Similarly, if the formula for B2 were =SUM(A2:E2), that range contains B2 itself, so this is a circular reference.
The more sneaky form of circular reference is via an indirect reference not visible in the formula itself. For example, consider if the user tried to set A1 =F1+E1 in the above graph. The two cells directly referenced by the formula are F1 and E1. If we examine the arcs leading to E1, and find that it directly depends on C1 and D1. When we continue our recursive traversal, we eventually run into A1, which is a cycle. So the formula is disallowed because it is circular.
You can examine the neighbors (what depends on it) of a given vertex by using the graph's getNeighbors member function.
In some situations in this program, you may find that you want to loop over neighbors or edges the opposite way, from a cell A to every other cell B that it depends on.
To do so, use the graph's getInverseNeighbors or getInverseEdgeSet member functions, which let you access nodes with an edge to this node, or the edges themselves, respectively. See the library documentation for more information.
Breaking It Down
This is the most difficult part of this assignment, and for this reason we highly encourage you to break it down into steps. One recommended approach could be the following:
- Familiarize yourself with the starter code. Look at the various .h files to understand what functions are available. Hopefully you won't need to look at the provided .cpp files since you generally shouldn't need to know the implementation details if our documentation and comments are detailed enough.
-
Build a basic graph. Create your
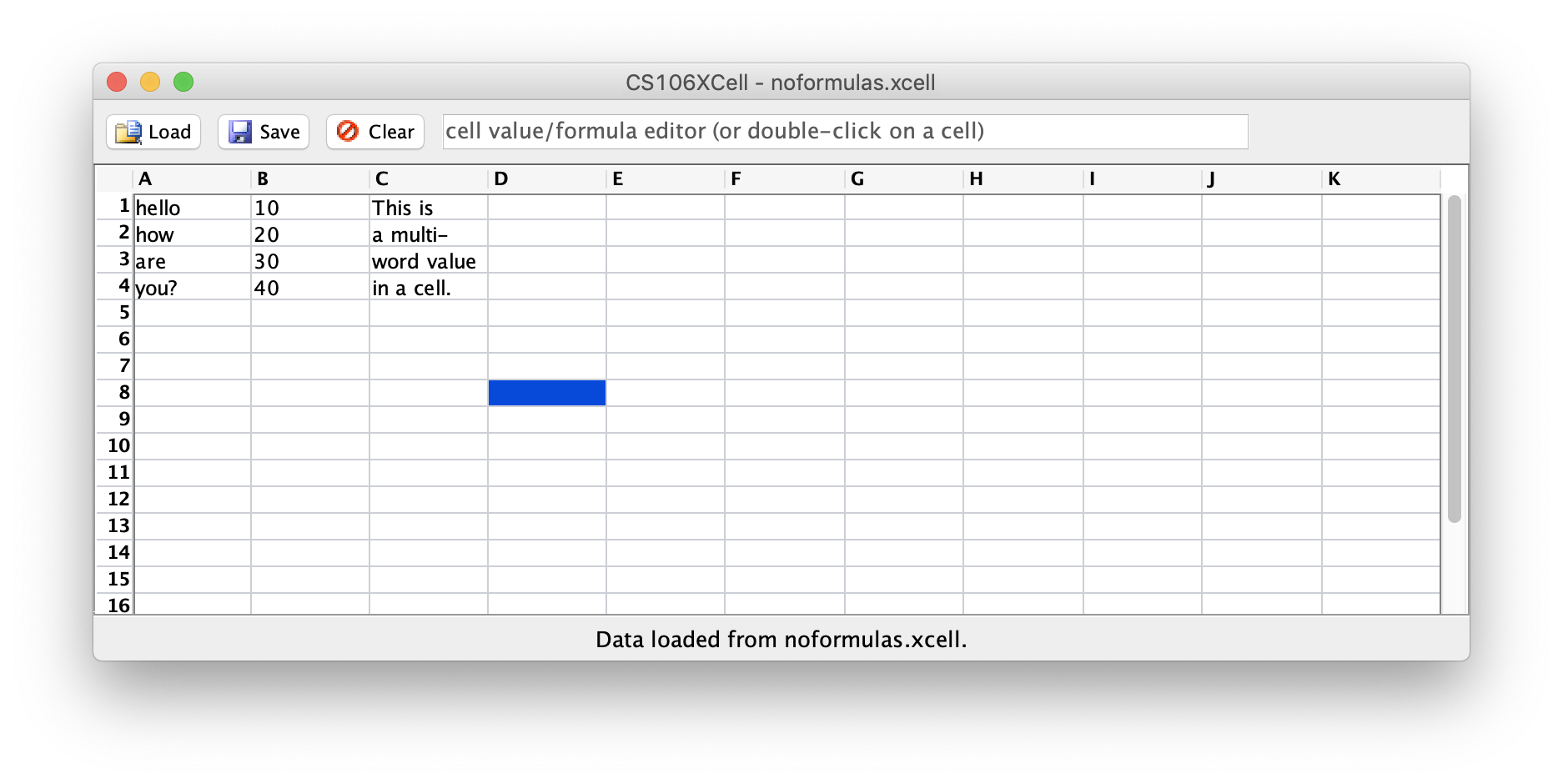
BasicGraphof cell vertex data. When the user sets cell values, parse the raw text into anExpressionobject and store this in each vertex. Print your graph to the console to see its state. Don't worry about files or dependencies just yet. - Handle saving and loading of simple files. You don't need to save/load formulas with dependencies yet, but get the basic logic working to read the data from the lines of a file and add it to your graph. We provide an input file named noformulas.xcell that contains cells with just basic text and numbers without any formulas or dependencies; test with that first.
- Handle dependencies in the graph structure. Finish your
setCellimplementation to handle dependencies between cells and updates to existing cells' values.
Writing unit tests to verify your functionality as you go is a crucial way to ensure your implementation works correctly.
Possible Extra Features
Here are some ideas for extra features that you could add to your program. Note that since we use automated testing for part of our grading process, it is important that you submit a program that conforms to the preceding assignment spec, even if you do extra features. You should submit two versions of your program for extensions: the provided one without any extra features added, and a second one with extra features. Please distinguish them by explaining which is which in the comment header. In the comment header, please also list all extra features that you worked on and where in the code they can be found (what functions, lines, etc. so that the grader can look at their code easily).
- Cell formatting: Introduce features to format the font, color, and/or alignment of given cells, rows, or columns. See
gtable.hfor function headers related to formatting cells, and call these members at appropriate time to format your spreadsheet. You will need to modify the provided GUI to give a user interface for such features. - Undo/redo: A real spreadsheet program would have an Undo feature to revert the last change made to the spreadsheet. Modify our provided GUI to either have an Undo/Redo button, and/or have a hotkey such as Ctrl-Z, to undo the last modification to the table. Try to make as many actions "undoable" as you can, such as setting a cell, clearing the spreadsheet, and so on. (Most apps implement undoable actions using a stack, so that you can pop the last state or action as needed.)
- Smart cut/copy/paste: Make it so that if you copy/paste a range of cells, the formulas will update based on the movement of the selection. For example, if you copy a formula of "=SUM(A2:A10)" and paste it two cells to the right, the formula should change to "=SUM(C2:C10)". (In Excel, you can disable this behavior for a given formula using dollar signs, such as "=SUM($A2:$A10)". Can you make your spreadsheet do the same?)
- Ability to select rows, columns, and ranges: By default, the table provided allows the user to select only a single cell. Change your program so that larger ranges can be selected, such as entire rows or columns, or rectangular ranges. When the user presses a key, such as copy/paste or Delete, make the given operation apply itself to the entire selected area.
- Other: If you have your own creative idea for an extra feature, go for it! Feel free to ask your SL and/or the instructor about it.
FAQ
-
Q: What does this error mean when I am trying to evaluate expressions?
'this' argument has type 'const Expression', but function is not marked const
-
A: This can occur when you are trying to access the left/right members of a Compound expression using the
getLeftandgetRightmember functions, rather than directly by referring to the private member variableslhsandrhs. Try doing the latter. -
Q: Does calling
removeVertexfree the memory for theExpression*that is stored inside the vertex as its 'data'? Is it safe to assume that the destructor forVertexVtakes care of all memory inside of it? -
A: No, the vertex does not free this memory by itself.
You must free it.
This is because
VertexV<T>can accept any type forT, even non-pointers. So the code forVertexVcan't say 'delete' because its data may not really be a pointer. - Q: Does our output file need to match the expected one exactly, including line order? For example, if a column has at least 10 lines, my code outputs the lines for the cells in order A1, A10, A11, A2, etc., because that is what C++ considers to be alphabetical order. Is this acceptable for the output file?
- A: Yes; the order of the cells in the file does not have to be strictly alphabetical.
- Q: If I set a cell to "=A1+A1000", should I throw an error, because A1000 is not in the spreadsheet? The demo does not throw an error, and appears to treat A1000 as a valid, but uninitialized cell.
- A: If a formula refers to a cell that is off the spreadsheet by being too far right/down, such as A1000, you should allow it. The cell will be blank and will have a value of 0.