CCA#
Download#
Canonical correlation analysis#
For a data matrix \(X \in \mathbb{R}^{n \times p}\) with \(X_i \overset{IID}{\sim} F\), PCA and Factor Analysis can be thought of as models / decompositions of
Canonical correlation analysis deals with pairs \(\mathbb{R}^p \times \mathbb{R}^q \ni (X_i, Y_i) \overset{IID}{\sim} F\) and models / decomposes the cross-covariance matrix
First goal:
Example from here
\(X\): psychological variables:
(Control, Concept, Motivation)\(Y\): academic + sex:
(Read, Write, Math, Science, Sex)
#| echo: true
mm = read.csv("https://stats.idre.ucla.edu/stat/data/mmreg.csv")
head(mm)
dim(mm)
| locus_of_control | self_concept | motivation | read | write | math | science | female | |
|---|---|---|---|---|---|---|---|---|
| <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <int> | |
| 1 | -0.84 | -0.24 | 1.00 | 54.8 | 64.5 | 44.5 | 52.6 | 1 |
| 2 | -0.38 | -0.47 | 0.67 | 62.7 | 43.7 | 44.7 | 52.6 | 1 |
| 3 | 0.89 | 0.59 | 0.67 | 60.6 | 56.7 | 70.5 | 58.0 | 0 |
| 4 | 0.71 | 0.28 | 0.67 | 62.7 | 56.7 | 54.7 | 58.0 | 0 |
| 5 | -0.64 | 0.03 | 1.00 | 41.6 | 46.3 | 38.4 | 36.3 | 1 |
| 6 | 1.11 | 0.90 | 0.33 | 62.7 | 64.5 | 61.4 | 58.0 | 1 |
- 600
- 8
Substituting \(u=\Sigma_{XX}^{1/2}a, v=\Sigma_{YY}^{1/2}v\) we see that \((u, v)\) solve
So \(u=U[,1]\) and \(v=V[,1]\) are leading left and right singular vectors of \(\Sigma_{XX}^{-1/2}\Sigma_{XY}\Sigma_{YY}^{-1/2}= U \rho V^T\) with \(\rho=\text{diag}(\rho_1, \dots,\rho_q)\).
Achieved maximal correlation value is the leading singular value \(\rho_1\).
Practically speaking, can find SVD by eigendecomposition of the symmetric matrix
Loadings \(a=\Sigma_{XX}^{-1/2}u, b=\Sigma_{YY}^{-1/2}v\) determine first canonical variates \((a^TX, b^TY)\) with
Let’s call \(a=a_1, b=b_1\) for first canonical variates.
Why not find more?
Second canonical variate problem:
subject to \(\text{Cov}_F(a_1^TX,a_2^TX)=\text{Cov}_F(b_1^TY, b_2^TY)=0\).
Not hard to see that \(a_2=\Sigma_{XX}^{-1/2}U[,2], b_2=\Sigma_{YY}^{-1/2}V[,2]\).
Realized correlation is \(\rho_2\).
Continuing
Final form of covariance matrix
Assuming non-singular covariances, when \(p > q\)
transposing when \(p \leq q\).
Generative model#
Several ways to realize the law… here is one
Pick \(\bar{U} \in \mathbb{R}^{p \times p}\) be orthonormal with first \(q\) columns equal to \(U\).
Sample version#
Simply replace \(\Sigma\) with \(\widehat{\Sigma}\).
Under non-degeneracy assumptions, matrices \(\widehat{\Sigma}_{XX}\) and \(\widehat{\Sigma}_{YY}\) will be invertible if \(n > \text{max}(q,p)\).
As in PPCA, Bach & Jordan (2006) show that sample estimates are MLE for this generative model
\(\implies\) could use likelihood to choose rank…
#| echo: true
library(CCA)
X = mm[,1:3]
Y = mm[,-c(1:3)]
CCA_mm = CCA::cc(X, Y)
names(CCA_mm)
Loading required package: fda
Loading required package: splines
Loading required package: fds
Loading required package: rainbow
Loading required package: MASS
Loading required package: pcaPP
Loading required package: RCurl
Loading required package: deSolve
Attaching package: ‘fda’
The following object is masked from ‘package:graphics’:
matplot
Loading required package: fields
Loading required package: spam
Spam version 2.11-1 (2025-01-20) is loaded.
Type 'help( Spam)' or 'demo( spam)' for a short introduction
and overview of this package.
Help for individual functions is also obtained by adding the
suffix '.spam' to the function name, e.g. 'help( chol.spam)'.
Attaching package: ‘spam’
The following objects are masked from ‘package:base’:
backsolve, forwardsolve
Loading required package: viridisLite
Try help(fields) to get started.
- 'cor'
- 'names'
- 'xcoef'
- 'ycoef'
- 'scores'
Checking CCA solution#
#| echo: true
crosscov = cov(mm)[1:3,4:8]
t(CCA_mm$xcoef) %*% crosscov %*% CCA_mm$ycoef
CCA_mm$xcoef
| 4.640861e-01 | 5.599087e-17 | -1.930228e-16 |
| 3.610083e-16 | 1.675092e-01 | -3.725764e-16 |
| 4.012970e-16 | -5.498621e-16 | 1.039911e-01 |
| locus_of_control | -1.2538339 | -0.6214776 | -0.6616896 |
|---|---|---|---|
| self_concept | 0.3513499 | -1.1876866 | 0.8267210 |
| motivation | -1.2624204 | 2.0272641 | 2.0002283 |
Diagonalizes the \(X\) and \(Y\) subblocks#
#| echo: true
Xcov = cov(mm)[1:3,1:3]
t(CCA_mm$xcoef) %*% Xcov %*% CCA_mm$xcoef
| 1.000000e+00 | 2.478633e-16 | 2.048775e-16 |
| 3.413977e-16 | 1.000000e+00 | -1.345034e-16 |
| 2.169002e-16 | -1.469862e-16 | 1.000000e+00 |
#| echo: true
Ycov = cov(mm)[4:8,4:8]
t(CCA_mm$ycoef) %*% Ycov %*% CCA_mm$ycoef
| 1.000000e+00 | -1.975726e-16 | 2.677851e-17 |
| -1.686276e-16 | 1.000000e+00 | -4.013920e-15 |
| -1.444754e-17 | -4.112697e-15 | 1.000000e+00 |
#| echo: true
plot(CCA_mm$scores$xscores[,1], CCA_mm$scores$yscores[,1])
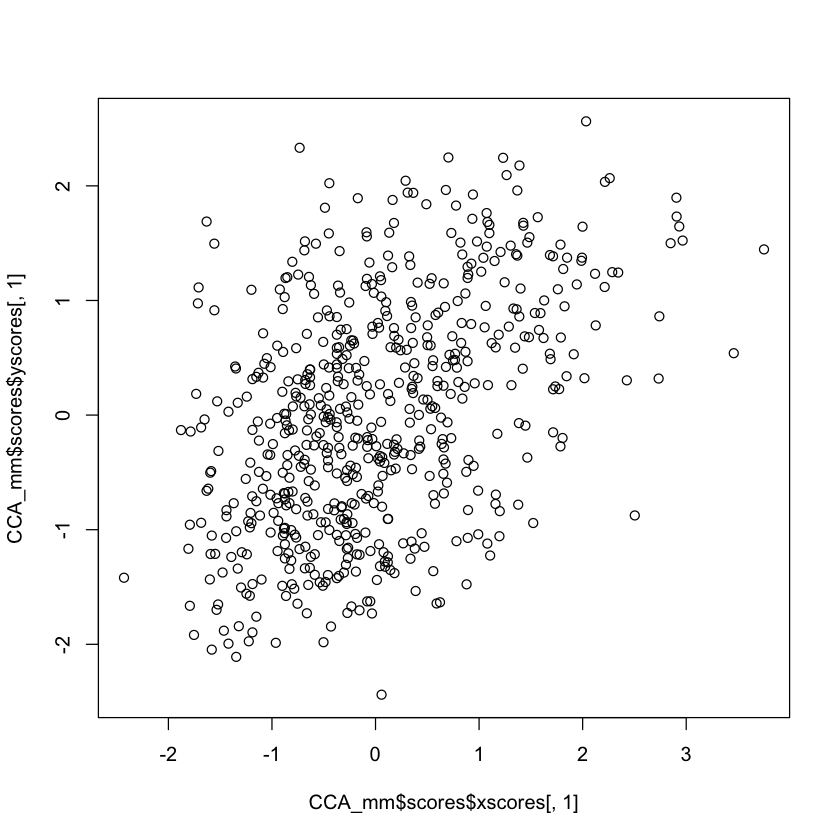
Invariance under non-singular transformations#
Clearly the CCA decomposition is invariant under change of means of \((X, Y)\).
The matrix
is also invariant under non-singular transformations (of \(X\) or of \(Y\))
\(\implies\) CCA is affine equivariant…
#| echo: true
CCA_mm_scaled = CCA::cc(scale(X, TRUE, TRUE), scale(Y, TRUE, TRUE))
cbind(CCA_mm$cor, CCA_mm_scaled$cor)
lm(CCA_mm$scores$xscores[,1] ~ CCA_mm_scaled$scores$xscores[,1])
| 0.4640861 | 0.4640861 |
| 0.1675092 | 0.1675092 |
| 0.1039911 | 0.1039911 |
Call:
lm(formula = CCA_mm$scores$xscores[, 1] ~ CCA_mm_scaled$scores$xscores[,
1])
Coefficients:
(Intercept) CCA_mm_scaled$scores$xscores[, 1]
9.15e-16 1.00e+00
#| echo: true
A = matrix(rnorm(9), 3, 3)
XA = as.matrix(X) %*% A
CCA_affine = CCA::cc(XA, Y)
cbind(CCA_mm$cor, CCA_affine$cor)
lm(CCA_mm$scores$xscores[,1] ~ CCA_affine$scores$xscores[,1])
| 0.4640861 | 0.4640861 |
| 0.1675092 | 0.1675092 |
| 0.1039911 | 0.1039911 |
Call:
lm(formula = CCA_mm$scores$xscores[, 1] ~ CCA_affine$scores$xscores[,
1])
Coefficients:
(Intercept) CCA_affine$scores$xscores[, 1]
-7.066e-15 1.000e+00
Relation to reduced rank regression#
For each of \(X\) and \(Y\), we saw that there are mappings
to unitless canonical variates.
These canonical variates drive the correlation between \(X\) and \(Y\)…
Reduced rank regression for rank \(k \leq \text{min}(p, q)\)#
Due to affine equivariance, it’s not hard to see that
Inference: how to test \(\rho_j=0, j \geq k\)?#
Complicated joint densities…
Not too hard under global null \(H_0:\Sigma_{XY}=0\), though these tests will all look like tests for regression \(Y\) onto \(X\).
Under global null \(H_0: X \ \text{ independent of} \ Y\) could permute either \(X\) or \(Y\)…
Generalizations#
For non-Euclidean data we might featurize either \(X\), \(Y\) or both.
This idea shows up over and over: given features \(X\), make new features through a basis expansion (which include the kernel trick).
We see this in two-sample tests (e.g. in the kernelized versions); linear regression; kernel PCA; etc.
Wherever we form random variables like \(\beta^TX\), we can replace with \(W=f(X)\) …
Often, methods with richer (i.e. more) features will also feature a regularization term …
Which new features? This is domain dependent…
Kernelized CCA#
Given linear spaces of features \({\cal H}_X, {\cal H}_Y\) we might look at
If \({\cal H}_X\) and \({\cal H}_Y\) are RKHS, this is kernelized CCA.
A possible issue?#
For kernelized CCA \(\text{max}(\text{dim}({\cal H}_X), \text{dim}({\cal H}_Y)) > n\) the matrix
is degenerate so we can’t really form \(\widehat{\Sigma}_{f(X),f(X)}^{-1/2}\)…
Generic RKHS will always have this problem. How to resolve?
Regularized covariance estimate#
Let’s just assume that \({\cal H}_X\) is finite dimensional of dimension \(k > n\) and \({\cal H}_Y\) are just the usual linear functions.
We can then just work on the usual CCA with data matrices \(Y\) and \(W=f(X) \in \mathbb{R}^{n \times k}\).
A simple remedy is to consider instead
Will require SVD of \((\widehat{\Sigma}_{WW} + \epsilon I)^{-1/2} \widehat{\Sigma}_{WY} \widehat{\Sigma}_{YY}^{-1/2}\).
Kernelized version#
Instead of \(\widehat{\text{Var}}(f(X))\) could use
Even simpler (in theory): subsample the “knots” in the kernel (e.g. Snelson & Ghahramani (2005))
By usual kernel trick, this reduces problem to an \(n\) dimensional problem.
In this case, an eigenvalue problem for \(n \times n\) matrix…
Other covariance regularization#
(PMD) Witten et al. (pretends \(\Sigma_{WW}= \kappa I\))
NOCCO in Fukumizu et al. (uses the regularized covariance operator in RKHS)
Use row/column covariance Allen et al.
Each of these methods boils down to choosing two quadratic forms \(Q_X, Q_Y\)…
Other structure#
Restricting to finite dimensions, the first regularized problems morally look like (assuming \(X\) and \(Y\) have been centered)
It is often tempting to interpret loadings \((a,b)\) just as in PCA.
For such settings, it is often desirable to impose structure on \((a,b)\).
Sparse CCA and variants#
In bound form: $\( \text{maximize}_{(a,b): a^TQ_Xa \leq 1, b^TQ_Yb \leq 1, \|a\|_1 \leq c_X } a^TX^TYb \)$
In Lagrange form: $\( \text{maximize}_{(a,b): a^TQ_Xa \leq 1, b^TQ_Yb \leq 1} a^TX^TYb - \lambda_X \|a\|_1 \)$
Non-negative factors#
Relation to sparse PCA#
Corresponds to swapping \(X^TY\) with \(X\) …
A bi-convex problem#
The function \((a,b) \mapsto -a^TX^TYb\) is not convex.
Numeric feasibility of solving PCA rests on computability of SVD even though it is not a convex problem.
However, for \(b\) fixed, \(a \mapsto -a^TX^TYb\) is linear, hence convex.
Alternating algorithm: given feasibile initial \((\widehat{a}^{(0)}, \widehat{b}^{(0)})\) we iterate (for \(\ell_1\) bound form above):
Yields an ascent algorithm on objective \((a,b) \mapsto a^TX^TYb\)… often with pretty simple updates.
Deflation not completely obvious, but there are reasonable proposals
An example with a pretty picture: CGH#
# install.packages('PMA', repos='http://cloud.r-project.org')
# might need to install `impute` from BioConductor
library(PMA)
# http://web.stanford.edu/class/stats305c/data/breastdata.rda
load('~/Downloads/breastdata.rda')
attach(breastdata)
PlotCGH(dna[,1], chrom=chrom, main="Sample 1", nuc=nuc)
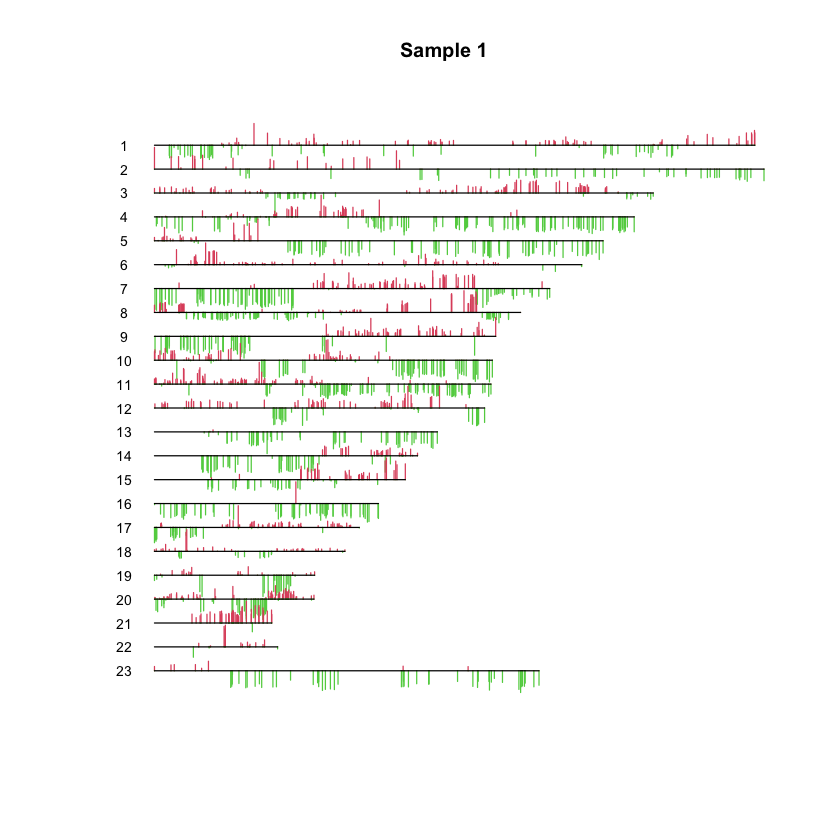
An example with a pretty picture: CGH#
Dataset
breastdatafromPMAhas both gene expression data (rna) and CGH measurements (dna) on 89 samples.Our example (which is in
PMApackage) will just use CGH from chromosome 1:t(dna)is a \(89 \times 136\) matrix and all oft(rna), an \(89 \times 19672\) matrix.CGH data is modeled as piecewise constant with a (sparse) fused LASSO penalty constraint $\( {\cal P}_{FL}(v) = \|v\|_1 + \alpha \|Dv\|_1 \leq c_v \)\( while gene expression is sparse \)\( {\cal P}_S(u) = \|u\|_1. \)$
Optimization problem: $\( \text{maximize}_{(u,v): \|u\|_2\leq 1, {\cal P}_S(u) \leq c_u, \|v\|_2 \leq 1, {\cal P}_{FL}(v) \leq c_v} u^TX^TYv \)$
Inevitably, one has to choose tuning parameters…
Authors propose permuting \(X\) and rerunning algorithm while retaining the value of the problem. Parameters are chosen to have smallest p-value.
#| echo: true
set.seed(22)
dna_t = t(dna)
rna_t = t(rna)
perm.out = CCA.permute(x=rna_t,
## Run CCA using all gene exp. data, but CGH data on chrom 1 only.
z=dna_t[,chrom==1],
typex="standard",
typez="ordered",
nperms=10,
penaltyxs=seq(.02,.7,len=10))
Warning message in CCA.permute(x = rna_t, z = dna_t[, chrom == 1], typex = "standard", :
“Since type of z is ordered, the penalty for z was chosen w/o permutations.”
Permutation 1 out of 10 12345678910
Permutation 2 out of 10 12345678910
Permutation 3 out of 10 12345678910
Permutation 4 out of 10 12345678910
Permutation 5 out of 10 12345678910
Permutation 6 out of 10 12345678910
Permutation 7 out of 10 12345678910
Permutation 8 out of 10 12345678910
Permutation 9 out of 10 12345678910
Permutation 10 out of 10 12345678910
#| echo: true
print(perm.out)
Call: CCA.permute(x = rna_t, z = dna_t[, chrom == 1], typex = "standard",
typez = "ordered", penaltyxs = seq(0.02, 0.7, len = 10),
nperms = 10)
Type of x: standard
Type of z: ordered
X Penalty Z Penalty Z-Stat P-Value Cors Cors Perm FT(Cors) FT(Cors Perm)
1 0.020 0.032 3.694 0.0 0.825 0.641 1.171 0.762
2 0.096 0.032 1.487 0.0 0.801 0.684 1.101 0.845
3 0.171 0.032 1.882 0.0 0.805 0.649 1.113 0.783
4 0.247 0.032 1.786 0.0 0.782 0.623 1.050 0.739
5 0.322 0.032 1.591 0.0 0.753 0.603 0.980 0.706
6 0.398 0.032 1.396 0.0 0.726 0.587 0.921 0.681
7 0.473 0.032 1.221 0.0 0.701 0.574 0.869 0.661
8 0.549 0.032 1.063 0.0 0.677 0.563 0.823 0.644
9 0.624 0.032 0.922 0.2 0.655 0.553 0.784 0.630
10 0.700 0.032 0.796 0.2 0.635 0.546 0.750 0.619
# U's Non-Zero # Vs Non-Zero
1 12 90
2 267 72
3 1189 71
4 2639 62
5 4329 62
6 6278 61
7 8399 61
8 10860 61
9 13536 61
10 16252 61
Best L1 bound for x: 0.02
Best lambda for z: 0.03178034
What is the \(Z\)-score?#
For each permutation, there is a realized value to the optimization problem for each value of the tuning parameter.
Can compute mean and SD over permutation data (for each value of the tuning parameter), yielding a reference distribution.
\(Z\)-score compares observed realized value to the permutation distribution.
Tuning parameter is chosen to maximize the \(Z\)-score.
#| echo: true
plot(perm.out)

#| echo: true
out = CCA(x=rna_t,
z=dna_t[,chrom==1],
typex="standard",
typez="ordered",
penaltyx=perm.out$bestpenaltyx,
v=perm.out$v.init,
penaltyz=perm.out$bestpenaltyz,
xnames=substr(genedesc,1,20),
znames=paste("Pos", sep="", nuc[chrom==1]))
print(out, verbose=FALSE) # could do print(out,verbose=TRUE)
123456789101112131415
Call: CCA(x = rna_t, z = dna_t[, chrom == 1], typex = "standard", typez = "ordered",
penaltyx = perm.out$bestpenaltyx, penaltyz = perm.out$bestpenaltyz,
v = perm.out$v.init, xnames = substr(genedesc, 1, 20), znames = paste("Pos",
sep = "", nuc[chrom == 1]))
Num non-zeros u's: 12
Num non-zeros v's: 90
Type of x: standard
Type of z: ordered
Penalty for x: L1 bound is 0.02
Penalty for z: Lambda is 0.03178034
Cor(Xu,Zv): 0.8247056
#| echo: true
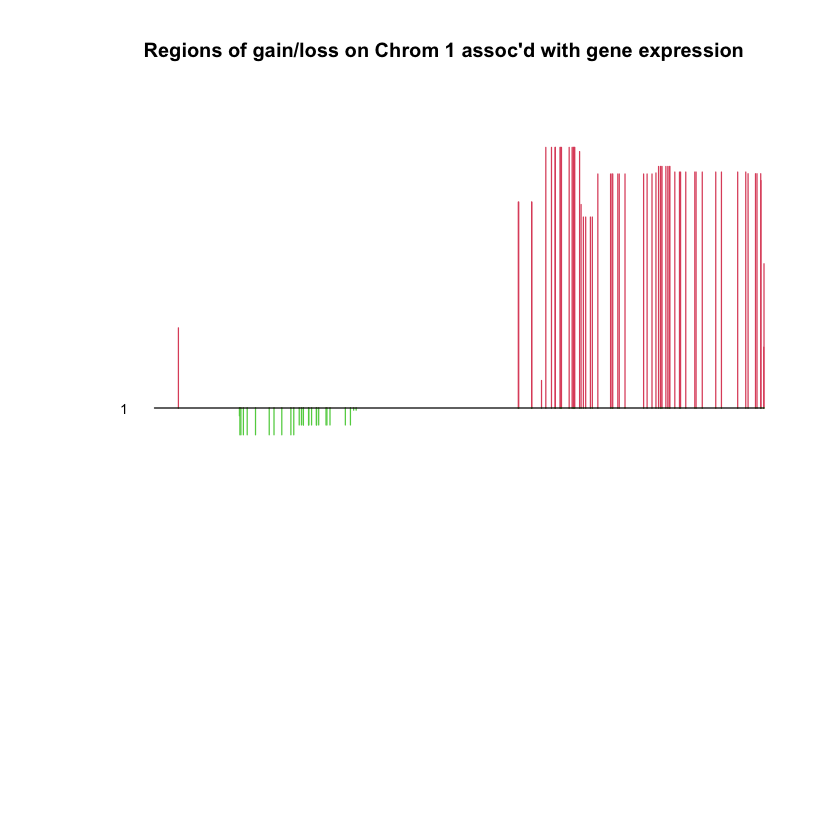
print(genechr[out$u!=0]) # which chromosome are the selected genes on
PlotCGH(out$v,
nuc=nuc[chrom==1],
chrom=chrom[chrom==1],
main="Regions of gain/loss on Chrom 1 assoc'd with gene expression")
[1] 1 1 1 1 1 1 1 1 1 1 1 1
Multiple CCA#
We had gene expression and CGH data on the same samples.
Can easily conceive of situations where we have yet another type of phenotype.
Given samples from \(X=(X_1, \dots, X_r) \sim F, X_i \in \mathbb{R}^{d_i}\) we can write its covariance as
with \(\Sigma_{ij} \in \mathbb{R}^{d_i \times d_j}\).
Forming linear combinations \(a_i^TX_i, a_j^TX_j\) yields
Pick your favorite functional \(\Phi\) of the off-diagonal blocks – try to maximize
subject to \(\text{Var}_F(a_i^TX_i)=1, 1 \leq i \leq r\).
Examples of \(\Phi\): sum of off-diagonals; max of off-diagonals…
Covariance can be regularized…
Can impose structure (sparsity, non-negativity, etc.)
Solving the problem? Certainly the sum of off-diagonals is multi-convex…
Cooperative learning#
The CCA problem is unsupervised (though is related to reduced rank regression…)
In supervised setting, we might have different views (qualitatively different types of data)
Genetic data
Different types of biological assay
Imaging data
Multi-view supervised#
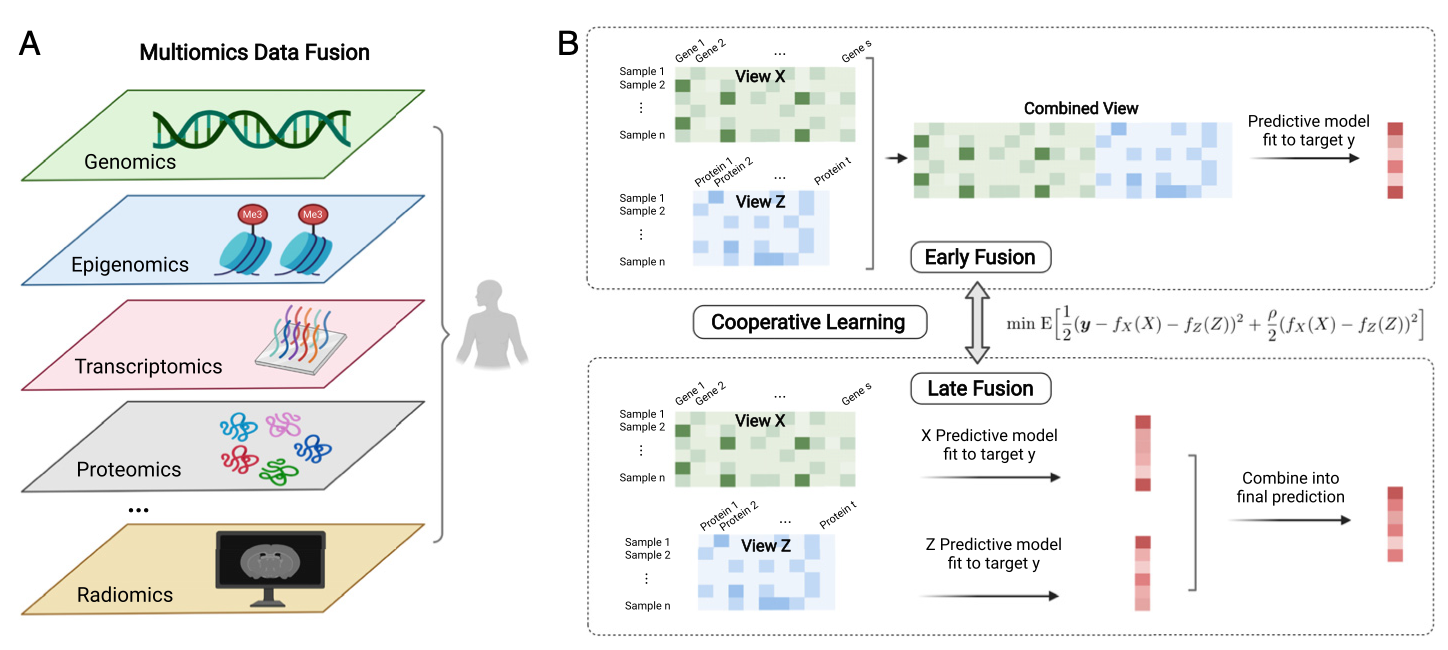
Multi-view objective: cooperative learning#
Underlying generative model (?)#
\(X\), \(Z\) as in the CCA generative model with common variation \(\check{Z}\)
\(Y | \check{Z}, X, Z \sim N(\alpha'\check{Z} + \beta'X + \gamma'Z, \sigma^2)\) with \(\beta\), \(\gamma\) simple
Supervised target shares some of the same latent variables as \(X\) and \(Z\)…