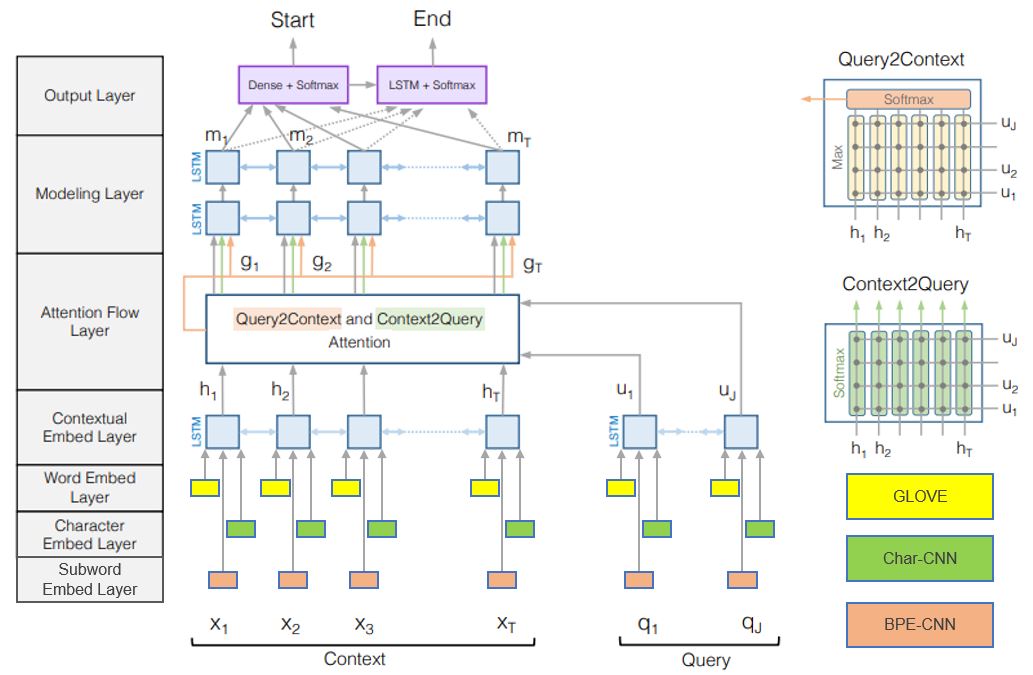
 Systems trained end-to-end have achieved promising results in question answering the past couple of years. Many of the deep-learning based question answering systems are trained and evaluated on the Stanford Question Answering Dataset (SQuAD), where the answer to every question is either unanswerable or a segment of text from the corresponding reading passage [4]. In this work, we investigate the effectiveness of different embeddings in improving the performance of the baseline Bi-Directional Attention Flow model on solving SQuAD 2.0. The first model improves upon the baseline with character-level embeddings; the second model improves with subword-level embeddings; the third improves with both character-level and subword-level embeddings. Our best model, which incorporates word-level and subword-level embeddings, achieves an EM score of 57.70 and F1 score of 61.26 on the test set.
Systems trained end-to-end have achieved promising results in question answering the past couple of years. Many of the deep-learning based question answering systems are trained and evaluated on the Stanford Question Answering Dataset (SQuAD), where the answer to every question is either unanswerable or a segment of text from the corresponding reading passage [4]. In this work, we investigate the effectiveness of different embeddings in improving the performance of the baseline Bi-Directional Attention Flow model on solving SQuAD 2.0. The first model improves upon the baseline with character-level embeddings; the second model improves with subword-level embeddings; the third improves with both character-level and subword-level embeddings. Our best model, which incorporates word-level and subword-level embeddings, achieves an EM score of 57.70 and F1 score of 61.26 on the test set.